
Looking for a specific paper or subject?

SWE-RL by Meta — Reinforcement Learning for Software Engineering LLMs
Dive into SWE-RL by Meta, a DeepSeek-R1 style recipe for training LLMs for software engineering with reinforcement learning…

Large Language Diffusion Models: The Era Of Diffusion LLMs?
Discover Large Language Diffusion Models (LLaDA), a novel diffusion based approach to language modeling that challenges traditional LLMs…

CoCoMix by Meta AI – The Future of LLMs Pretraining?
Discover CoCoMix by Meta AI – a new approach for LLM pretraining using Continuous Concept Mixing, enriching word tokens with latent concepts!…

s1: Simple Test-Time Scaling – Can 1k Samples Rival o1-Preview?
Discover s1: a simple yet powerful approach to test-time scaling for LLMs, rivaling o1-preivew with just 1k samples!…

DeepSeek Janus Pro Paper Explained – Multimodal AI Revolution?
Dive into DeepSeek Janus Pro, another magnificent open-source release, this time a multimodal AI model that rivals top multimodal models!…

DeepSeek-R1 Paper Explained – A New RL LLMs Era in AI?
Dive into the groundbreaking DeepSeek-R1 research paper, introduces open-source reasoning models that rivals the performance OpenAI’s o1!…

Titans by Google: The Era of AI After Transformers?
Dive into Titans, a new AI architecture by Google, showing promising results comparing to Transformers! Paving the way for a new era in AI?…

rStar-Math by Microsoft: Can SLMs Beat OpenAI o1 in Math?
Discover how System 2 thinking through Monte Carlo Tree Search enables rStar-Math to rival OpenAI’s o1 in math, using Small Language Models!…
Large Concept Models (LCMs) by Meta: The Era of AI After LLMs?
Explore Meta’s Large Concept Models (LCMs) - an AI model that processes concepts instead of tokens. Can it become the next LLM architecture?…
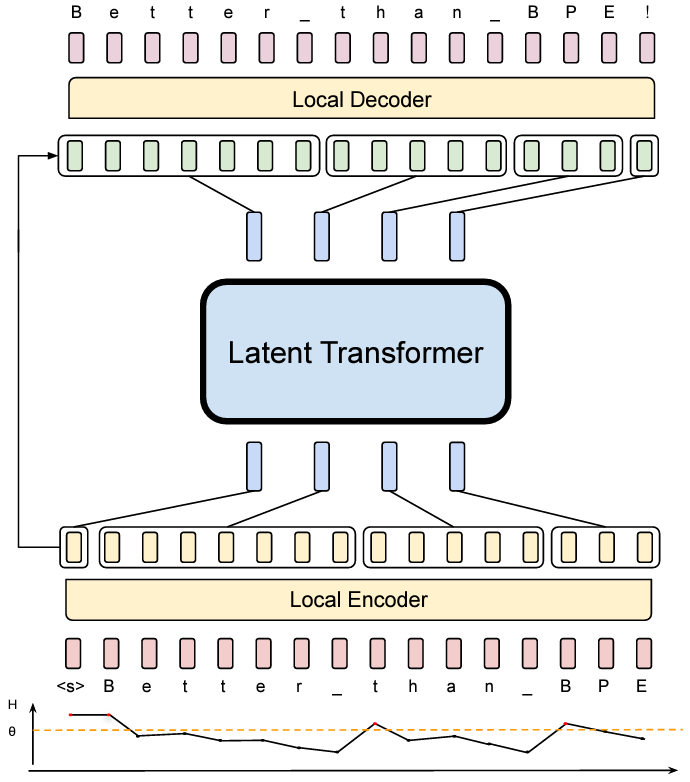
Byte Latent Transformer (BLT) by Meta AI: A Tokenizer-free LLM Revolution
Explore Byte Latent Transformer (BLT) by Meta AI: A tokenizer-free LLM that scales better than tokenization-based LLMs…

Coconut by Meta AI – Better LLM Reasoning With Chain of CONTINUOUS Thought?
Discover how Meta AI’s Chain of Continuous Thought (Coconut) empowers large language models (LLMs) to reason in their own language…
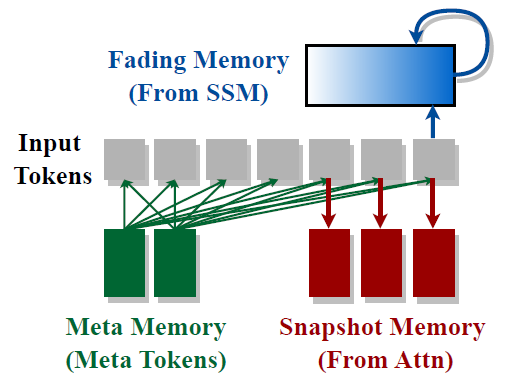
Hymba by NVIDIA: A Hybrid Mamba-Transformer Language Model
Discover NVIDIA’s Hymba model that combines Transformers and State Space Models for state-of-the-art performance in small language models…
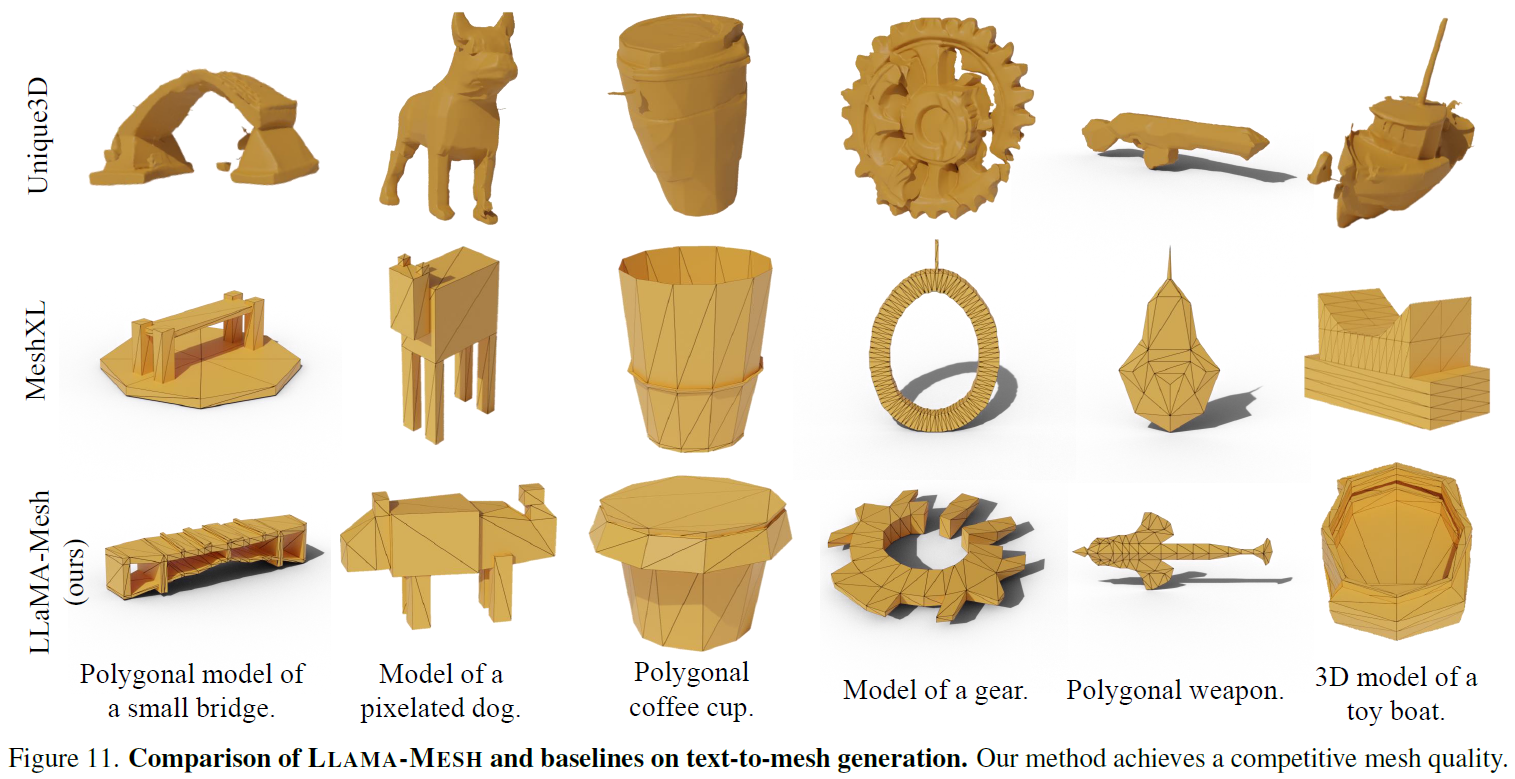
LLaMA-Mesh by Nvidia: LLM for 3D Mesh Generation
Dive into Nvidia’s LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models, a LLM which was adapted to understand 3D objects…
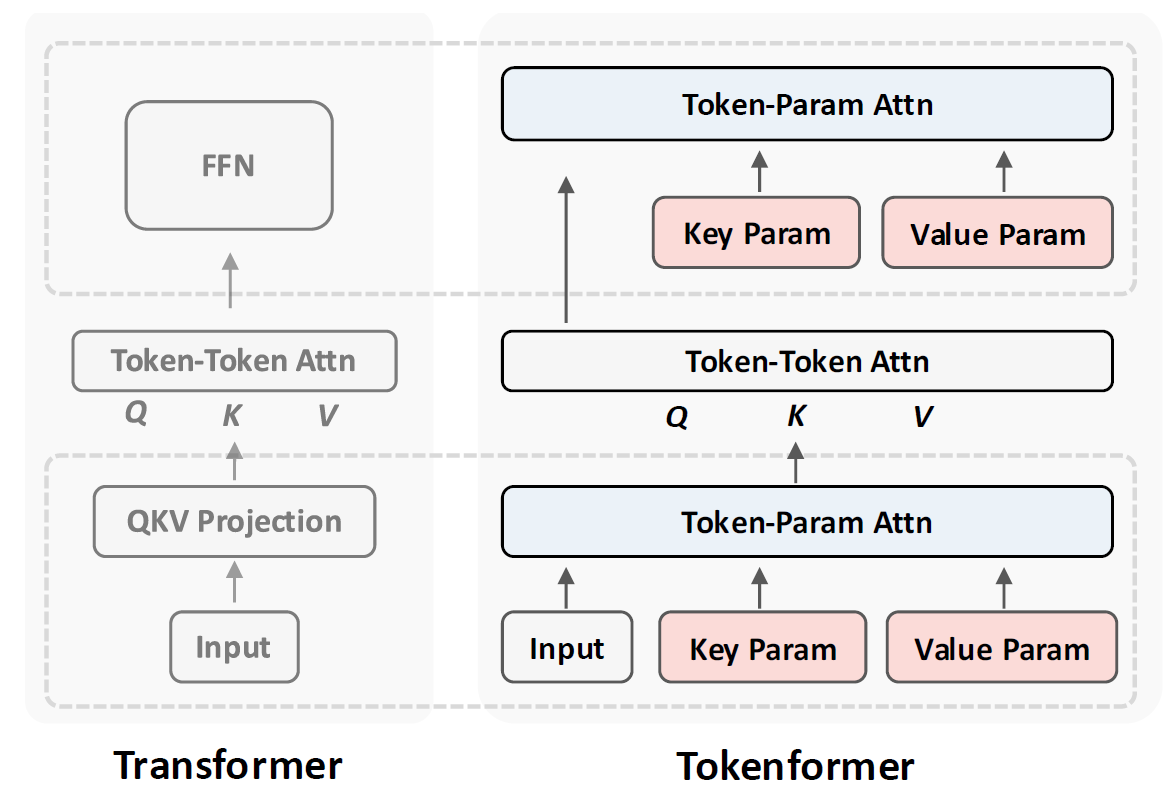
Tokenformer: Rethinking Transformer Scaling with Tokenized Model Parameters
Dive into Tokenformer, a novel architecture that improves Transformers to support incremental model growth without training from scratch…
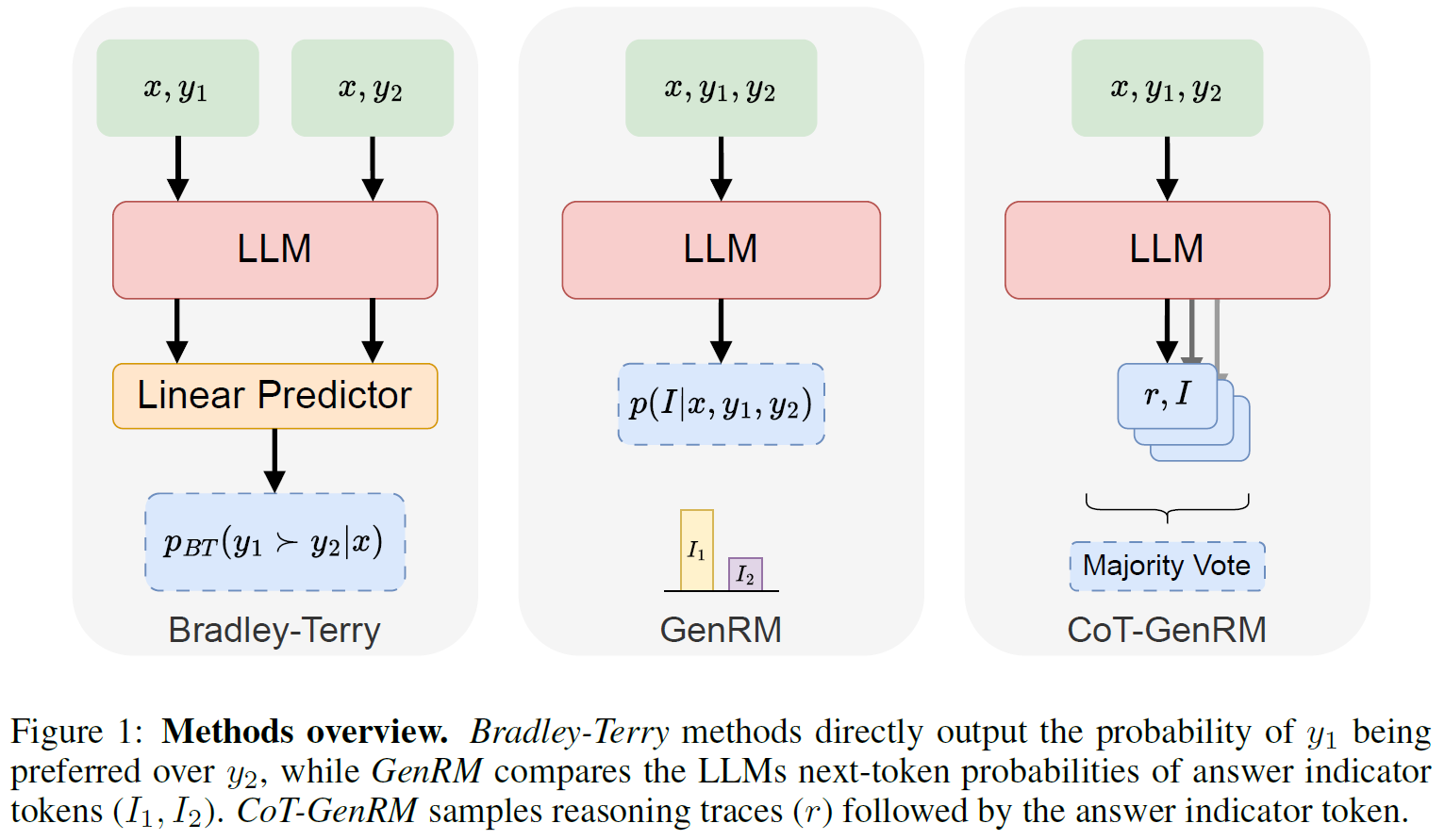
Generative Reward Models: Merging the Power of RLHF and RLAIF for Smarter AI
In this post we dive into a Stanford research presenting Generative Reward Models, a hybrid Human and AI RL to improve LLMs…

Sapiens by Meta AI: Foundation for Human Vision Models
In this post we dive into Sapiens, a new family of computer vision models by Meta AI that show remarkable advancement in human-centric tasks!…
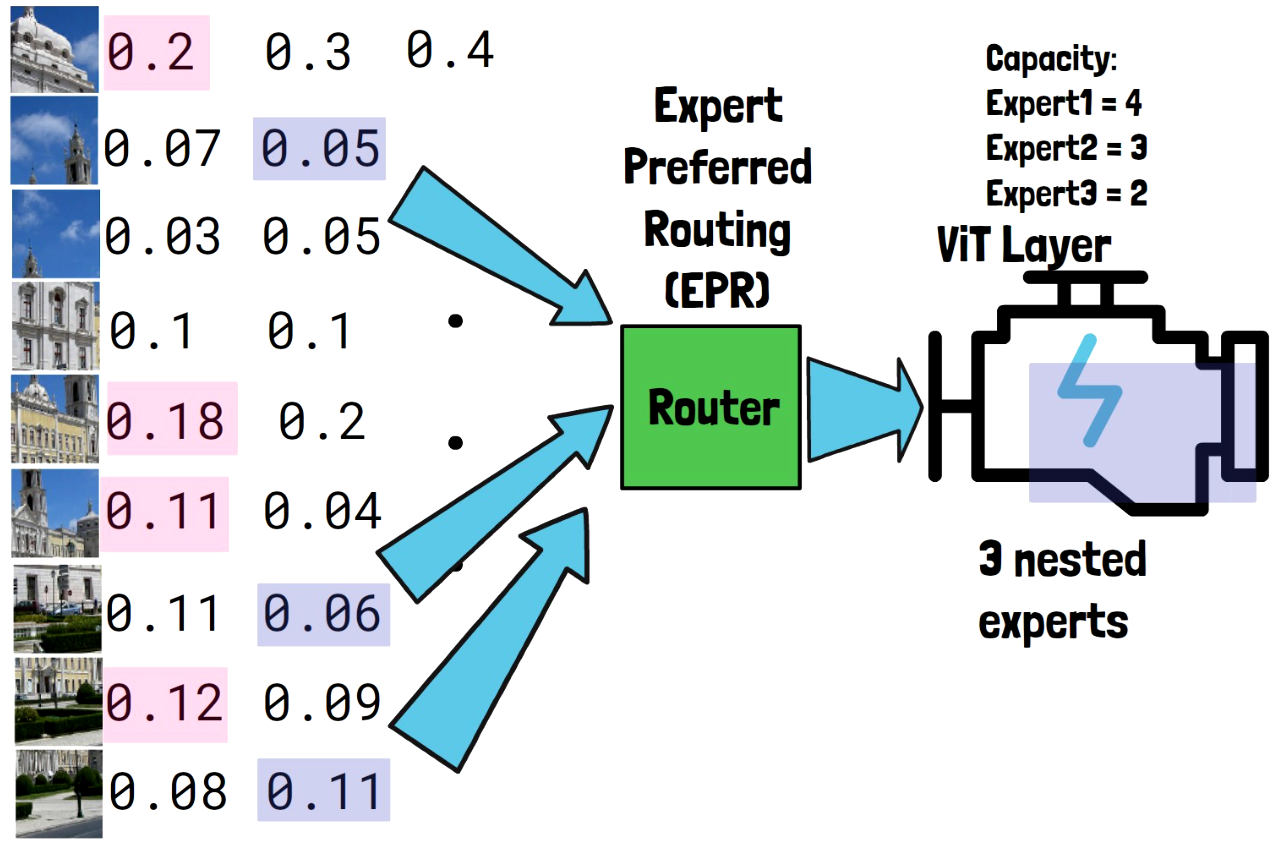
Mixture of Nested Experts: Adaptive Processing of Visual Tokens
In this post we dive into Mixture of Nested Experts, a new method presented by Google that can dramatically reduce AI computational cost…
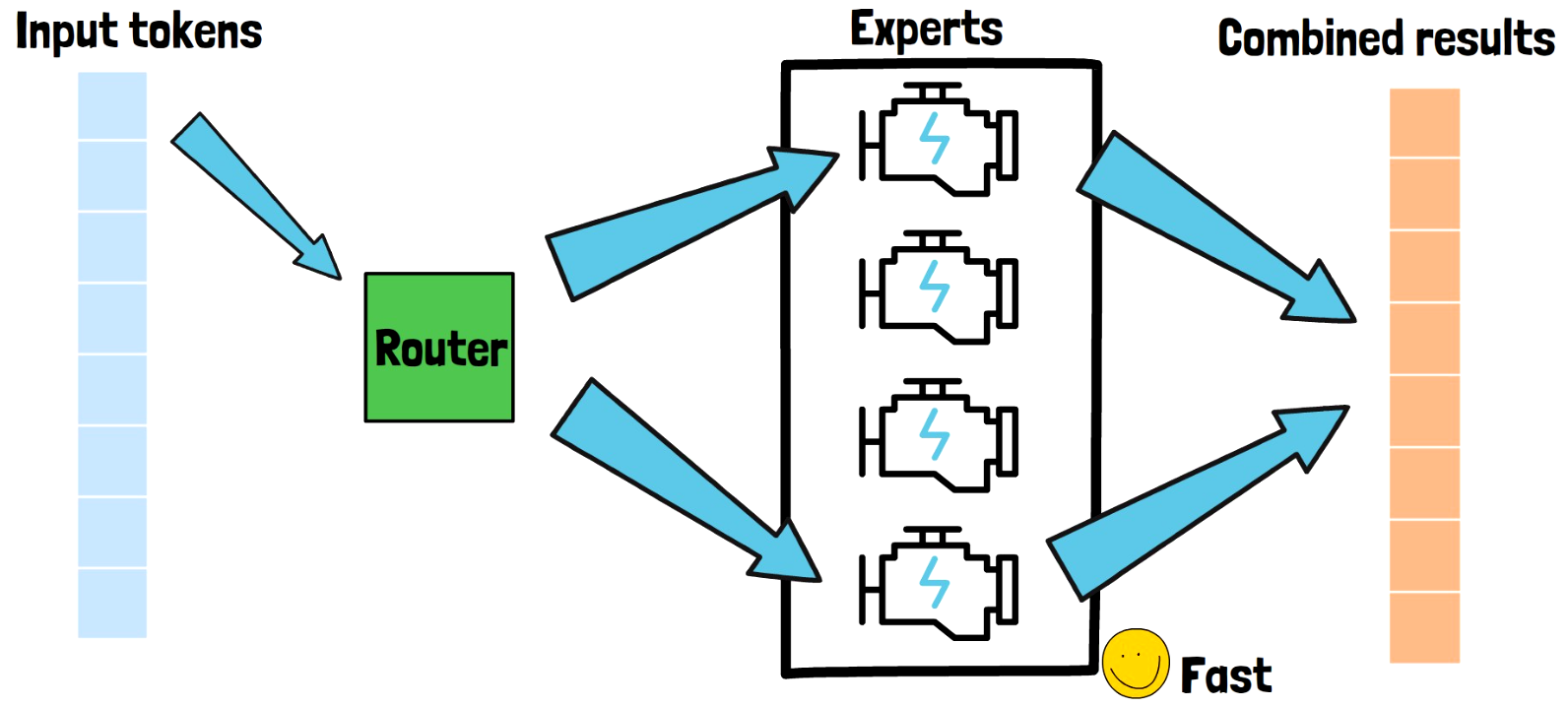
Introduction to Mixture-of-Experts | Original MoE Paper Explained
Diving into the original Google paper which introduced the Mixture-of-Experts (MoE) method, which was critical to AI progress…