
NExT-GPT: Any-to-Any Multimodal LLM
In this post we dive into NExT-GPT, a multimodal large language model (MM-LLM), that can both understand and respond with multiple modalities
In this post we dive into NExT-GPT, a multimodal large language model (MM-LLM), that can both understand and respond with multiple modalities

In this post we dive into the Large Language Models As Optimizers paper by Google DeepMind, which introduces OPRO (Optimization by PROmpting).
Large Language Models As Optimizers – OPRO by Google DeepMind Read More »
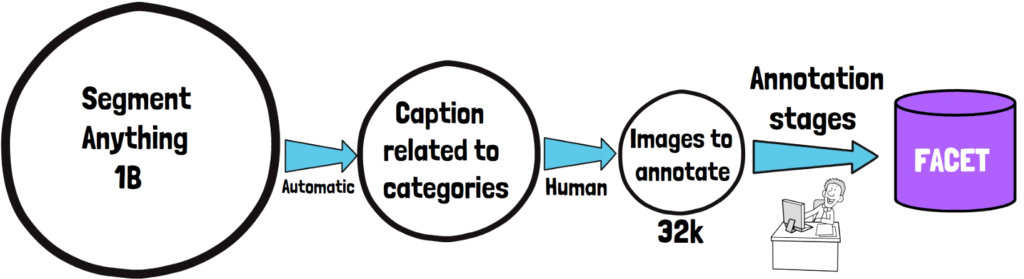
In this post we cover FACET, a new dataset created by Meta AI in order to evaluate a benchmark for fairness of computer vision models
FACET: Fairness in Computer Vision Evaluation Benchmark Read More »

Discover an in-depth review of Code Llama paper, a specialized version of the Llama 2 model designed for coding tasks
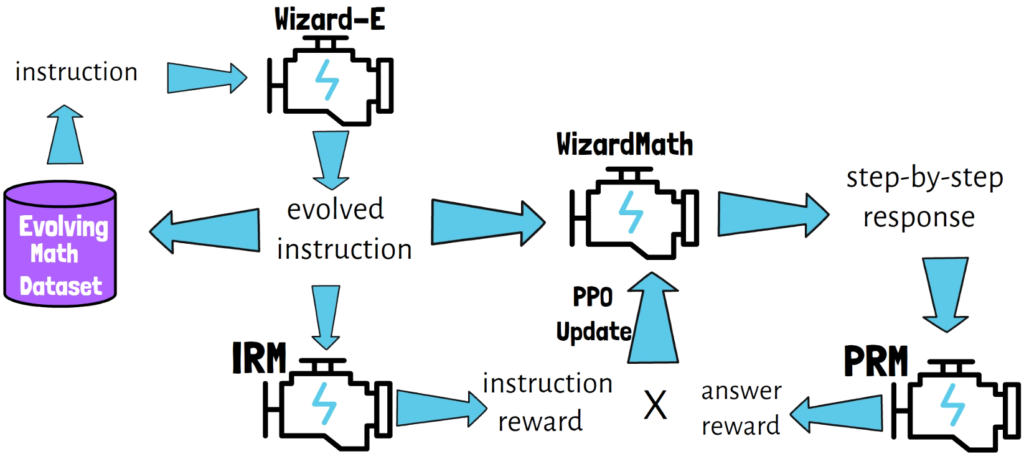
Diving into WizardMath, a LLM for mathematical reasoning contributed by Microsoft, surpassing models such as WizardLM and LLaMA-2.

In this post we dive into Orca’s paper which shows how to do imitation tuning effectively, outperforms ChatGPT with about 7% of its size!
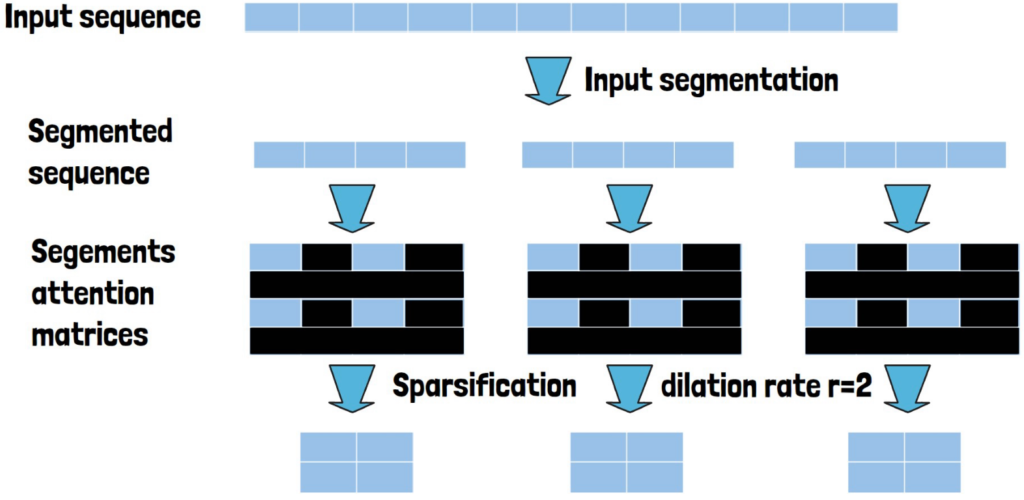
In this post we dive into the LongNet research paper which introduced the Dilated Attention mechanism and explain how it works
LongNet: Scaling Transformers to 1B Tokens with Dilated Attention Read More »
DINOv2 by Meta AI finally gives us a foundational model for computer vision. We’ll explain what it means and why DINOv2 can count as such
DINOv2 from Meta AI – A Foundational Model in Computer Vision Read More »

Dive into I-JEPA, Image-based Joint-Embedding Predictive Architecture, the first model based on Yann LeCun’s vision for a more human-like AI.
I-JEPA: The First Human-Like Computer Vision Model Read More »
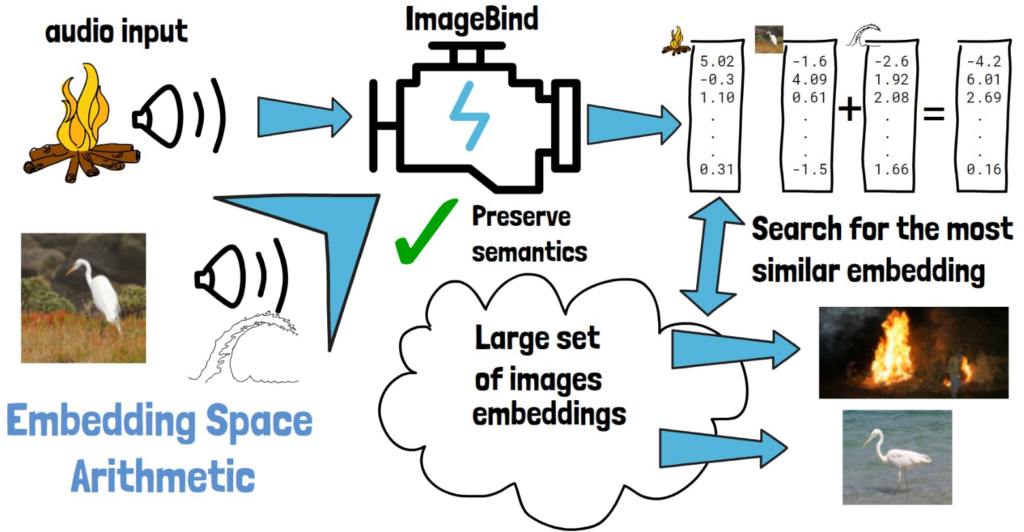
ImageBind is a multimodality model by Meta AI. In this post, we dive into ImageBind research paper to understand what it is and how it works.