In this post, we dive into Vision Transformers (ViTs) registers, introduced in a research paper by Meta AI titled “Vision Transformers Need Registers”. The paper share authors with DINOv2 paper, a successful foundational computer vision model by Meta AI which we covered here.

Our agenda for this post will be:
- Background: Visual Features – An essential knowledge to understand what this paper is about.
- The Problem: Attention Map Artifacts – A phenomenon discovered and analyzed in this paper, found to be common in large foundational computer vision models, such as DINOv2.
- The Fix: Registers – The proposed solution to remove the attention map artifacts.
- Results & Conclusion – Understand whether ViT with registers fixes DINOv2 and other models, or should only be used in certain cases.
Background – Visual Features
We start with an essential background knowledge about visual features.
Why Do We Need Visual Features?
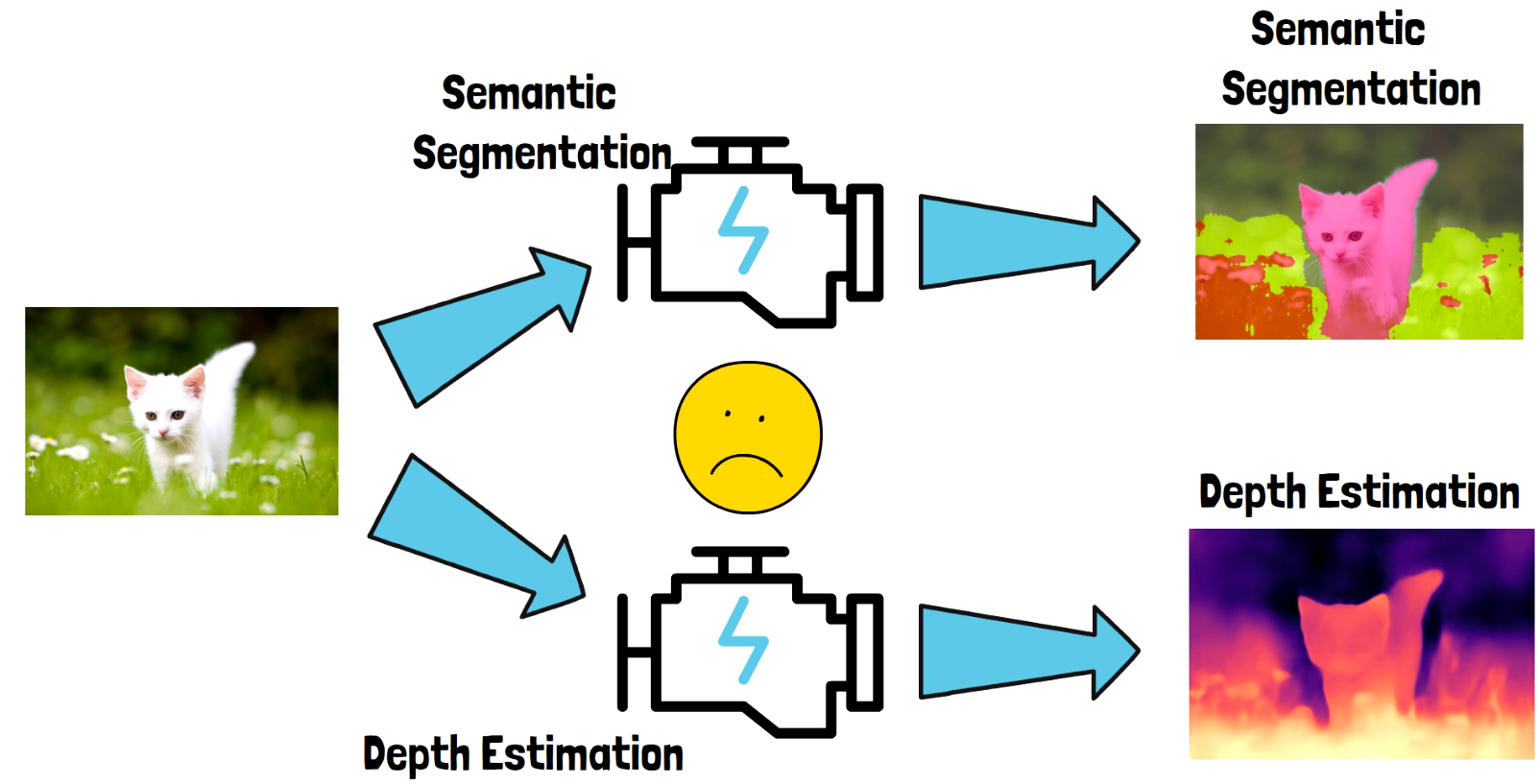
Imagine for example that we have multiple tasks we want to solve:
- Image segmentation – categorizing related parts of the image. See a segmented cat below for reference 🙂
- Depth estimation – estimate the depth of different parts in the image. As we can see in the image on the bottom right, objects in the front are colored with brighter colors.
One way of achieving that is to train two dedicated models, one for semantic segmentation and one for depth estimation. Each model is fed with the cat input image and yields an output for the specific task. This process can be complex and we might also need to use pretty large models depending on the task complexity.
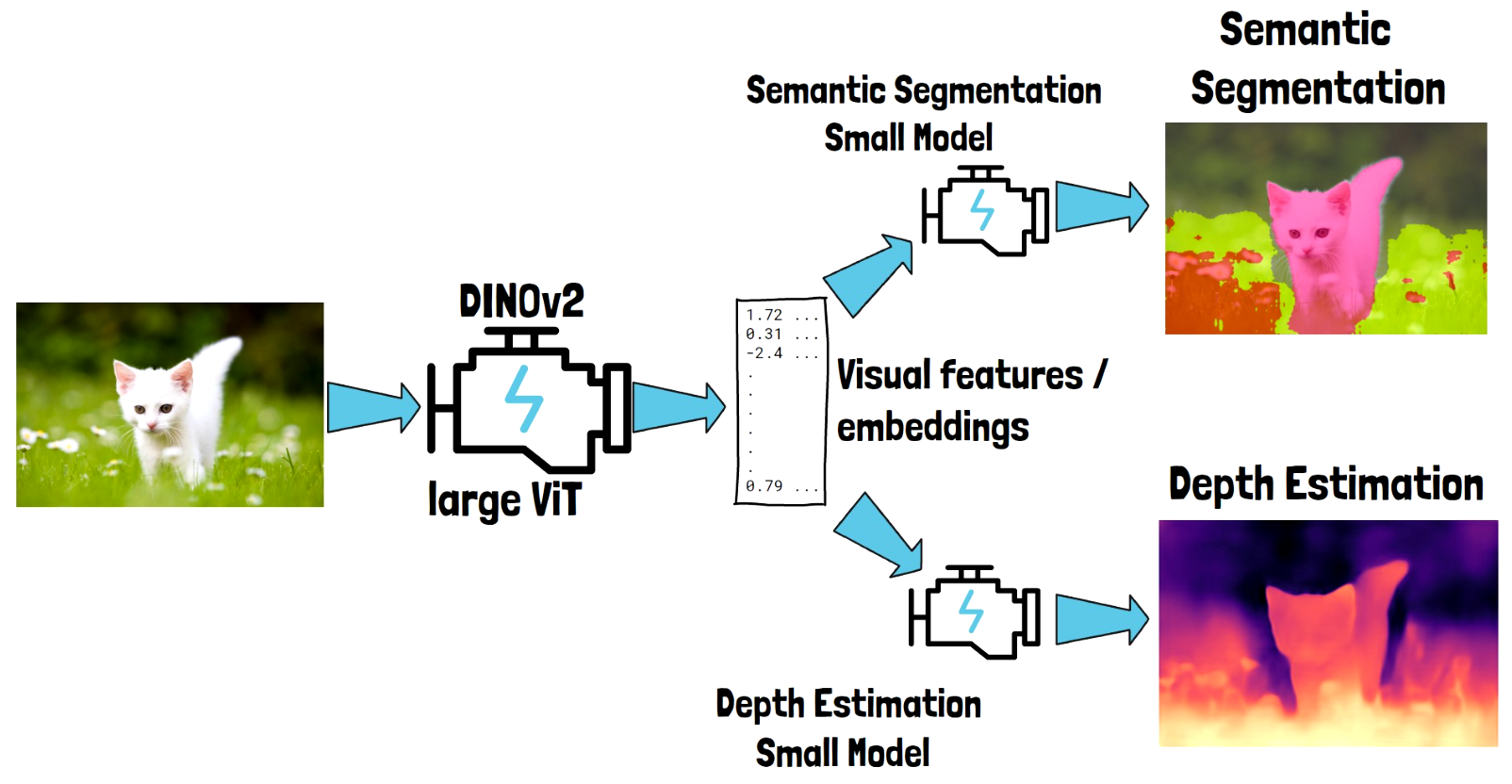
How Visual Features Help?
Instead of training two dedicated models from scratch, we can first pass the image via a foundational pre-trained large computer vision model, such as DINOv2, a large Vision Transformer (ViT) model. DINOv2 will yield vectors of numbers, which are called visual features or embeddings. The visual features capture the semantic of the input cat image, and once we have them, we can use them as the input for small and simple models, that target the specific tasks that we want to solve.
The Problem – Artifacts
Ok, so we’re done with the background and now we’re ready to describe the problem that the researchers have found. Let’s start with understanding what is an attention map.
Attention Map
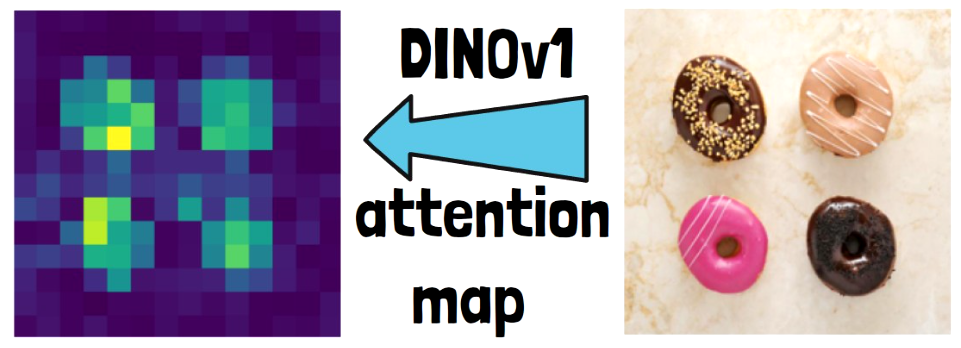
In order to calculate the visual features, the visual transformer is using the attention mechanism. The attention map is a visualization of the attention values, which shows which parts of the input image the model is attending to when computing the visual feature. Attention maps provide intuition for which parts of the image are important. In the below example of an attention map extracted from DINOv1, we see bright colors in the donuts location and dark colors on the background.
Object Discovery

One usage for attention maps is in object discovery, where given an input image we locate objects in the image. Unlike object detection, object discovery also locates unknown not-labeled objects, such as the frisbee in the image below. Object discovery using attention maps method is called LOST. LOST was introduced in a research paper from 2021 using DINOv1, and both example images are taken from that paper.

What Are The Artifacts?
An intuitive improvement for the LOST method is using DINOv2 instead of DINOv1, but when the researchers have tried to do that, they have noticed that instead of an improvement, DINOv2 actually delivers disappointing performance. When investigating the reason for that, they have found that the attention map in DINOv2 is not as semantically clear as in DINOv1. Instead, there are outlier peaks in DINOv2 attention map that appear in positions that are part of the background of the original image. These are called the attention map artifacts.

In the following image from the paper, we can see that other large visual transformer models such as OpenCLIP and DeiT also have artifacts in their attention maps, so DINOv1, which we can see its attention maps on the second column from the right, is actually the exception.

Analyzing The Artifacts

In the above figure, the researchers have looked into the L2 norm values of the features extracted for image patches from DINOv1 and DINOv2, which helps to understand the magnitude of the features. In DINOv2 we can see that the majority of features are of low value but a small proportion of patches have high norm. An interesting question here is that if the model assigns such a high norm for the outlier features, what data do they contain?
What Data Do The Artifacts Capture?
The researchers have investigated this question and came up with interesting conclusions.
- Artifacts lack spatial information.
- Artifacts hold global information
Artifacts Lack Spatial Information

High-norm features contain less information about their position in the original image. We can see evidence for this in the above figure from the paper. On the left we see a chart that shows with the orange line that the artifacts are located in patches that are very similar to their surrounding patches. So, as we saw in the examples earlier, this confirms that the artifacts appear in background locations of the input image. Additionally, the researchers have trained models to predict the original position of a token in the image, and a model to reconstruct the original pixels. In both cases it performs worse for the high-norm tokens than the other tokens, as we can see in the table on the right.
Artifacts Hold Global Information

This observation can be explained in the above table from the paper, where we see image classification results when using embeddings from DINOv2 as inputs. In the upper row we see results when using the embeddings of the class token, which is a token added to the input sequence in order to capture global information. So the results are better when using the class token, but in the next two rows we can see the results when using regular tokens and outlier or high-norm tokens. And we clearly see that the high-norm tokens achieve better results here.
When Do The High-Norm Tokens Appear?
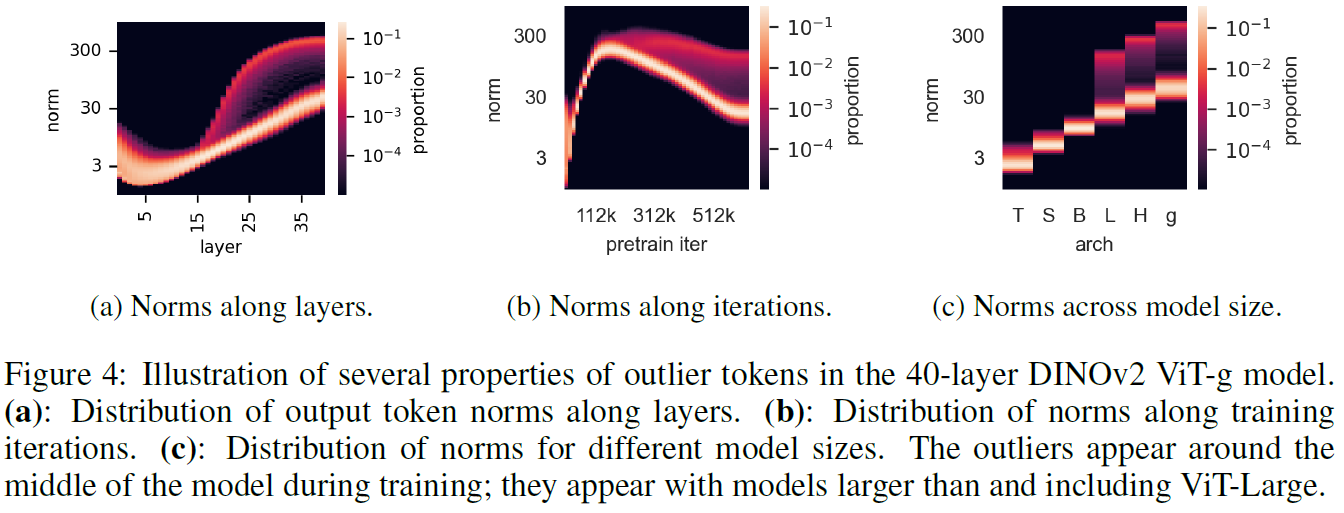
We can answer this using the above figure. On the left chart, we see that high-norm tokens are more common from the middle to the last layers of the model. In the middle chart we can see that the high-norm tokens start to appear after training the model for a while and not at the beginning of the training process. On the right chart we see that the high-norm tokens only appear on larger models, where the letters stand for the different DINOv2 sizes. So we understand that large and sufficiently trained models learn to recognize redundant tokens, and use them to store global information. We’ll see soon how the researchers handle that but regardless, this observation alone is super interesting by itself.
The Fix – Registers
What Are The Registers?

We’ve explained the problem and now we are ready to discuss the fix, which are the registers. The fix is very short to explain as it is quite simple and we can understand it with the above figure from the paper. The idea is that if the model learns to use tokens that are less important in order to store global information, we can add more tokens that the model will use to store that information, instead of the tokens from the original image. The added tokens are called registers and they are added to the input sequence, but discarded from the output. Since they are discarded from the output, the assumption is that the model will use them instead of the image patch tokens to store the global information.
Do Registers Prevent Artifacts?

We can see examples that training the models with the additional register tokens really prevents the artifacts from appearing in the above figure, where we see the attention maps without the registers and with the registers, and with the registers the attention maps have much less artifacts and seems more semantic and related to the original image. It can also be seen in the following charts where we see the distribution of norms without and with registers, and it is clear that the registers help to remove the outliers. We mainly talk about DINOv2 but we can see it also works for OpenCLIP and DeiT, a bit less for DeiT.

Results
Ok, so we’ve described the solution and now let’s move on to see some results.
Classification, Segmentation and Depth

In the above table from the paper, we can see comparison for models with and without registers on three tasks. Image classification results (ImageNet) show a slight improvement when using ViTs with registers. Image segmentation results (ADE20k) also show a slight improvement with registers, and a more significant improvement for DINOv2. On the right column we see performance for depth estimation, where lower score is better for the metric here. Performance with registers is better here for CLIP and DINOv2, again by a small margin, and almost equal for DeiT.
Object Discovery
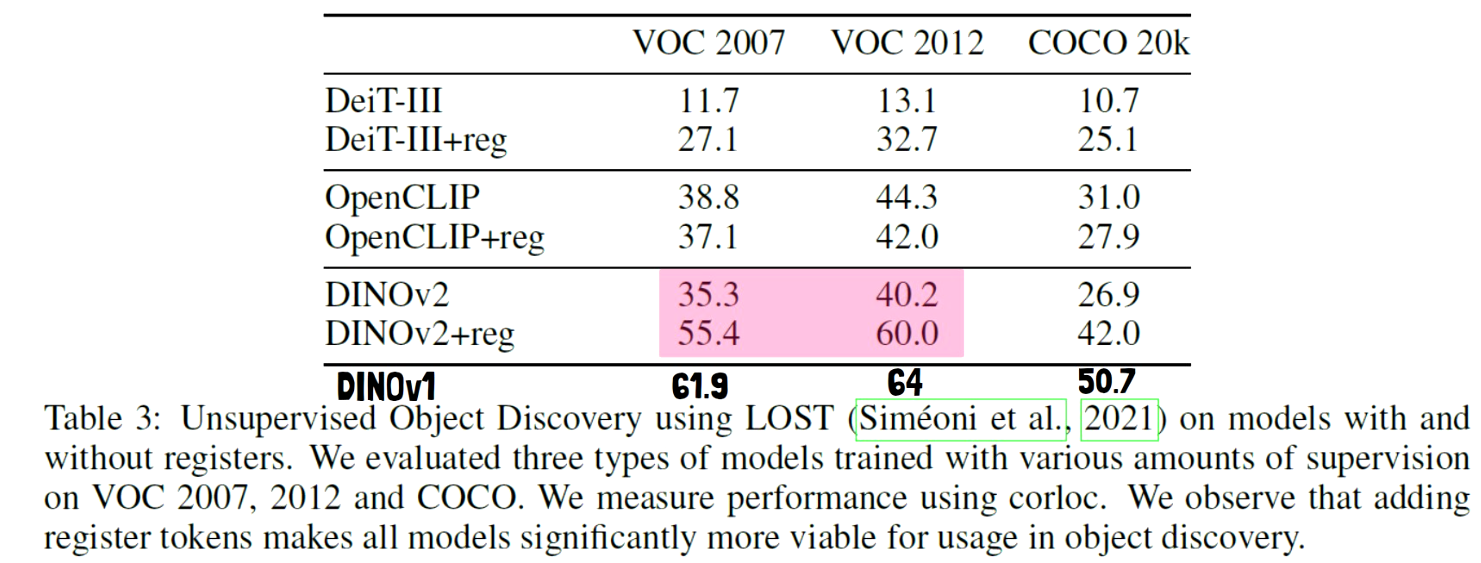
In the paper there are also results for object discovery, which we can see in the above table. Noticeably, DINOv2 with registers achieves better score by 20 points comparing to without registers which is impressive. However, DINOv1 is missing from the original table, and when adding it on the bottom, we can see it still achieves better results than DINOv2 here.
Conclusions
- The paper exposed and explained the phenomenon of input tokens that are not important, being used by the model to save other information that is more useful, which is very interesting by itself.
- The addition of registers almost completely removes the artifacts.
- In practice, for classification, segmentation and depth, the results are just slightly better with registers, yet we pay for the added tokens with memory and latency, so it is not surely worth it in all cases
- There is impressive improvement for object discovery when using DINOv2. However, it is still not good as the results with DINOv1.
References & Links
- Paper – https://arxiv.org/abs/2309.16588
- LOST method paper – https://arxiv.org/abs/2109.14279
- Explaining DINOv2 – https://aipapersacademy.com/dinov2-from-meta-ai-finally-a-foundational-model-in-computer-vision/
- Video – https://youtu.be/AwAgxXmkda0
- We use ChatPDF to analyze research papers – https://www.chatpdf.com/?via=ai-papers (affiliate)
All credit for the research goes to the researchers who wrote the paper that we covered in this post.