
AI Research Trends
170,927 AI Papers Reveal the Biggest Research Shifts of the First Half of 2026
A deep data analysis of arXiv reveals the defining AI research trends of mid-2026: the agentic boom, Qwen overtaking Llama, and what’s fading…
Read MoreTrending

Google Nested Learning Explained: Hope Architecture, Continual Learning, and the End of Frozen LLMs
Google’s Nested Learning paper and Hope model explained: a new approach to continual learning in LLMs that addresses catastrophic forgetting…

DeepSeek’s mHC Explained: Manifold-Constrained Hyper-Connections
Manifold-Constrained Hyper-Connections (mHC) explained: How DeepSeek rewires residual connections in LLMs for next-gen AI…
Looking for a specific paper or subject?
Latest AI Papers Reviews

Microsoft’s SkillOpt: 2x Accuracy Without Touching the Model
A breakdown of Microsoft’s SkillOpt paper, which applies gradient-descent-like optimization to continuously improve AI agent skills…

DeepSeek-V4 Explained: The End of Standard Attention in LLMs?
In this post, we break down DeepSeek-V4, a new LLM from DeepSeek designed for highly efficient reasoning over million-token contexts…

Google Nested Learning Explained: Hope Architecture, Continual Learning, and the End of Frozen LLMs
Google’s Nested Learning paper and Hope model explained: a new approach to continual learning in LLMs that addresses catastrophic forgetting…

GDPO Explained: How NVIDIA Fixes GRPO for Multi-Reward LLM Reinforcement Learning
GDPO is NVIDIA’s solution to GRPO’s limitations in multi-reward RL for large language models. We break down the paper in this post…

DeepSeek’s mHC Explained: Manifold-Constrained Hyper-Connections
Manifold-Constrained Hyper-Connections (mHC) explained: How DeepSeek rewires residual connections in LLMs for next-gen AI…

Emergent Hierarchical Reasoning in LLMs Through Reinforcement Learning
Discover how reinforcement learning enables hierarchical reasoning in LLMs and how HICRA improves on top of GRPO…

Less Is More: Tiny Recursive Model (TRM) Paper Explained
In this post, we break down the TRM paper, a simpler version of the HRM, that beats HRM and top reasoning LLMs with a tiny 7M params model…
DINOv3 Paper Explained: The Computer Vision Foundation Model
In this post we break down Meta AI’s DINOv3 research paper, which introduces a state-of-the-art Computer Vision foundation models family…

The Era of Hierarchical Reasoning Models?
In this post we break down the Hierarchical Reasoning Model (HRM), a new model that rivals top LLMs on reasoning benchmarks with only 27M…

Microsoft’s Reinforcement Pre-Training (RPT) – A New Direction in LLM Training?
In this post we break down Microsoft’s Reinforcement Pre-Training, which scales up reinforcement learninng with next-token reasoning…

Darwin Gödel Machine: Self-Improving AI Agents
In this post we explain the Darwin Gödel Machine, a novel method for self-improving AI agents by Sakana AI…

Continuous Thought Machines (CTMs) – The Era of AI Beyond Transformers?
Dive into Continuous Thought Machines, a novel architecture that strive to push AI closer to how the human brain works…
Most Read AI Papers Reviews

GRPO Reinforcement Learning Explained (DeepSeekMath Paper)
DeepSeekMath is the fundamental GRPO paper, the reinforcement learning method used in DeepSeek-R1. Dive in to understand how it works…

DeepSeek-R1 Paper Explained – A New RL LLMs Era in AI?
Dive into the groundbreaking DeepSeek-R1 research paper, introduces open-source reasoning models that rivals the performance OpenAI’s o1!…

Titans by Google: The Era of AI After Transformers?
Dive into Titans, a new AI architecture by Google, showing promising results comparing to Transformers! Paving the way for a new era in AI?…
Large Concept Models (LCMs) by Meta: The Era of AI After LLMs?
Explore Meta’s Large Concept Models (LCMs) - an AI model that processes concepts instead of tokens. Can it become the next LLM architecture?…
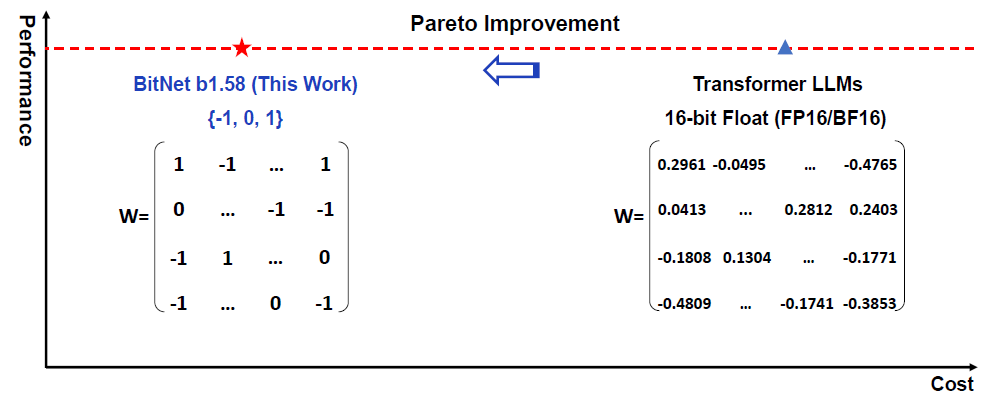
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
In this post we dive into the era of 1-bit LLMs paper by Microsoft, which shows a promising direction for low cost large language models…
DINOv2 from Meta AI – A Foundational Model in Computer Vision
DINOv2 by Meta AI finally gives us a foundational model for computer vision. We’ll explain what it means and why DINOv2 can count as such…