
NExT-GPT is a multimodal large language model (MM-LLM) developed by NExT++ lab from the National University of Singapore, and presented in a research paper titled “NExT-GPT: Any-to-Any Multimodal LLM”. With the remarkable progress of large language models, we can provide a LLM with a test prompt in order to get a meaningful answer in response.

However, as humans, we are used to communicate using multiple senses. And so, in order to have a more human-like AI, it can be valuable to be able to use more modalities as inputs such as audio, video and image. With NExT-GPT, it is possible to use these modalities as inputs and get a meaningful text answer in response. But not only that, NExT-GPT can also yield outputs in the different modalities, if they are a better match for the provided input. From here the paper title of any-to-any multimodality. In this post, we will dive into the research paper to understand how this innovative system works.

If you prefer a video format, then check out our video:
NExT-GPT Framework
Let’s start by reviewing the NExT-GPT framework with the following image from the paper.

On the left we see the possible input modalities of text, image, audio and video. In the center, we have a large language model which is the core of the framework and we want it to process the input from all modalities and guide the generation of outputs for all modalities, but it can only understand and generate text. So, how NExT-GPT overcomes that?
The NExT-GPT system consists of the following three main tiers which together enable that, and we will review them one by one:
- Multimodal Encoding Stage
- LLM Understanding and Reasoning Stage
- Multimodal Generation Stage
Multimodal Encoding Stage
The first tier is multimodal encoding stage, which is in charge of converting the inputs, which are not text, to text prompts. And this stage happens in two steps, which we mark in the framework image below. The first step is called multimodal input encoding, where each input is passed via an encoder that can process its modality, which gives us semantic embeddings of the input. The second step is called LLM-centric alignment, where the embeddings are passed via small linear models, which are called input projection models, in order to generate text from the embeddings, which the LLM can understand.

LLM Understanding and Reasoning Stage
The second tier is LLM understanding and reasoning stage, where the core LLM yields the text response, but also instructions for the other modalities generation. So the LLM output can contain multiple parts, which are distinguished using special tokens, and that the LLM is using to signal that there should be output for the certain modality, and which part in the LLM response is related to that modality. In the following image we highlight that stage and write below the LLM an example of the LLM output structure.
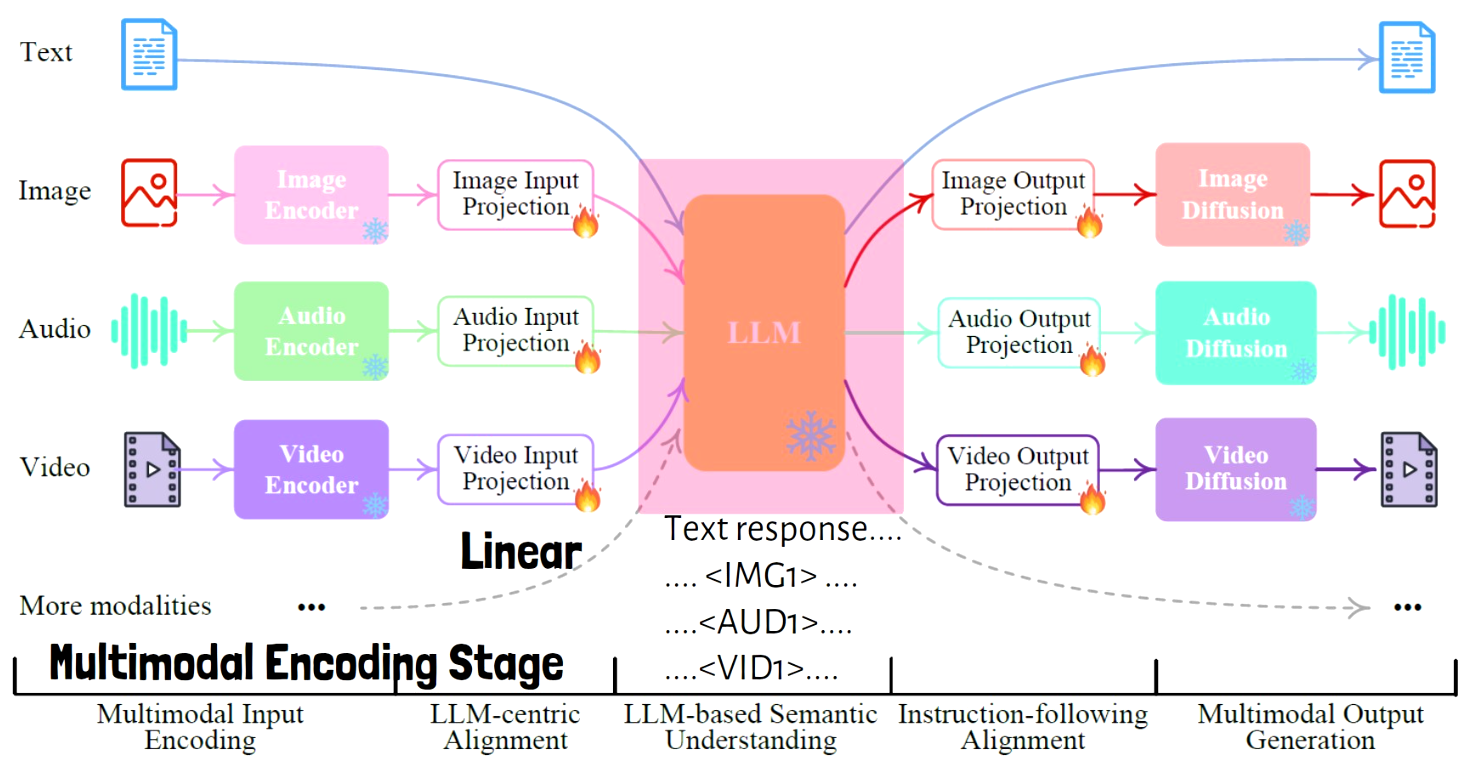
Multimodal Generation Stage
The third tier is the multimodal generation stage, which we highlight in the image below. This stage is in charge of generating the final output for all modalities based on the LLM response, and it is done in two steps. The first step is instruction-following alignment, where the output from the LLM that is relevant for the non-text modalities is passed via small transformer-based models that are called output projection models, that convert the LLM outputs into representations that can be processed by the modalities decoders. The second step is multimodal output generation where we generate the output for each modality using its specific diffusion decoder.

Which Component of NExT-GPT are Trained?
Overall, the NeXt-GPT system has many components, but in order to train it we only need to train a very small portion of the weights. The modality encoders are in fact from ImageBind, which is a fascinating model by Meta AI that can process multiple modalities and yield semantic embeddings in the same embedding space. We’ve covered ImageBind thoroughly here. These encoders are kept frozen during NExT-GPT training. The diffusion models are also taken as is, where the image diffusion model is Stable Diffusion, the video model is Zeroscope, and the audio generation model is AudioLDM, and all three of them are also kept frozen during the training process. The LLM used here is Vicuna-7B, which is common in other multimodal LLMs, and it also remains frozen. The LLM is actually not entirely frozen since a small amount of LoRA weights are trained here.
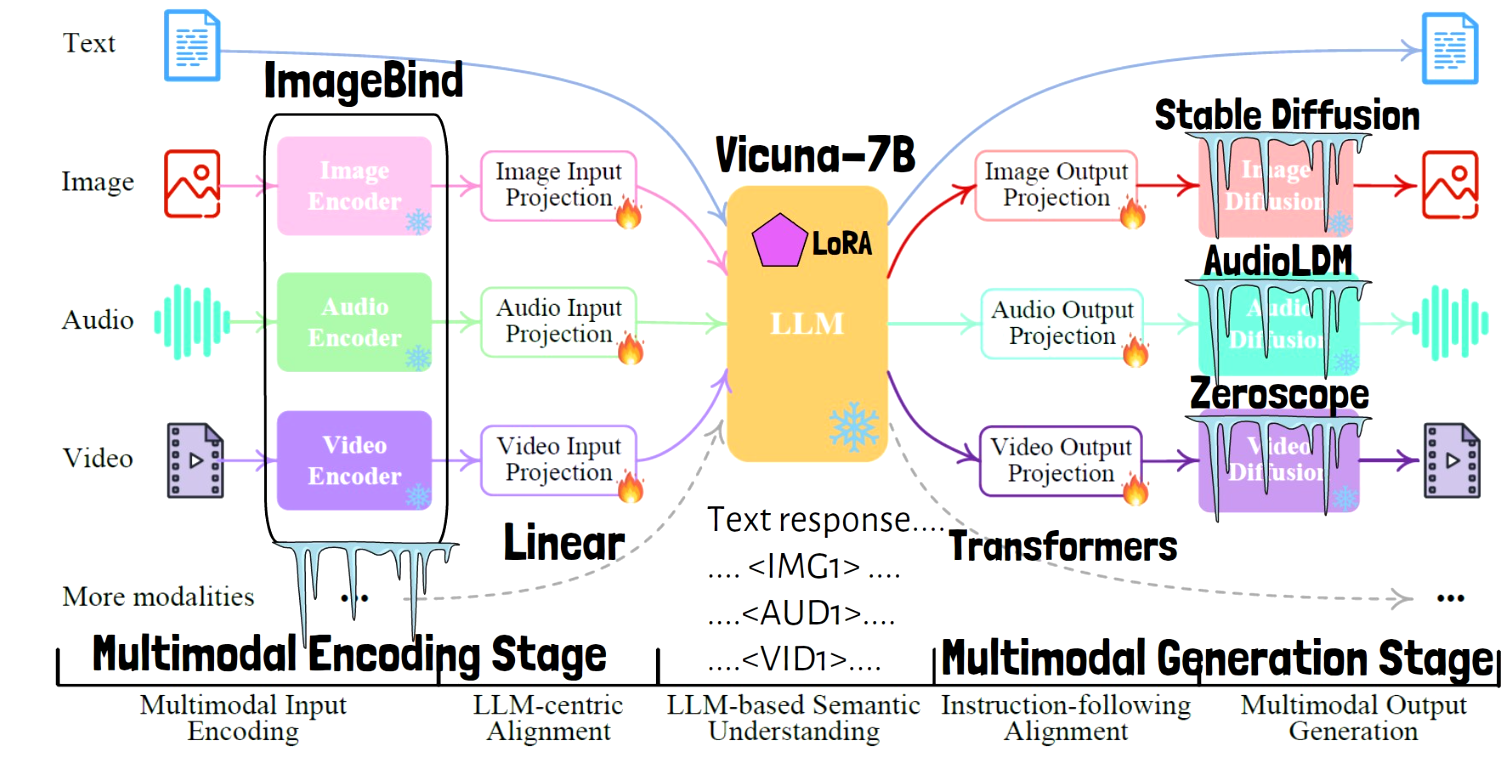
System Configuration
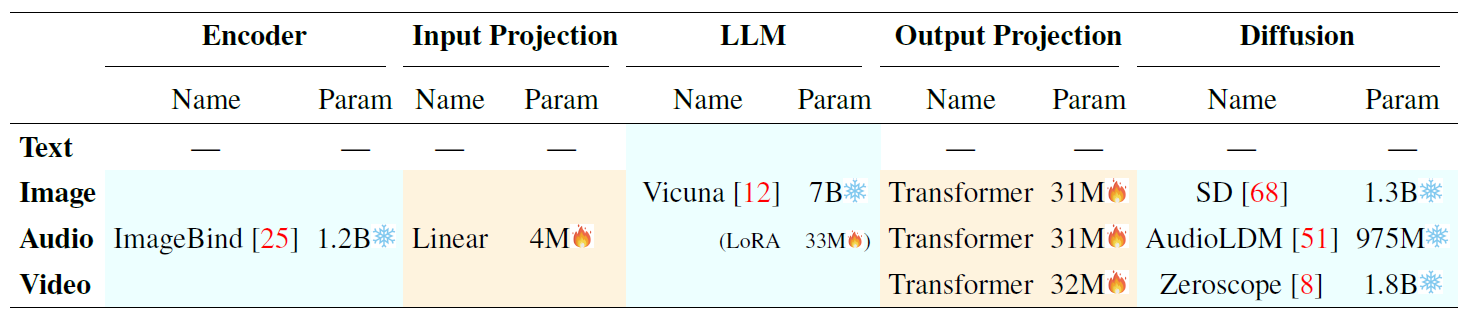
In the above table from the paper we can see the full system configuration. ImageBind is the encoder with 1.2 billion params, which is marked as frozen. The input projection layer which is trained has 4 million params. The LLM has 7 billion params which are frozen and 33 million trainable LoRA weights. The output projection layer has around 30 million weights for each transformer, and all of the transformers are trained, and the frozen diffusion models which together have approximately 4 billion params. Overall, only 1% of all weights are trained.
NExT-GPT Conversation Example
Let’s now look at an example from the paper for a conversation with NExT-GPT. In the image below, we can see on the left a text prompt which is being fed into the LLM, talking about going to the seaside during the summer. The multimodal input encoding is grayed out since there is no other input type in addition to the text prompt. The LLM then yields a text response, talking about beach volleyball as an example for a sea activity, but it also yields image signal tokens and instructions, that are being converted to an input for Stable Diffusion, which yields a volleyball image.

Next, we see another step in this conversation where the user says he is more into surfing and would like to create a video about it, providing a surfing image as a reference. And now we see that the image encoder and projection are not grayed out, and passed to the LLM in addition to the text. As output, we get a text saying that “here’s a reference”, and another surfing video is generated as the reference.

Training NExT-GPT
Lightweight Multimodal Alignment Learning
Let’s now dive deeper into how NExT-GPT system is trained, starting with lightweight multimodal alignment learning. Earlier we’ve reviewed the architecture which we see here again for reference. And now we’re going to focus on how the input and output projection models are trained, also referred as the LLM-centric alignment and the instruction-following alignment steps (the second and forth columns on the framework drawing).

Encoding-size LLM-centric Multimodal Alignment
We start with the encoding-size LLM-centric multimodal alignment step. In the following diagram from the paper, we see the training process of the input projection models, where we use pairs of image and text caption, audio and text caption, and video with text caption. And we feed the non-text input to the encoder, which yields a representation. The representation is then fed into the input projection model which yields an aligned representation for the LLM. The LLM then yields a response, which is compared to the text caption which match the input we provided to the encoder, and the loss is propagated to the input projection model. The encoders and the LLM are kept frozen here.

Decoding-side Instruction-following Alignment
Next we review the decoding-side instruction-following alignment step, where we still use similar captioned inputs as before. We do not use any generation of image, audio and video here which is very interesting. The way it works is that the LLM outputs a response with a signal token, which is passed via the output projection model, and the output from the output projection model is compared to the encoding we get when feeding the caption to the text encoder of the diffusion model, so we only need the text encoder from the diffusion model and we don’t need to run the diffusion process, which makes this step very efficient.

Modality-switching Instruction Tuning (MosIT)
Another training step that is meant to help NExT-GPT to follow instructions that include inputs from multiple modalities is modality-switching instruction tuning. In this step we keep on training the trainable components we’ve just saw and also train the LoRA weights. We feed the system with dialogue inputs that include multiple modalities, as we can see on the left in the image below. The LLM generates the response with modality signal tokens. We then compare the LLM output with gold annotations to calculate the loss that will be used to update the LoRA weights.

But where are the gold annotations of LLM outputs come from? The researchers use three types of data:
- Text + X to Text – The input is a tuple of text and a sample from other modality, and the gold annotation is a caption text. Here the researchers have used existing datasets that were used in other multimodal LLMs.
- Text to Text + X – The input is text and the output is a tuple of text and another modality. This is much less common than the previous data type. This dataset was created by using similar data to the first dataset, and reversing it. In addition to reversing, the researchers have used GPT-4 to wrap the caption which is now the input, to make it look like an instruction.
- MosIT Data – The first two datasets are too simple for the goal of NExT-GPT, so here comes the third dataset that contains high quality instructions that contain dialogue with multiple responses and multiple modalities, where the researchers leveraged GPT-4 to create the conversations, and added images, videos and audios to the conversations where it was proper to do so.
Results
We’re finally ready to see some results. In the paper’s results section, we can find the following chart, where on the x axis we see classes of examples, divided based on the modalities in the input and the output, and on the y axis we see the performance of NExT-GPT on the examples class. Since there is lack of benchmarks for evaluation, the performance is given by human evaluators who score the performance on a scale of 1 to 10.
Noticeably, generating images from various kind of inputs works best, as we can see with the top three bars.

References
- Paper page – https://arxiv.org/abs/2309.05519
- Project page – https://next-gpt.github.io/
- Video – https://youtu.be/U-tN1hOMces
- We use ChatPDF to help us analyze research papers – https://www.chatpdf.com/?via=ai-papers (affiliate)
All credit for the research goes to the researchers who wrote the paper we covered in this post.