Code Llama is a family of open-source large language models (LLMs) for code by Meta AI that includes three type of models.
- Foundation models, called Code Llama.
- Python specialization models, called Code Llama – Python.
- Instruction-following models, called Code Llama – Instruct.
Each type comes with 7B, 13B and 34B parameters.
In this post, we delve into the research paper titled “Code Llama: Open Foundation Models for Code”. We’ll explore how Meta AI created these models and compare their performance with other models. We’ll also explore the mysterious Unnatural Code Llama model, which remains unreleased but appears to outperform the other three models.
Code Llama Training Pipeline
We start with a high-level review of the training pipeline, and later on we’ll dive into some of the steps.

The training pipeline starts with a Llama 2 model with 7B, 13B or 34B params. It’s worth noting that, unlike other successful open-source code LLMs like StarCoder, trained solely on code, Llama 2 was trained on both general-purpose text and code data.
Code Training and Infilling Code Training
The first step is the pipeline is code training and infilling code training,. In this step, the researchers fine-tune Llama 2 on a code dataset of 500B tokens. In the following table, we can see that the dataset includes 85% code, 8% natural language related to code, and 7% are natural language, to help the model keep its natural language understanding skills. We’ll expand more about what is the infilling code training a bit later in post.

Python Code Training
For the Code Llama – Python model, we have another step in the pipeline of python code training, where the model we trained in the previous step continue training on another dataset of 100B tokens which is targeted for python. In the following table from the paper, we can see the distribution for this dataset which contains 75% of python code, 10% of other code, 10% of natural language related to code and another 5% of natural language.

Long Context Fine-tuning
The next step is long context fine-tuning. Llama 2 supports a context length of 4,096 tokens, and with such context length we could provide Llama 2 with a file or few files and get file level reasoning.
But with Code Llama and thanks to the long context fine-tuning, the context length is increase to 100k! So now we can feed the model with a full code repository and get repository level reasoning.

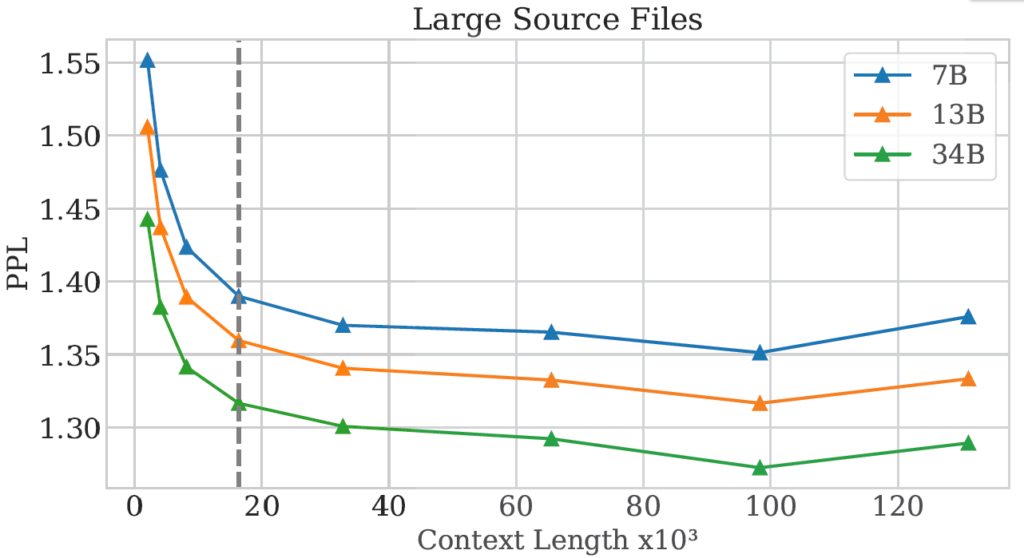
In this step, we fine-tune the model with 16k length sequences, not 100k. However, it extrapolates well for sequences up to 100k tokens. To show this we can look at the following chart from the paper, where we see the perplexity of the models on the y axis, and the context length on the x axis. The dotted line marks the context length in fine-tuning which is 16k, and afterwards we see the perplexity keeps going down up to 100k tokens and then starts to go up.
Another interesting observation for long contexts is that a recent paper titled “Lost in the Middle: How Language Models Use Long Contexts” shows that it is harder for language models to reason based on information in the middle of the context comparing to information in the beginning or in the end of the context.
In the following chart from the paper, the researchers show fantastic results for key retrieval where the x axis is the location of the looked-up key. Only the 7B version seems to have a significant drop when the answer sits in the beginning of the context. The way it is being tested is by randomly adding to a code context the following simple function that returns an integer, where <VALUE> is a random number.

And the prompt ends with an assert statement that checks the value returned from that function, such as:
"assert(my_function() == "We then measure the accuracy of the model yielding the correct value.
Code Llama – Instruct

Going back to the training pipeline, after the long context fine-tuning step, we’ve finished the training process for the Code Llama models and for the Code Llama – Python models. For the Code Llama – Instruct model there is another step in the pipeline which is instruction fine-tuning. As an example for what we can do with the instruction fine-tuned model, here is an example from the paper for a prompt and response from the Code Llama – Instruct model:
Prompt: In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the
Response: You can use the ‘find‘ command in Bash to list all text files in the current directory (excluding subdirectories) that
last month
have been modified in the last month. The command would be:
find . -maxdepth 1 -type f -mtime -30 -name “*.txt”
Here’s a breakdown of the command:
‘.‘ specifies the current directory.
‘-maxdepth 1‘ tells ‘find‘ to only search the current directory and not any subdirectories.
‘-type f‘ tells ‘find‘ to only search for files (not directories or other types of files).
‘-mtime -30‘ tells ‘find‘ to only search for files that have been modified in the last 30 days.
‘-name “*.txt”‘ tells ‘find‘ to only search for files with the ‘.txt‘ extension.
Note that the ‘-mtime‘ option uses the number of days since the file was last modified, so ‘-mtime -30‘ means “modified in the
last 30 days”. If you want to search for files modified in the last month, you can use the ‘-mtime -30‘ option.
In the example above, we can see that rather than providing a code context to complete or fill, we provide the model with a prompt to create a Bash command with few conditions, and the model yields the proper command, and also an explanation about each part of the command.
The process of instruction fine-tuning is very interesting so let’s dive deeper into how it works.
Instruction Fine-tuning with Self-Instruct
In the instruction fine-tuning step, we use three datasets. The first is the same dataset used for instruction tuning of Llama 2. This helps Code Llama – Instruct to inherit Llama 2’s instruction-following and safety properties. However, this dataset does not contain many examples of code-related tasks. For this reason, we have the second and most interesting dataset which is created using self-instruct method. What does self-instruct mean?
First, we provide Llama 2 70B with a prompt to write programming interview questions. With this step we get 62,000 interview-style programming questions, and after removing exact duplicates we end with 52,000 questions.

Then, for each question, we pass it twice via Code Llama 7B. First with a prompt to generate unit tests for the question, and second with a prompt to generate 10 solutions for the question. The model then generates the unit tests and 10 solutions for the question. We run the unit tests on the generated solutions to tell which solution is correct and add the first passing solution, along with the question and tests to the self-instruct dataset.

The third dataset is called Rehearsal, which contains a small proportion of data which was already used in the first step of the pipeline to avoid regression during the instruction fine-tuning process.
Code Infilling

Going back to the training pipeline, we now completed the process for the Code Llama – Instruct model as well. But let’s shortly go back into another interesting capability which we skipped on earlier and it is code infilling. This capability is only supported where we see a two arrows symbol in the training pipeline image, so only for the 7B and 13B versions of Code Llama and Code Llama – Instruct. Let’s expand a bit more on this process.
We only train language models to predict the next token in a sequence, taking a prompt and yielding the most probable next token. With infilling, the model can get a surrounding context and predict the missing information. So, how do we train the model to support infilling?
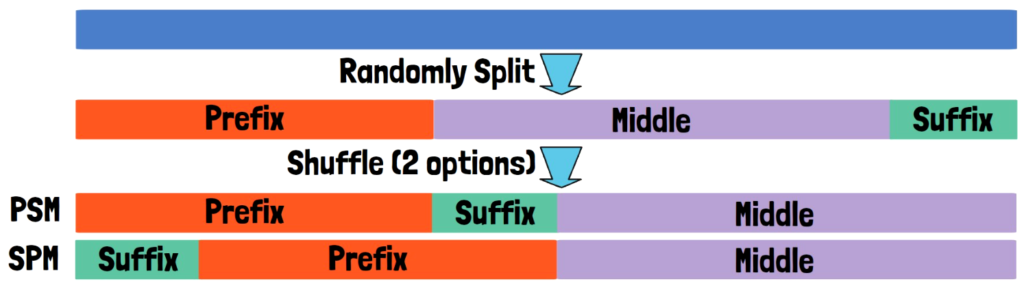
Given an input sequence, we randomly split it into a prefix, a middle part, and a suffix. Then we shuffle the three parts into two options, one is prefix-suffix-middle where the sequence starts with the prefix, followed by the suffix and the middle part at the end. This format is called PSM, shortcut for prefix-suffix-middle. The second format is SPM which stands for suffix-prefix-middle, where we start with the suffix, followed by the prefix and the middle at the end. We then train the model to yield the reordered sequence.
Results
In the following table, we see that the researchers have benchmarked the models on HumanEval, MBPP which is a python dataset and Multilingual HumanEval. Impressively, except from the closed source GPT-4 which achieves 67% on HumanEval, Code Llama models outperform all other evaluated models on all three benchmarks.

Another model, Unnatural Code Llama with 34B params, which was not released when writing this, outperforms the other models with 62.2% on HumanEval and 61.2% on MBPP. So what is this model? This model is actually the Code Llama – Python 34B model, fine-tuned over the self-instruct dataset which we covered earlier. This inspiration for this model comes from a research paper from Meta AI titled Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor.

Another interesting chart from the paper shows the correlation between performance for different programming language where a value of 1 means perfect correlation, and we can see very high correlation for some couple of languages, for example there is 0.99 correlation for C# and Java which have a similar nature.

References
- Paper link
- Join our newsletter to receive concise 1-minute read summaries for the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.