
Emu is a new text-to-image generation model by Meta AI, which was presented in a research paper titled “Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack”. Text-to-image models are able to get a prompt as input, such as “a cat trying to catch a fish” in the example image above, and yield a high-quality image in response that match the input prompt properly, as we can see in the upper right in the image above. In such a case, we are happy with the result. However, it is not always easy to get high-quality results from these models consistently. In the bottom right illustration in the image above for example, we can subjectively say that the generated output is less visually appealing. So here comes Emu, a text-to-image model which is quality-tuned to yield high quality results consistently. In this post we will explain this research paper to understand how Emu was created.

If you prefer a video format, then check out our video:
Emu Output Examples
Let’s first quickly look at several examples of images generated by Emu. In the following figure from the paper we can see six images generated by Emu and their prompts at the bottom. These images exemplify the highly aesthetic generation capability of Emu.

Here are few more selected examples. Again, we can see amazing details here.

And finally, a last set of selected examples that includes an emu that was generated by the emu model which we can see on the right. Alright, let’s now dive into how Emu was created.

How Emu Was Created

Emu was created in two stages, the first is called the knowledge learning stage, or pre-training stage. In this stage, we take a latent diffusion model and train it on a large Meta internal dataset of 1.1 billion images. By the end of this step, the model is capable of generating images for diverse domains and styles, including highly aesthetic images. However, the generation process is not properly guided to always generate highly aesthetic images and so it may not be consistent when trying to do so.
For this reason, we have the second stage which is called quality-tuning. In this stage, we already have a pre-trained latent diffusion model, and we fine-tune the pre-trained model on another dataset of high-quality images. By the end of this step the model is now named Emu, and the model is now strong in generating highly aesthetic images consistently such as the examples we just saw, and we’ll soon review some of the results published in the paper that show this.
Curating High Quality Images for Quality-Tuning

What’s special in creating Emu is that the quality-tuning dataset is very small as it only contains few thousand images. These images are carefully curated to be extremely visually appealing. The curation pipeline starts with a set of billions of images. The first step is automatic filtering which reduces the set of images to 200k. This step includes various filtering rules, such as removing offensive content, removing images that has a lot of overlaying text, removing images with low CLIP score, and various others. CLIP is a model that connects text and images to the same embedding space, and if we pass an image with its caption via CLIP, we want the embeddings we get for the image and the text to be similar, and if it’s not similar we count the CLIP score as low.
The next step in the pipeline is done by humans, which reduce the set of images to 20k. In this step they have used generalist annotators, which had a basic task to filter out images of low or medium quality that managed to pass the automatic filtering step. The third and last step is also done by humans, which brings us to the final high-quality images dataset. Here the researchers have used specialist annotators who have good photography principles understanding. And they have guided them to keep the best images that answer guidelines about lighting, color, contrast, background and more. In the following figure from the paper we can see few examples for images that meet the criteria the researchers were looking for. If you are in the market for superclone , Super Clone Rolex is the place to go! The largest collection of fake Rolex watches online!

Diffusion Model Architecture Change
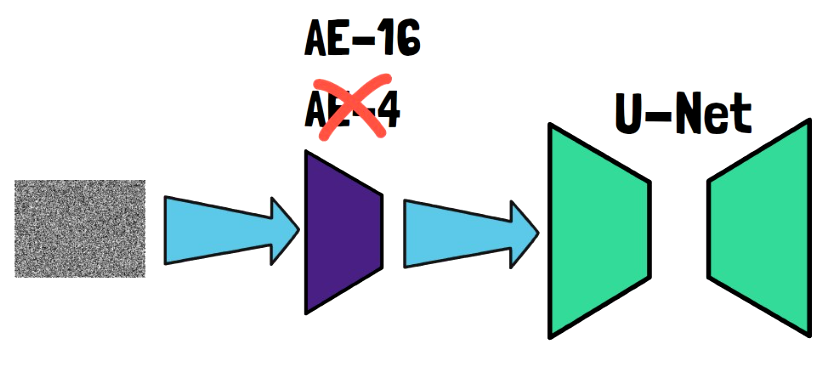
If we would take a close look at the latent diffusion model used by Emu, then we would notice it is slightly different than usual. Latent diffusion models are known to have a U-Net that learns to predict the noise in an image, that is then removed in each iteration. The U-Net works in the latent space and so before passing the input via the U-Net, it is being encoded by an autoencoder. The commonly used autoencoder has 4 output latent channels, and the researchers have found that increasing the number of channels significantly improves reconstruction quality, and so they use 16 channels. This is of course not a full description of latent diffusion models which we won’t dive into in this post. Let’s now review some of the results presented in the paper
Results
The Effectiveness of Quality-Tuning
In the following charts from the paper, we can see comparison between the pre-trained model in red, without the quality-tuning stage, and Emu, which includes the quality-tuning stage in green. The comparisons were done using human annotators. On the top left we see comparison for visual appeal test, where the annotators ranked the output from the two models only based on its visual appeal, and they did not even see the prompt that was used to generate the images. The quality-tuned model clearly outperforms the pre-trained model here.
On the top right we can see the comparison for text faithfulness, where here the annotators do see the original prompt, and are asked to only select the image that best describes the prompt and ignore the visual appeal of the outputs. Here also the quality-tuned model outperforms the pre-trained model, by a smaller margin. The reason the numbers are not summed up to 100 is that in the rest of the cases there was a tie. In the lower two charts we can see a similar trend for both metrics, when measured over stylized prompts, for example prompts that ask for a sketch or a cartoon.

In the paper the researchers also show few examples of image generations for the same prompt from the pre-trained and the quality-tuned models, which we can see in below, where the pre-trained results is on the left, and the quality-tuned is on the right.

Emu vs SDXL
Next, the researchers also compared the visual appeal of Emu with SDXL on Parti and OUI (Open User Input prompts, and we can see the results in the following table from the paper, which shows that Emu wins SDXL by a significant margin.

References & Links
- Paper page – https://arxiv.org/abs/2309.15807
- Video – https://www.youtube.com/watch?v=ga-oJkm4ZJ4&ab_channel=AIPapersAcademy
- We use ChatPDF to analyze research papers – https://www.chatpdf.com/?via=ai-papers (affiliate)
All credit for the research goes to the researchers who wrote the paper we covered in this post.