Welcome WizardMath, a new open-source large language model contributed by Microsoft. While top large language models such as GPT-4 have demonstrated remarkable capabilities in various tasks including mathematical reasoning, they are not open-source. And for open-source large language models such as LLaMA-2 the situation is different, and until now they did not demonstrate strong math capabilities. So here comes WizardMath, a new best open source large language model for mathematical reasoning, surpassing models such as WizardLM and LLaMA-2. In this post, we will explain the research paper that introduced this model, titled “WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct”. By reading through, you will have better understanding about how this model was created and what is the Reinforced Evol-Instruct method.
If you prefer a video format, then most of what we cover here is also reviewed in the following video:

WizardMath is created using the following three steps which we’re going to dive into now.
- Supervised Fine-tuning
- Training reward models
- Active Evol-Instruct and PPO training.
Supervised Fine-tuning
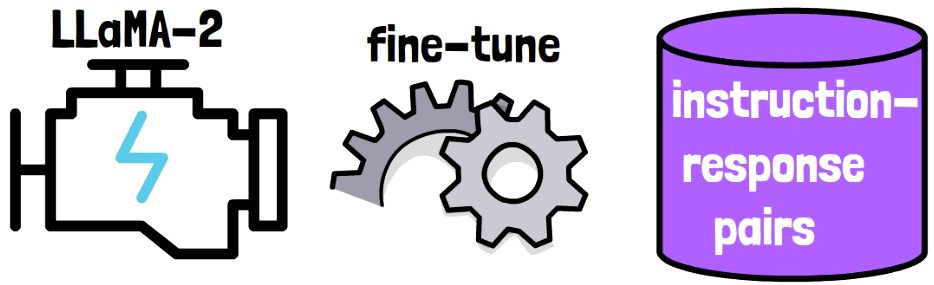
In this step we take LLaMA-2 model as the base model, and fine-tune it on a dataset that the researchers constructed which contains instruction and response pairs.
How do they build this dataset? They look at two datasets, GSM8k and MATH that contain math instruction and response pairs. They sample 15k pairs and re-generate the response to be in a step-by-step format. The meaning of step-by-step format is where the response explains in details the process to reach the solution it provides rather than just the answer. For example, consider the instruction-response pair in the picture below, where the instruction is to get the value of c from an equation, and the response is -6. The pair is given to WizardLM-70B to re-generate the answer in a step-by-step format, and in our example below we can see the response on the right in a step-by-step format. To create this example we used ChatGPT but the point is the same.

In addition to the math instructions-response pairs they also include in the fine-tuning dataset 1.5k open-domain samples from WizardLM training data. Once we’ll complete this step, and also steps 2 and 3, the fine-tuned model will be named WizardMath but we still have two more steps to cover.
Before proceeding to the next steps though, we need to cover an essential background which is Evol-Instruct.
Evol-Instruct
Evol-Instruct is a method to create new instructions using a large language model.
We start with an initial dataset of instructions which are usually manually crafted, and using Evol-Instruct we are going to evolve the dataset. What does it mean?

In each step we take an initial instruction, like in the simple example above. We then provide this instruction to a LLM and ask it to rewrite the initial instruction by using well-crafted prompts. For example, one type of prompt is used in order to add constraints to the original instruction
The LLM then outputs a new instruction matching the requirement, as we can see in the output on the right of the example above, where a constraint has been added to the original question.

Adding constraints is one example of instruction evolution. Another example is deepening, where here as well the model will yield a matching new instruction as we can see in the picture above.
Both adding constraints and deepening, and few more which are not presented here, are called in-depth evolving because they remain with the idea of the original instruction. Another type of evolving is called in-breadth, where the prompt asks the LLM to create an entirely new instruction by taking inspiration from the original instruction. In this case the model yields a completely new instruction, as we can see in the picture above in red.
Once we finish this process, we get an enhanced database with more complex instructions, more diverse instruction types, meaning that the tasks the instruction ask the model to solve are more diverse, and more diverse topics. All of these would have been very hard to do manually.
Now we’re ready to proceed to steps two and three which present a novel reinforcement learning approach called Reinforced Evol-Instruct.
Reinforced Evol-Instruct
Reinforced Evol-Instruct is a novel reinforcement learning method that is using Evol-Instruct, and since it is a reinforcement learning method, we have two steps here. The first is to create a reward model, in this case we will have two reward models, and the second step is using the reward models to improve our original model.
Reward Models
As mentioned, we want to train two reward models:
- Instruction Reward Model (IRM) – Purposed to rank the instruction quality.
- Process-supervised Reward Model (PRM) – Purposed to asses the steps in the response, like the steps we saw in one of the examples above where the LLM output consisted of 4 steps until it reached the final result.
This reward model is inspired from the recent Open AI paper titled Let’s Verify Step by Step, where they show the importance of supervising the process to reach a solution to improve mathematical reasoning.
Ok so how do we create these reward models?
Training the Instruction Reward Model (IRM)

To create the instruction reward model, we create an instruction ranking dataset. We start from the math dataset created on step 1, and for each instruction in that dataset, we evolve it to generate few evolved instructions using Evol-Instruct method, where we use both Wizard-E and ChatGPT as the models that evolve the instructions. Wizard-E is a model that was fine-tuned specifically to execute Evol-Instruct. An important note is that the instruction evolution here is using new math-specific evolvement prompts which WizardMath paper contributes. We then get several evolved instructions from both models, and we rank the generated instructions using Wizard-E, and then we add the generated instructions with their rankings to the instruction rankings dataset that we use to train the instruction reward model.
Training the Process-supervised Reward Model (PRM)

To train the process-supervised reward model, we create a dataset of steps assessments and train the model on that dataset. How do we create this dataset? For each instruction in the math dataset created on the first step, we pass it via our model from step 1 to generate a step-by-step response, then we assess the response using ChatGPT to get assessment for each step, which we then add to the steps assessment dataset that we use to train the PRM.
Ok, now that we have the trained reward models, let’s see how they are used in order to improve our model. This step is called active Evol-Instruct and PPO training.
Active Evol-Instruct and PPO training
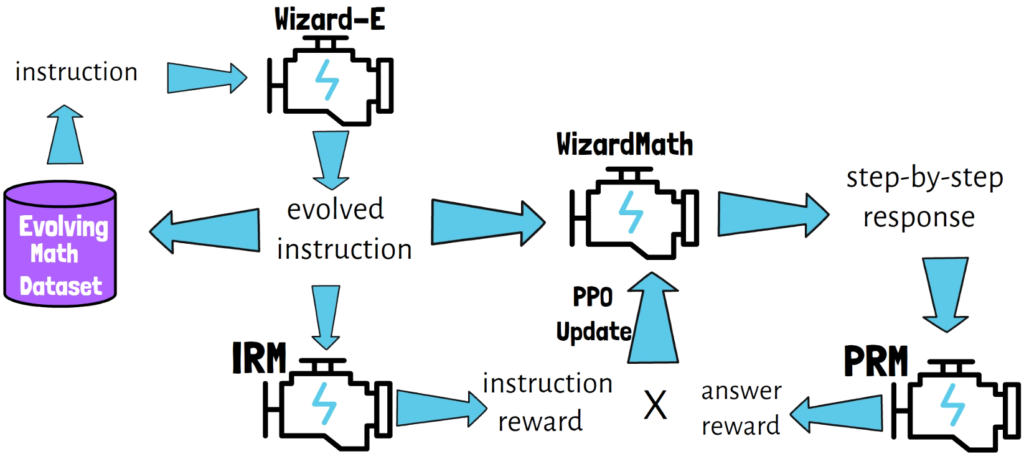
We again start with the math dataset created on step 1. On each step we take an instruction from the dataset, we then evolve it with Evol-Instruct using Wizard-E, and get an evolved instruction. The evolved instruction is then added back to the instruction dataset, so this dataset is evolving using Evol-Instruct.
Additionally, the evolved instruction is provided to the model we train, WizardMath, which generates a response in a step-by-step format. Then, we get the evolved instruction reward from the instruction reward model, and also get the answer reward from the process-supervised reward model. We then multiply both of the rewards to get the final reward, and apply a PPO update based on the final reward. PPO stands for Proximal Policy Optimization, which we won’t dive into in this post.
Results
Open-Source Models Comparison

In the table above, we can see the results of LLaMA-2 on GSM8k and MATH datasets with two more open-source models. In the paper they show more models in this table but the ones here contain the top 3. And in the bottom we case WizardMath results, achieving staggering +24.8% improvement on the GSM8k dataset! and +9.2% percent on the MATH dataset.
However, we added manually to the table a model that does not appear on the table in the paper which is WizardLM (it does appear on other chart on the paper though), which with its 70B params version achieves 77.6% on GSM8k which is below WizardMath but only by 4%.
Closed-Source Models Comparison
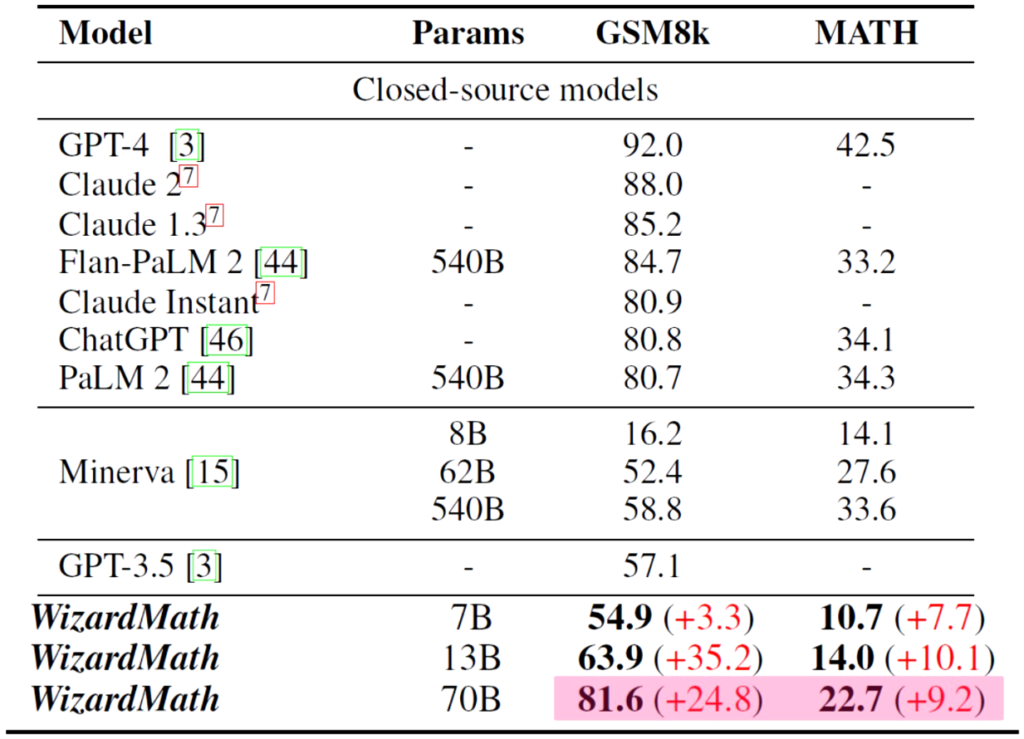
Removing the open source models from the previous table to compare with closed source models we see that WizardMath is comparable or slightly better than some, including ChatGPT, but still have a place for improvement comparing to the top 4 and GPT-4 at the top.
References
- Paper – https://arxiv.org/pdf/2308.09583.pdf
- Video – https://youtu.be/WeQjkWPKvXM
- Code – https://github.com/nlpxucan/WizardLM/tree/main/WizardMath
A recommended read for another fascinating advancement we recently covered that improves over the known mixture of experts can be found here – https://aipapersacademy.com/from-sparse-to-soft-mixture-of-experts/