Motivation – LLMs Reasoning On Tabular Data

Nowadays, we are witnessing a tremendous progress with large language models (LLMs) such as ChatGPT, Llama and more, where we can feed a LLM with a text instruction or question, and most of the times get an accurate response from the model. However, if we’ll try to feed the model with a table data, in some kind of text format, and a question on that table, the LLM is more likely to yield inaccurate response (more on this in a minute).
Introducing Table-GPT

In this post we dive into a research paper published by Microsoft, titled “Table-GPT: Table-tuned GPT for Diverse Table Tasks”, where the researchers introduce Table-GPT, a GPT model which targets that problem and can better understand tables in the input and yield accurate response. We’ll explain the paper to understand how Table-GPT was created, and how it performs comparing to other large language models.

Can Current LLMs Understand Tables?
Let’s start with the question whether current large language models can understand tables, which the researchers have investigated. An important observation is that large language models are mostly pre-trained on natural language text from the web or from books, and code. Tabular data is different than natural language text and code, and so LLMs may not be able to reliably read tables. One main difference is that text and code are one dimensional and tables are two dimensional. With tables, it is important to be able to read vertically in order to be able to answer some type of questions.
Examples for Table Tasks
Missing-value Identification

In the above example from the paper, we can see an instruction to find the row and column where a value is missing from the table. We can see the value is missing in row 2 for the column “art”, yet the tested language model is able to get the row right, but is wrong with the column. Such example implies that the model is better at reasoning horizontally rather than vertically. And really, when evaluated ChatGPT on 1000 samples, ChatGPT provided the correct row number 92.3% of the times and the correct column only 42.2% of the times. The researchers refer to this task as missing-value identification.
Column-finding

Another example for a different task, which we can see above, is column finding, where here the instruction is to find which column has a certain value, 93 in this example. Here again the response “art” is inaccurate as it should be “music”. ChatGPT was able to get the correct column for this task 69.9% of the times.
Table Question Answering

A more complex task is table question answering, where we ask a question which is based on the table. In this example, how many second-graders scored over 90 in art, and we can see that the model replied with 2, while Jennifer scored 94 and James’s score is missing, so the answer should be 1. ChatGPT provided the correct results for this task only 51.2% of the times.
Data Imputation

Last example for a task is data imputation, where we ask the model to fill a cell where there is a placeholder [TO-FILL] token. In this example the model was able to correctly return the matching continent for China. However, in this case as well, the zero-shot result of ChatGPT is only 52.4%.
Table-tuning

So how the researchers were able to create a model that is doing better on such table tasks? The answer is a new approach they refer to as table-tuning. This approach is inspired from instruction-tuning which proved to be successful for large language models.
LLM Training Process Reminder
As a short reminder for what is instruction-tuning, large language models are first pre-trained on huge amount of text to learn general purpose knowledge. This step helps the LLM to be good at predicting the next token in a sequence, so for example given an input such as “write a bed-time _”, the LLM would be able to complete it with a reasonable word, such as “story”. However, after the pre-training stage the model is still not good at following human instructions. For this reason, we have the instruction-tuning step, where we fine-tune the model on an instructions dataset, where each sample from that dataset is a tuple of instruction and a response, which we use as the label. After this step, the model is good at following instructions. We ignore reinforcement learning here for simplicity.
Adding Table-tuning To The Training Process
Table-tuning is another step that can run either on the pre-trained LLM or on the instruction-tuned LLM, where we fine-tune the model on a table instructions dataset. Here, each sample in the dataset is a triplet with an instruction, a table, and a response, similar to the examples that we saw earlier. We’ll soon dive into the creation of the tables dataset., but first we note that after this step, the model is tuned to understand tables properly. We can take another look at this with the following figure from the paper.

On the left side we can see instruction-tuning, where base large language models are trained over tuples of instruction and response, called completion here, in order to create chat expert language models such as ChatGPT. And on the right, we can see table-tuning, where either base large language model as GPT, or an instruction-tuned model such as ChatGPT, are further trained using triplets of instruction, table and response, in order to create a table-tuned version of the models.
Creating the Table-GPT Dataset: Synthesis-then-Augment
Let’s now dive deeper into how the dataset used for table-tuning was created. The researchers refer to their method of creating that dataset as synthesis-then-augment. We first note that there is a limited diversity of existing labeled data available. So, the goal is to create a diverse large enough set of labeled data, but without expensive human labeling. We start with a large set of real tables, without instructions or labels, where 2.9 million tables are taken from Wikipedia and 188k more are database tables.
The Synthesis Stage

The first step is synthesis, which results in a dataset of labeled tables instructions. In each synthesis step, we sample a real table, and a task from a set of supported tasks, and create a new sample of (instruction, table, response). The table in the generated sample is not necessarily identical to the input table.
Data Imputation Task
In the following example which we already saw earlier, we sample the data imputation task, where the model needs to fill a missing value. We sample a table and randomly replace one cell with the [TO-FILL] token, and we use the original cell value as the label. Regarding the instruction, they can be manually crafted and reused for other samples of the same task, with different tables.
Column-finding Task
Another example that we saw earlier is column finding, where we ask to determine which column contains a certain value. For a sampled table, it is possible to detect a value which just appears once in the table and automatically generate the instruction to look for that value, in this case “93”. And we use the value’s column as the label, in this case “music”.
Additional Tasks
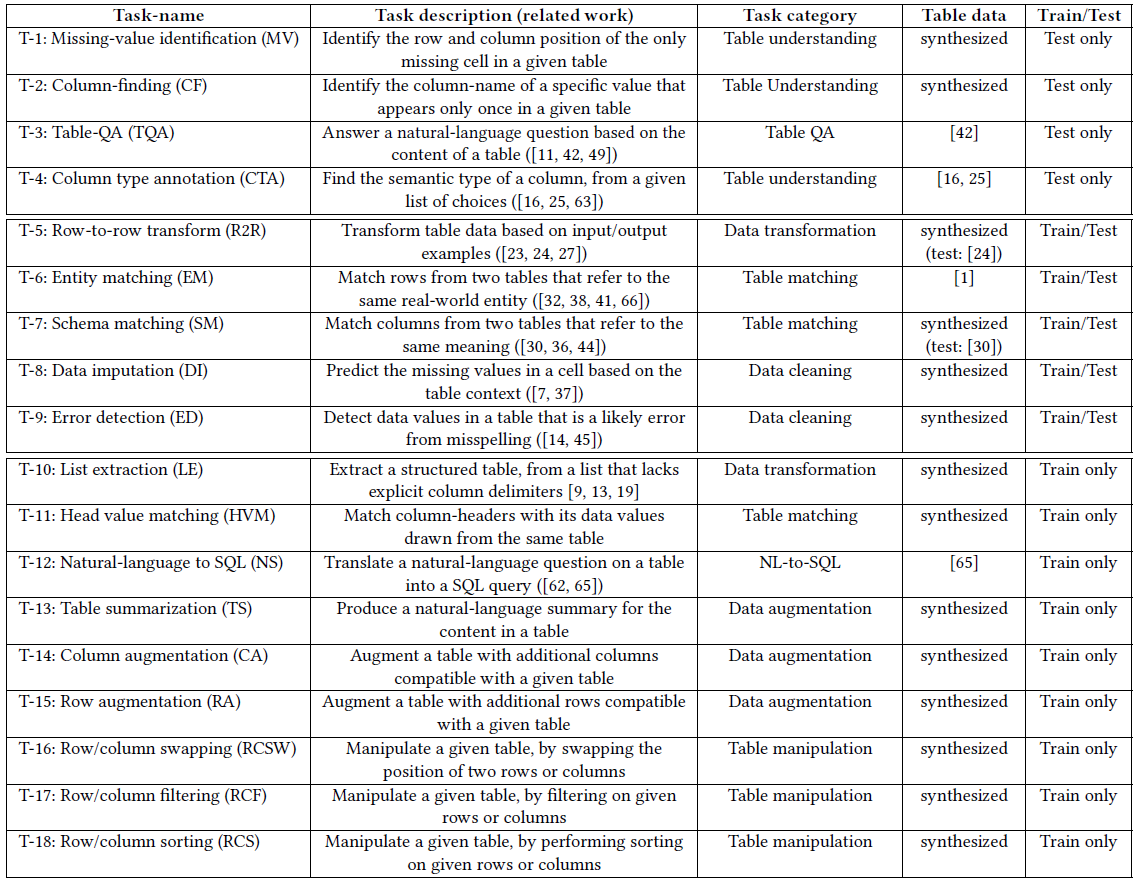
There are various more tasks that the researchers have synthesized data for. On example is error detection, where a typo is injected automatically to a random cell, and the original cell value is used as the label. Another one is table summarization, where a title from a Wikipedia table is used as the label. And various more. We see a summary of the different tasks in the following table from the paper. Some tasks are used for training only, some are used for training and test and some are used only in test time. Additionally, we see that the data for most tasks is synthesized. For a few complex tasks, a previous research data is used (the ones with number references in the table data column).
The Augmentation Stage
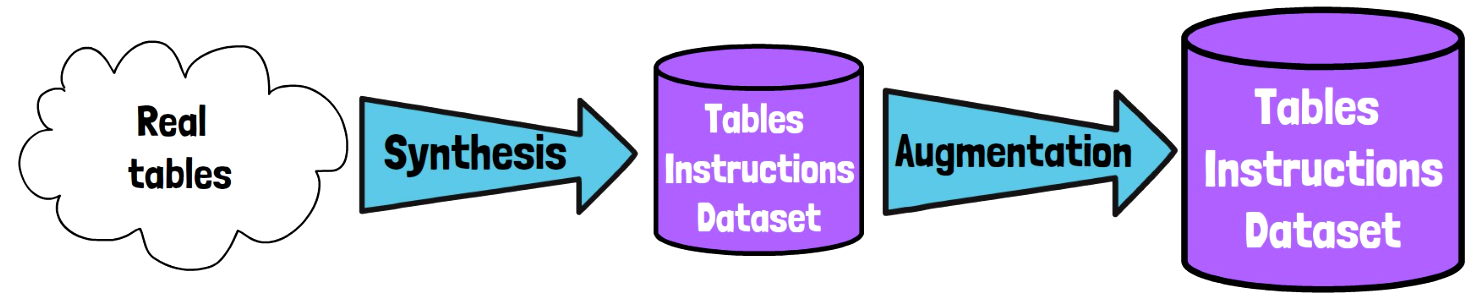
So, after the synthesis step, we already have a diverse tables instructions dataset, but to create even more diverse dataset, we have the second step, which is augmentation. There are three types of augmentations used here.
- Instruction-level Augmentation – We mentioned earlier that the instructions are shared between different instances of the same task. For example, if we ask the model to summarize a table, the instruction can stay the same for different tables. To avoid overfitting and to create more diverse samples, the researchers use LLMs to paraphrase the manually crafted instructions.
- Table-level Augmentation – Here we create more samples by changing the table itself, but without changing the table semantic meaning. We do that by re-ordering columns or rows, which should mainly not impact the table semantics.
- Label-level \ Response-level Augmentation – Here we create additional samples by providing a LLM with the correct answer and ask it to add reasoning for the answer.
Table-GPT Results
We’re now ready to review some of the results presented in the paper.
ChatGPT vs Table-tuned ChatGPT

In the above figure, we see the results for 8 tasks types, where for each task we have 4 bars.
- The left two bars in each task are zero-shot results – the prompt consists of instruction and a table.
- The right two bars are few-shot – The prompt includes few examples in addition to the target instruction and table.
The green bars are ChatGPT and the orange bars are the table-tuned version. We can clearly see improvement for most of the tasks with table-tuning. Noticeably, Table-GPT significantly outperforms ChatGPT in error detection in a zero-shot setting. Interestingly, the 4 charts at the bottom are for tasks which the table-tuned model did not train on, yet it is still able to improve the performance on top of ChatGPT.
GPT 3.5 vs Table-GPT (Table-tuned GPT 3.5)
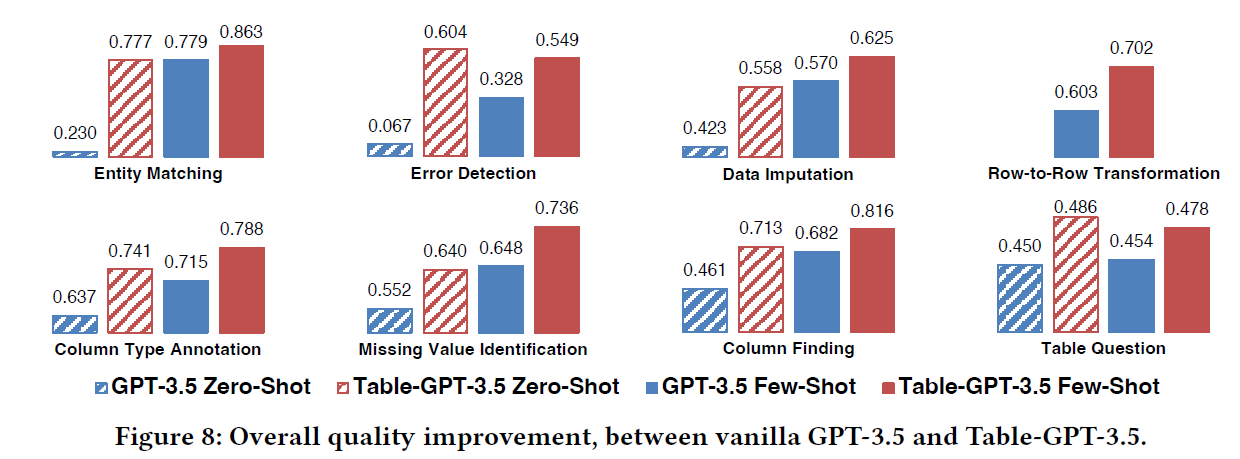
In the above figure, we see a similar trend. This time GPT 3.5 in blue and Table-GPT in red. Similarly, Table-GPT achieves better performance. Additionally, the bottom charts show that Table-GPT generalizes well for unseen tasks.
References & Links
- Paper page – https://arxiv.org/abs/2310.09263
- Video – https://youtu.be/yGL0XZlGA0I
- Join our newsletter to receive concise 1-minute read summaries for the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.