
On January 18, Mark Zuckerberg announced that the long-term goal of Meta AI is to build general intelligence, and open-source it responsibly. So Meta AI is officially working on building an open-source AGI. On the same day, Meta AI have released a new research paper titled “Self-Rewarding Language Models”, which can be a step that takes Meta AI forward in this direction.
Before diving in, if you prefer a video format then check out the following video:
Motivation
Pre-trained large language models are being improved by getting feedback about the model output from humans, and then train on that feedback. This paper suggests that in order to reach superhuman agents, future models require superhuman feedback. This approach by itself is not completely new as there are already methods that use large language models to be the ones the provide the feedback, such as Reinforcement Learning from AI Feedback. However, what’s novel here is that the model providing the feedback for the model outputs is actually the same model. In this post we’ll explain the paper to understand how it works.
Essential Background
We’ll start with the high-level idea behind self-rewarding language models, so we’ll know where we’re going to when diving deeper into the details. But before that, in order to understand the high-level idea we first need to do a quick recap for RLHF and DPO.
RLHF & RLAIF Recap

With reinforcement learning from either human feedback (RLHF) or AI feedback (RLAIF), we have a pre-trained large language model, which we use to generate responses. The responses are then evaluated by human or by a different model, in order to produce a dataset of evaluated responses, where each sample has an instruction, a negative response, and a positive response. We then train a reward model based on that data, that learns to rank the LLM responses. Then the LLM is trained using the reward model, mostly via PPO, in order to yield outputs with high ranking.
DPO Recap
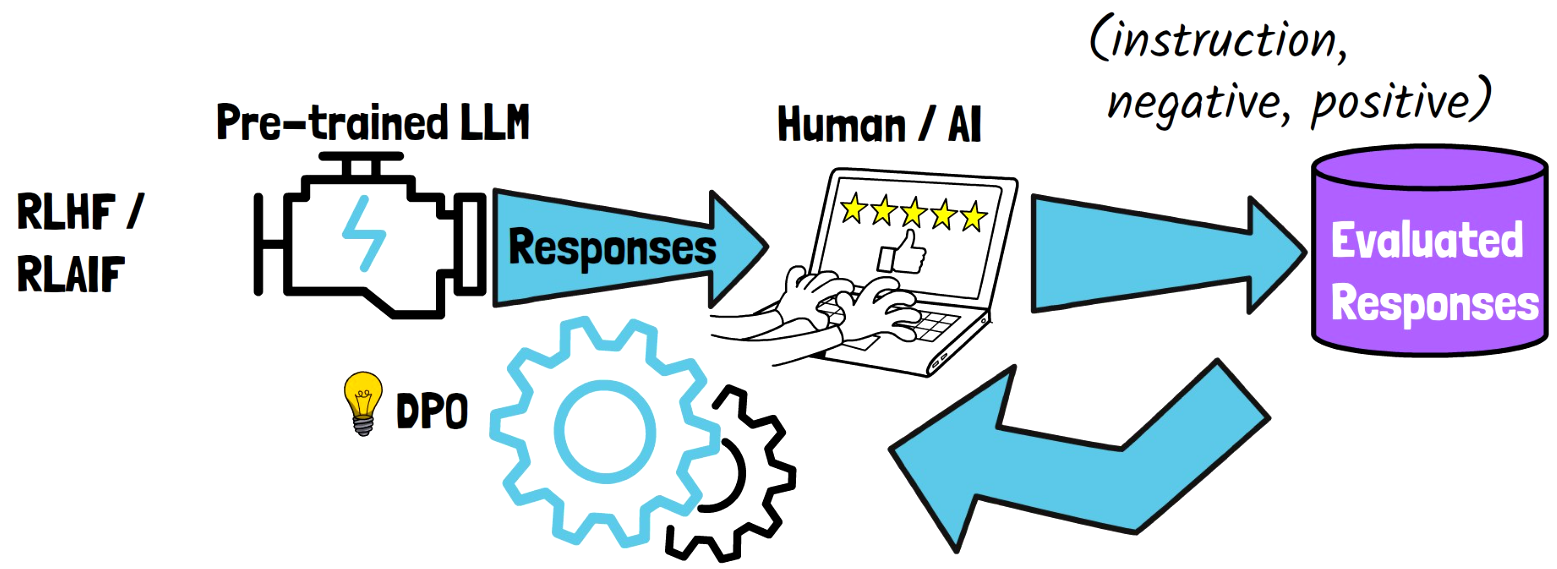
More recently, Direct Preference Optimization (DPO) was introduced. With DPO, the need for the reward model is removed, meaning we train the LLM using the feedback data directly, without creating a reward model.
Self-Rewarding Language Models High-level Idea
With self-rewarding language models, we also have a pre-trained large language model, and the idea is that the LLM can learn to be a reward model for itself. Same as we fine-tune a LLM to follow instructions, here we do both, so the self-rewarding LLM should both learn to follow instructions and act as a reward model. The LLM is used to generate responses and their evaluations, and then it keeps on training on these evaluated responses iteratively. To make it much clearer we now need to dive into the details of how it is done.
Self-Rewarding Language Models Method Details
Datasets Types used for Training Self-Rewarding Language Models
We start with a pre-trained large language model, referred as M0, and with two initial small datasets.
- IFT – One is an instruction following dataset which is crafted by humans. This dataset is referred as IFT, shortcut for instruction fine-tuning.
- EFT – The second dataset is referred as EFT, shortcut for evaluation fine-tuning, which contains samples that have an evaluation instruction prompt, which is a prompt that asks the model to evaluate the quality of a given response to a particular instruction. And the second part of the sample is an evaluation result response, which determines the score of the response, with reasoning for that decision. The EFT dataset serves as training data for the LLM to fill the role of a reward model.
Self-Rewarding Language Models Initial Training Step
The first step is to fine-tune the M0 model on these two datasets. The model at the end of this stage is called M1.

Improving the Model Iteratively
To understand the remainder of that process we review the following figure from the paper. The figure describes a self-alignment process that consist of iterations, where each iteration has two phases.
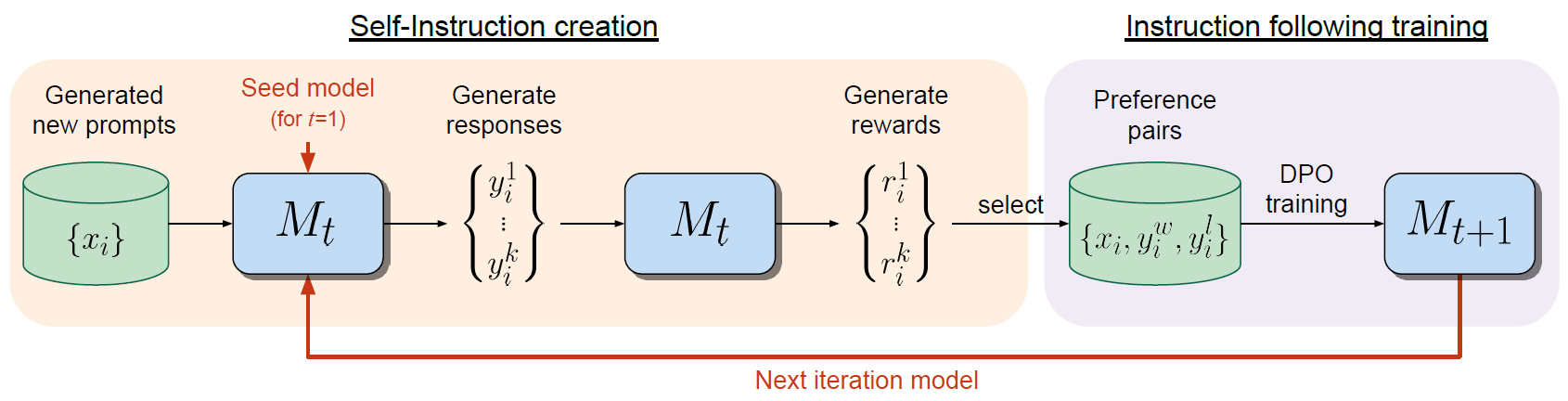
Phase 1 – Self-Instruction Creation
This part is described on the left of the image above. We start with M1, the model we ended after step one. It is written as Mt because it is going to be updated in the next iterations. We use M1, the same LLM, to generate new prompts, that we see on the left. We then generate responses for the generated prompts using M1, again the same LLM. We generate multiple responses for each prompt. We then, again, use the same LLM to generate rewards for the responses. The reward values are between 0 to 5.
Phase 2 – Instruction Following Training
This part is described on the right of the image above. Here, we first create a dataset of preference pairs where for each prompt, we select the responses with the highest and lowest scores as the positive and negative responses. Then, we train M1 model using DPO, and the trained model after this step is called M2. We can then run another iteration, using the M2 model, and so on.
Results
We’re now going to review some of the results presented in the paper. The experiments were done using Llama 2 70B model as the base model, and the two datasets, the IFT and EFT were crafted from the Open Assistant dataset.
Instruction following ability improves with Self-Training

In the above chart from the paper, we can see three versions of the Self-Rewarding process, M1 to M3 are compared with a SFT baseline using GPT-4, where the SFT baseline is the base LLM trained with supervised fine-tuning on the IFT dataset only. On the bottom row, we see that M1 and the SFT baseline are on par. However, we see a significant improvement with M2 and M3. And also noticeable is that M3 achieves better results than M2. An important note here is that while we see improvement when getting up to M3, understanding the impact of proceeding to more iterations is still something that should be investigated. The below chart shows the improvement in instruction following ability when comparing the results of different versions in the self-rewarding process, and we can see that the more advanced versions win previous versions of the model. Specifically in the bottom row we see a significant gap between the M3 version to M1.

Quality of the instruction following ability

In the above table from the paper, we can see results that show the quality of the instruction following ability. In this table we see the win rate over GPT-4 Turbo evaluated using GPT-4. We can see that M3, the third Self-Rewarding version, achieves win rate of approximately 20%, which is better than various other powerful models as we can see at the bottom, such as Claude 2, Gemini Pro and GPT-4 0613, which is very impressive.
Reward modeling ability improves with Self-Rewarding
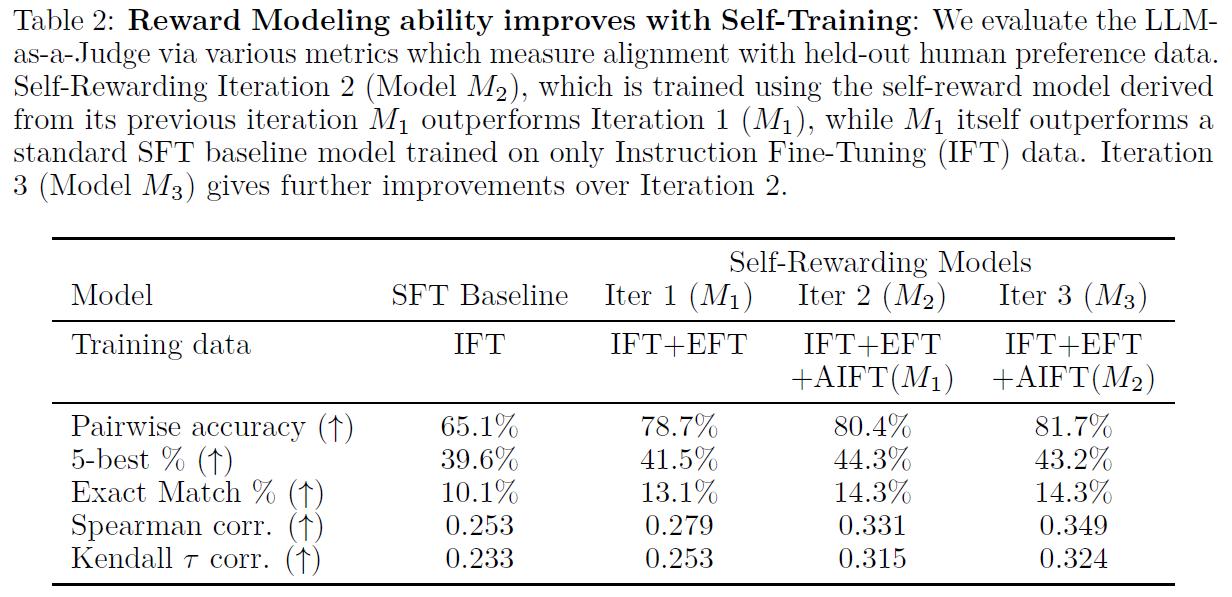
Another interesting result shows that the reward model ability is improved in the Self-Rewarding process. We can see that in the above table from the paper. For example, in the first raw we can see the pairwise accuracy, which is the percentage of times that the order of ranking between any given pair agrees between the model and human rankings. And we can see that the accuracy improves between each version of the model.
References & Links
- Paper – https://arxiv.org/abs/2401.10020
- Video – https://youtu.be/PeSLWTZ1Yg8
- Join our newsletter to receive concise 1 minute read summaries of the papers we review – https://aipapersacademy.com/newsletter/
All credit for the research goes to the researchers who wrote the paper we covered in this post.