Mixture of Nested Experts: Adaptive Processing of Visual Tokens
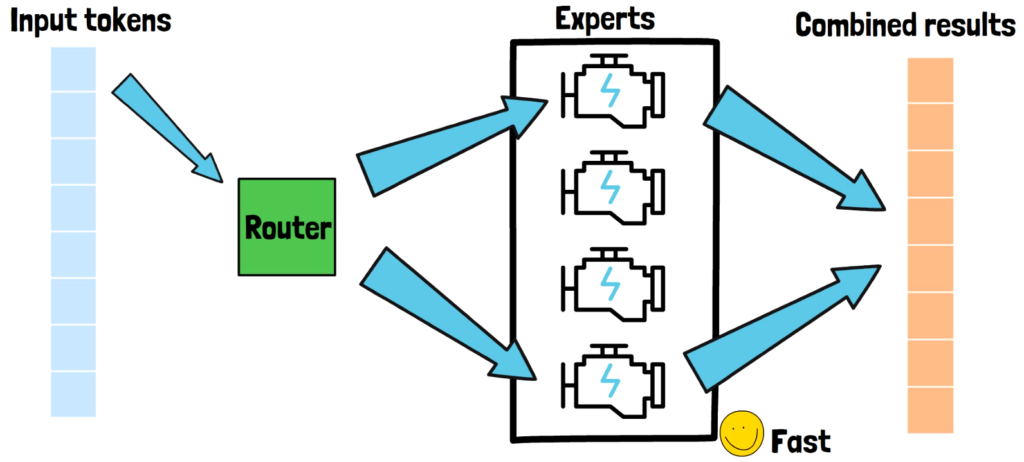
In this post we dive into Mixture of Nested Experts, a new method presented by Google that can dramatically reduce AI computational cost
Mixture of Nested Experts: Adaptive Processing of Visual Tokens Read More »