
OPRO (Optimization by PROmpting), is a new approach to leverage large language models as optimizers, which was introduced by Google DeepMind in a research paper titled “Large Language Models As Optimizers”.

Large language models are very good at getting a prompt, such as an instruction or a question, and yield a useful response that match to the input prompt.
By extending the prompt with a carefully human crafted addition of an instruction, such as “let’s think step by step”, large language models have been shown to yield better responses. However, manually crafting the prompt can be tedious. So here comes OPRO, which can provide an extension to improve the prompt automatically. But not only that, the large language model will now yield even better responses. In this post, we will explain how this method works and explore some of the results presented in the paper.
If you prefer a video format then check out our video that covers a lot of what we cover here:
Prompt Optimization with OPRO
Let’s jump into it and see and how the OPRO framework works. The goal of this process is to maximize the accuracy over a dataset with prompts and responses, such as the GSM8K dataset which is one of the datasets used in the paper, which contains word math problems. And the way OPRO will do that is by yielding an instruction, that will be added to the prompts in the dataset, to yield better responses, such as “let’s think step by step” or “break it down” that we will add before the original prompt.
So, how does it work?
OPRO Overview For Prompt Optimization

In the image above, we have a large language model we call the Optimizer LLM, and we feed it with a prompt which we call meta-prompt. We will soon see how the meta-prompt is structured, but in the meanwhile just note that the meta-prompt instructs the optimizer LLM to yield few instructions, in the paper they use 8 instructions, that will improve example prompts from the dataset.
The optimizer LLM then yields 8 candidate instructions, which we feed into another LLM which is called the Scorer LLM. The scorer LLM can be the same LLM as the optimizer LLM or a different one. We then evaluate the accuracy of the scorer LLM over the training set 8 times, each time we add different candidate instruction to the prompts. We then get 8 accuracy scores, which we add back to the meta-prompt, together with the candidate instructions, in order to go via this process again.
When the process is stopped, for example if we do not observe any improvement in the accuracy anymore, then we end with the optimized instruction as the instruction which achieved the best accuracy on the training set. It is worth to mention that when evaluating the accuracy on the training set, in practice it is sufficient to use a relatively small portion of the training set.
Meta-prompt Structure
To understand how the meta-prompt is constructed, let’s review the following example from the paper for a meta-prompt.

The sentences in orange are meta-instructions, that guide the optimizer LLM how to use the information in the meta-prompt. In the first sentence we see that the meta-instruction tells the model how to interpret the pairs of instructions and scores, which are also part of the meta-prompt, and we can see them in blue color. Due to context size limit consideration, the researchers include the top 20 instruction-score pairs which were encountered during the OPRO process.
Then, we have another meta-instruction that guides the optimizer LLM about the task it should solve, by saying that there are examples for the questions and answers below, and how the instruction it generates will be used, as we see with the token. Then, in purple, we have examples for task and output which are randomized from the training set. In the experiments from the paper, the researchers use 3 examples. Finally, there is another meta-instruction that tells the LLM to generate a new instruction which is different than the previous ones that are given in the meta-prompt in blue, and that it should yield a better score.
OPRO Framework Overview – Large Language Models As Optimizers
Ok, until now we’ve shown how the OPRO approach works for optimization of prompts, but the OPRO framework is more generic than that and can be applied for various optimization problems. In the following image from the paper, we can see an overview of the OPRO framework, which is similar to what we saw for prompt optimization but let’s review it to see where it can change for other optimization problems.
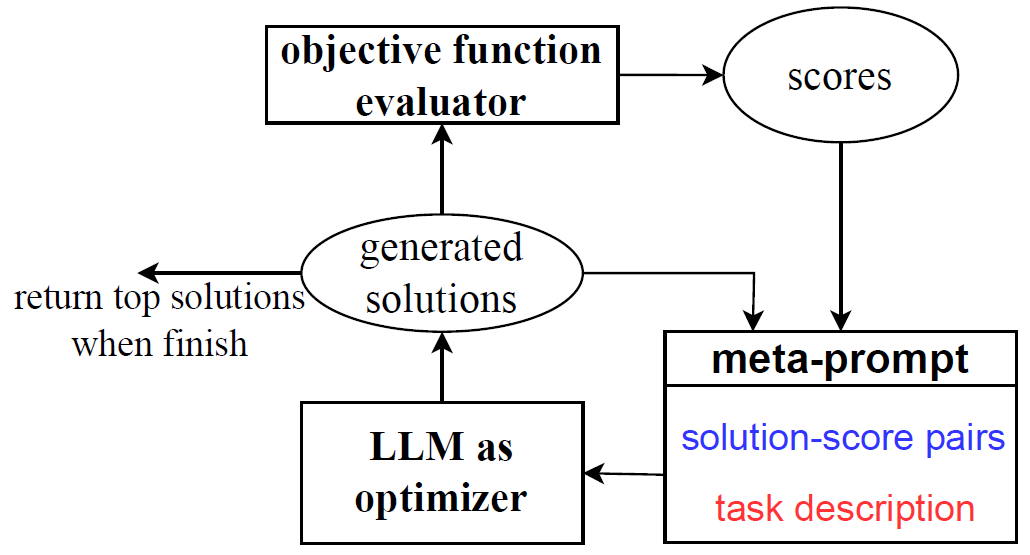
On the bottom right we have a meta-prompt, similar to the meta-prompt we saw earlier, just if we would want to solve a different optimization problem, then the meta-prompt will be different. Also, if we would want to solve the same optimization problem but with a different LLM as optimizer, the meta-prompt should likely be different as well. As we saw before, the meta-prompt is fed into the optimizer LLM, which should yield solutions as instructed by the meta-prompt.
Before, we saw that the generated solutions or instructions were fed to the scorer LLM. The scorer LLM is a type of objective function evaluator, which can change depending on the optimization task we want to solve. The objective function evaluator then yields scores, that are then added to the meta-prompt for the next iteration of the OPRO framework. Finally, when we finish the process, we return the top solutions as the result.
Earlier we saw how to apply this framework on prompt optimization. In addition, in the paper the researchers show how they use OPRO to solve linear regression and traveling salesman optimization problems, which we won’t dive into in this post.
Results
Comparison of human-designed prompts with different LLM optimizers
Let’s now move on to review some of the results presented in the paper, starting with a comparison of human-designed prompts with different LLM optimizers. In the following table from the paper, each row represents the accuracy of the PALM 2-L model on GSM8K test set, each time with a different instruction to empower the prompt. As baselines, we see human-designed prompts, and below we see the prompts crafted by OPRO, where on each row a different model was used as the LLM optimizer. And we see that the accuracies for the OPRO optimized prompts outperform the human-designed prompts with a noticeable margin, where the best one is telling the LLM to take a deep breath.

Prompt optimization curves
Additional interesting results from the paper that show the effectiveness of the OPRO framework are the prompt optimization curves on GSM8K and BBH, which we see in the following charts. The x axis represents the number of OPRO iterations and the y axis is the training accuracy evaluated by the scorer LLM, and it shows that the accuracy is increased when we make progress with the iterations.

References
- Video – https://youtu.be/KKpTevFJpJw
- Large Language Models As Optimizers Paper – https://arxiv.org/abs/2309.03409
- We use ChatPDF to help us analyze research papers – https://www.chatpdf.com/?via=ai-papers (affiliate)
All credit for the research goes to the researchers who wrote the paper we covered in this post.
Another recommended read for a paper from Google, that could significantly impacts LLMs is about Soft Mixture of Experts – https://aipapersacademy.com/from-sparse-to-soft-mixture-of-experts/