
Looking for a specific paper or subject?
Stealing Part of a Production Language Model
What if we could discover OpenAI models internal weights? In this post we dive into a paper which presents an attack that steals LLMs data…
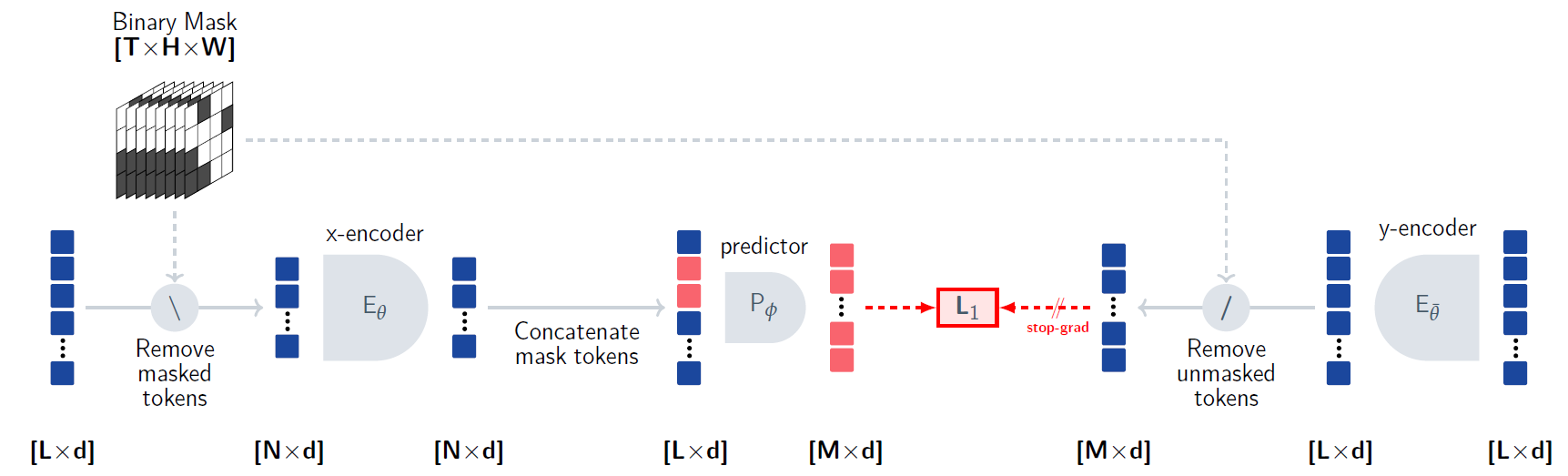
How Meta AI ‘s Human-Like V-JEPA Works?
Explore V-JEPA, which stands for Video Joint-Embedding Predicting Architecture. Another step in Meta AI’s journey for human-like AI…
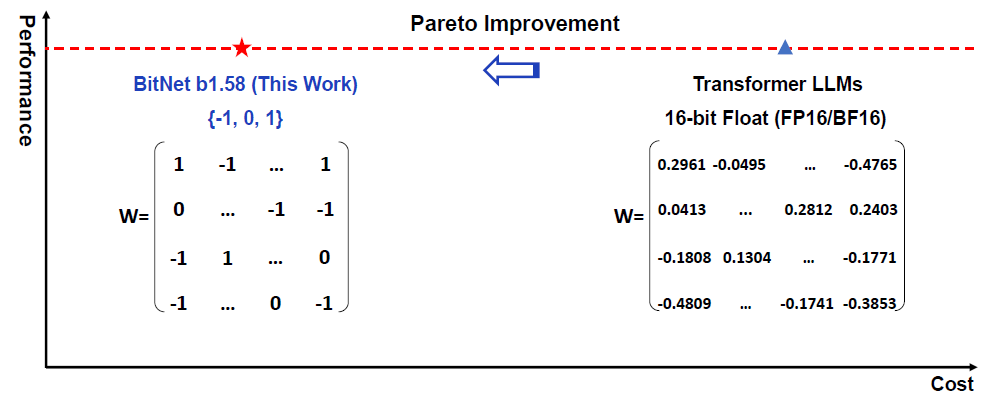
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
In this post we dive into the era of 1-bit LLMs paper by Microsoft, which shows a promising direction for low cost large language models…
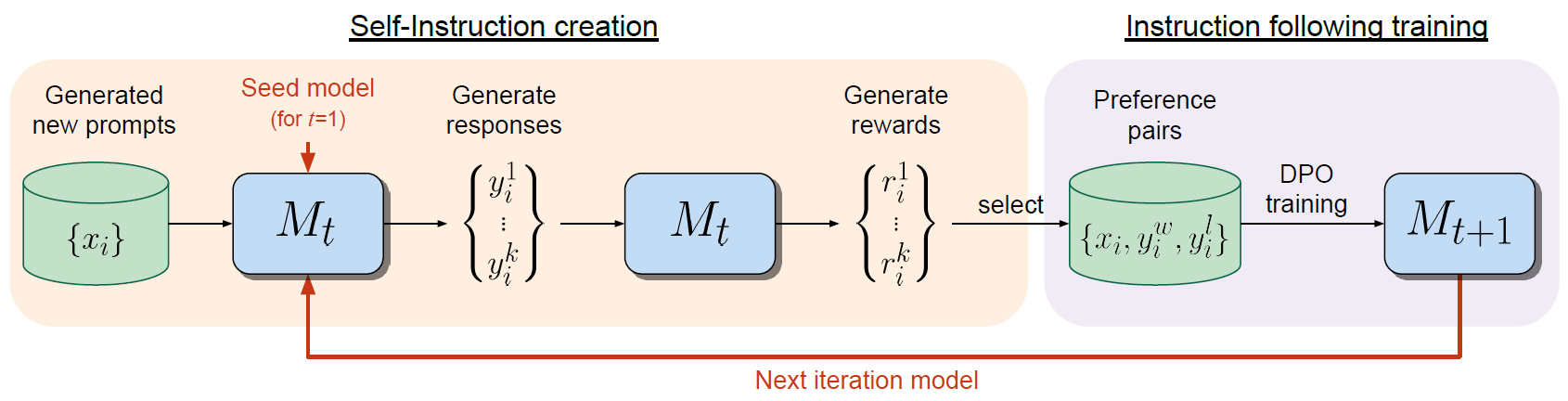
Self-Rewarding Language Models by Meta AI
In this post we dive into the Self-Rewarding Language Models paper by Meta AI, which can possibly be a step towards open-source AGI…

Fast Inference of Mixture-of-Experts Language Models with Offloading
Diving into a research paper introducing an innovative method to enhance LLM inference efficiency using memory offloading…
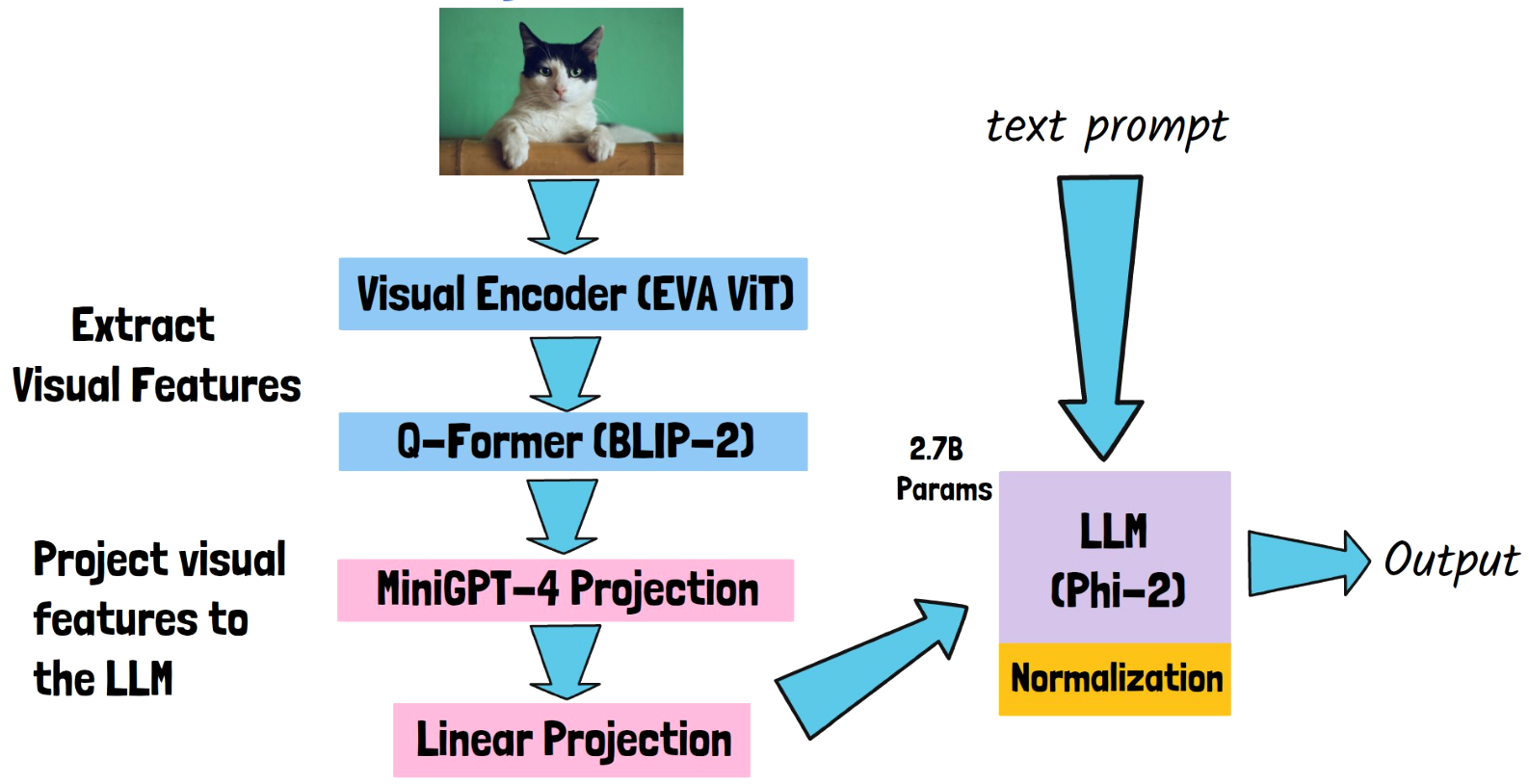
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
In this post we dive into TinyGPT-V, a small but mighty Multimodal LLM which brings Phi-2 success to vision-language tasks…

LLM in a flash: Efficient Large Language Model Inference with Limited Memory
In this post we dive into LLM in a flash paper by Apple, that introduces a method to run LLMs on devices that have limited memory…
Vision Transformers Explained | The ViT Paper
In this post we go back to the important vision transformers paper, to understand how ViT adapted transformers to computer vision…

Orca 2: Teaching Small Language Models How to Reason
Dive into Orca 2 research paper, the second version of the successful Orca small language model from Microsoft…
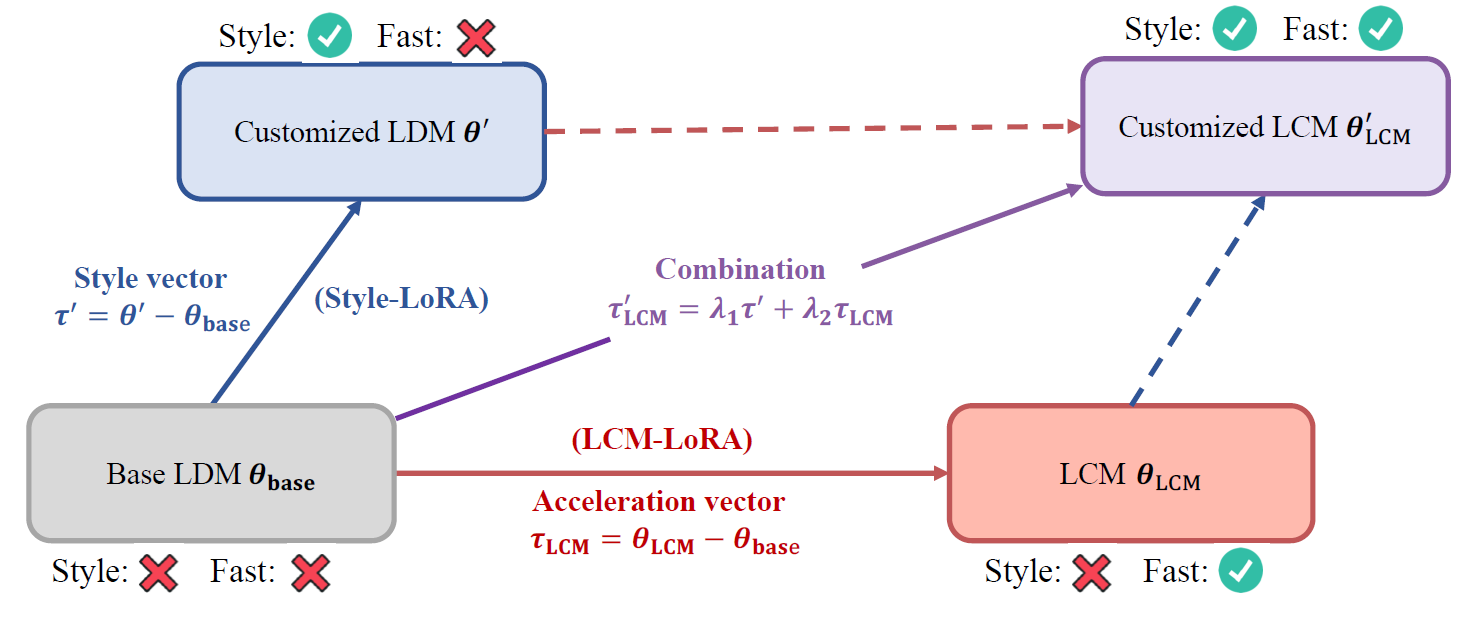
From Diffusion Models to LCM-LoRA
Following LCM-LoRA release, in this post we explore the evolution of diffusion models up to latent consistency models with LoRA…

CODEFUSION: A Pre-trained Diffusion Model for Code Generation
In this post we dive into Microsoft’s CODEFUSION, an approach to use diffusion models for code generation that achieves remarkable results…

Table-GPT: Empower LLMs To Understand Tables
In this post we dive into Table-GPT, a novel research by Microsoft, that empowers LLMs to understand tabular data…

Vision Transformers Need Registers – Fixing a Bug in DINOv2?
In this post we explain the paper “Vision Transformers Need Registers” by Meta AI, that explains an interesting behavior in DINOv2 features…

Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
In this post we dive into Emu, a text-to-image generation model by Meta AI, which is quality-tuned to generate highly aesthetic images…

NExT-GPT: Any-to-Any Multimodal LLM
In this post we dive into NExT-GPT, a multimodal large language model (MM-LLM), that can both understand and respond with multiple modalities…
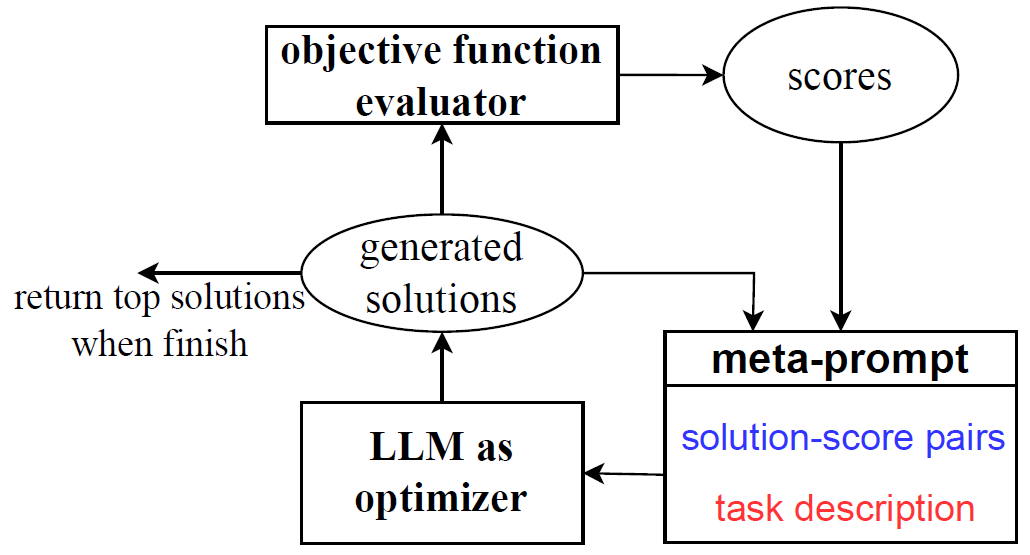
Large Language Models As Optimizers – OPRO by Google DeepMind
In this post we dive into the Large Language Models As Optimizers paper by Google DeepMind, which introduces OPRO (Optimization by PROmpting)…
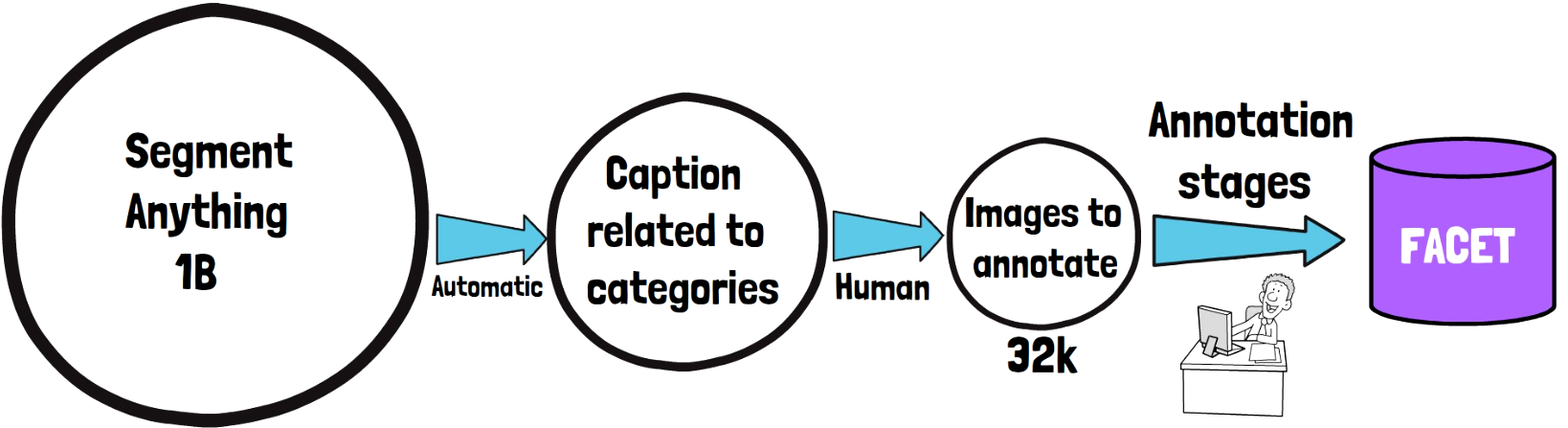
FACET: Fairness in Computer Vision Evaluation Benchmark
In this post we cover FACET, a new dataset created by Meta AI in order to evaluate a benchmark for fairness of computer vision models…

Code Llama Paper Explained
Discover an in-depth review of Code Llama paper, a specialized version of the Llama 2 model designed for coding tasks…