In this post, we dive into a new and exciting research paper by Microsoft, titled: “The Era of 1-bit LLMs: All Large Language Models are 1.58 bits”. In recent years, we’ve seen a tremendous success of large language models with models such as GPT, LLaMA and more. As we move forward, we see that the models size is getting larger and larger, and in order to efficiently run large language models we need a substantial amount of compute and memory resources, which are not accessible for most people. Additionally, we also hear environmental concerns due to high energy consumption. And so, an important research domain is to reduce the size of large language models, and this paper takes this effort to the extreme. In this post we’ll explain the paper to understand what are 1-bit LLMs and how it works.

Before diving in, if you prefer a video format then check out the following video:
Reducing Models Size
Let’s start by expanding about how models size can be reduced.
Post-training Quantization

An already very common technique to reduce models size is post-training quantization. With post-training quantization, we take an existing large language model, which due to its large size, is usually consuming high memory and has a long inference time. Quantization in machine learning usually refers to the process of reducing the precision of the model weights, for example converting the model weights from float16 to int8 so each weight is one byte in memory instead of four. This way the models consume less memory and run faster. This however many times comes with a decrease in the model accuracy.
BitNet b1.58
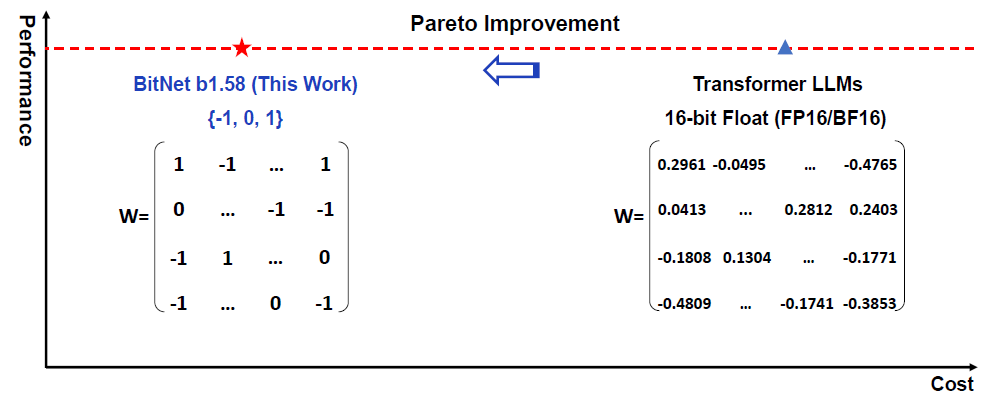
In this paper, the researchers introduce BitNet b1.58, which is a novel model architecture. We can start to learn about it using the above figure from the paper. This chart exemplify the cost on the x axis, and the performance on the y axis.
- Reduce cost, while maintaining performance – On the right, where the cost is higher, we have a weight matrix of a standard transformer LLM, where each weight is a 16-bit float. On the left, where the cost is lower, we have the new BitNet b1.58 model. However, the performance is the same, which we can see with the red dotted line, which makes it super interesting and promising for the future.
- Ternary weights – We can also learn from this figure that the weights are ternary, meaning that every weight is either -1, 0 or 1. Obviously we need less than 16 bits to represent the three possible values. So how many bits are required? The answer is log2(3) which is approximately 1.58, and from here the model’s name. So, the model weights are a bit more than 1 bit.
- Trained from scratch – Another note here is that the model is trained from scratch, and not adapted after the training, so the model learns during training how to work with ternary weights.
BitNet b1.58 Benefits
We now explore some benefits of the BitNet b1.58 model.
Additions Instead Of Multiplications
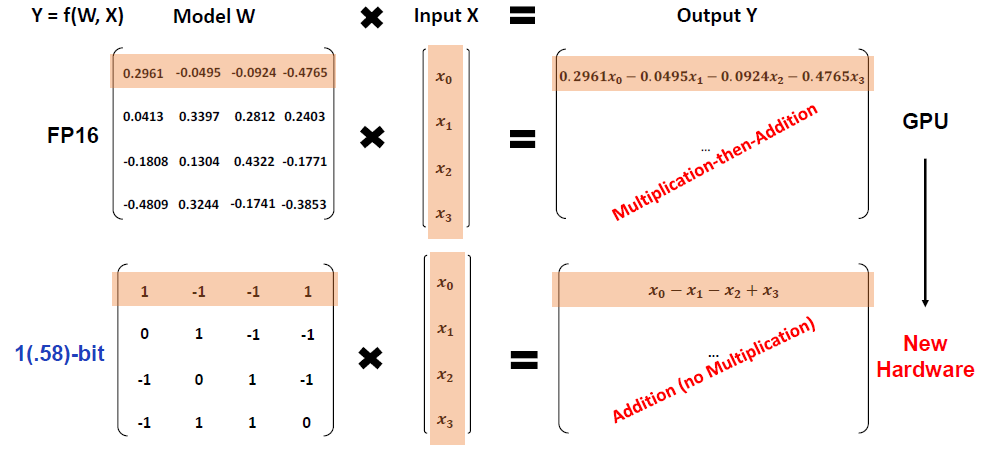
In the above figure from the paper, we can see what are the typical calculations that take place when we run a model. In the upper part, we see a standard transformer weight matrix of float16, multiplied by an input x, in order to yield an output. To calculate the output, the main part of the calculation are multiplications. On the bottom part, we can see the new BitNet model, where again we see a weights matrix with values of -1, 0 and 1. When multiplied by an input vector x, then in order to calculate the output, we now only have additions and not multiplications. Potentially, a new hardware can be invented to be optimized for that type of models.
Features Filtering
This model architecture is a variant of the original BitNet model. In the original BitNet model, each weight was either -1 or 1. The addition of 0 as a possible value is very important since it allows the model to filter out features and can significantly improve the latency.
Reduce Cost Without Performance Penalty
As mentioned earlier, according to the researchers, the new model architecture can match full precision models performance, while dramatically reducing the cost to tun the models. However, while being extremely promising, we need to wait for future research in this area to conclude.
BitNet b1.58 Model Architecture
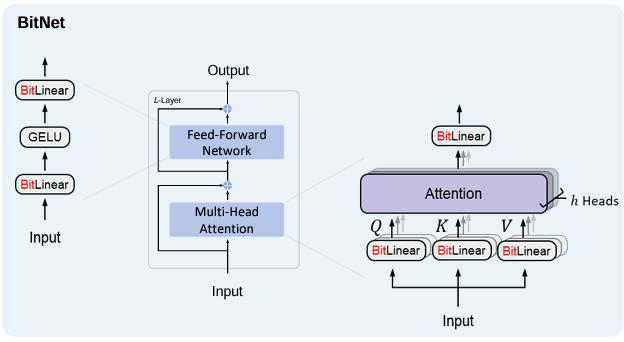
Let’s now dive a bit deeper into how the model is built. The above figure is taken from the original BitNet paper, which has a similar architecture to the BitNet b1.58. We can see that the model architecture has the same layout as transformers, stacking blocks of self-attention and feed-forward networks. But instead of the regular matrix multiplication, we use BitLinear, which is in charge of limiting the model weights to the possible values of {-1, 0, 1}.
Constrain Weights To Ternary Values
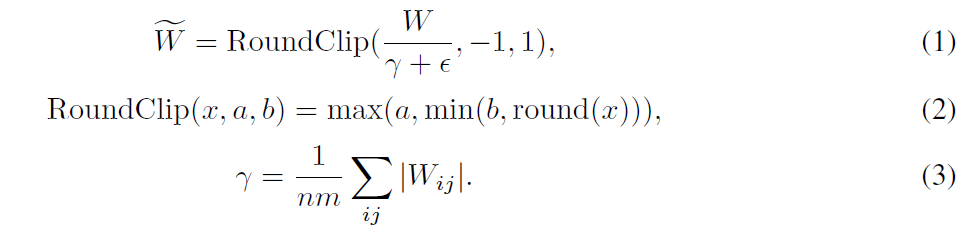
How does the model ensure that the weights will only be -1, 0 or 1? The answer is using absolute mean quantization. While the model is trained, each time we go through the BitLinear layer, we go through the equations above. In simple words:
- We first scale the weight matrix by its average absolute value.
- Then we round each weight to the nearest number among the three possible options.
Results
Let’s move on to explore some of the results presented in the paper. The comparisons are done versus a reproduced LLaMA model.
Reducing cost, while preserving low perplexity
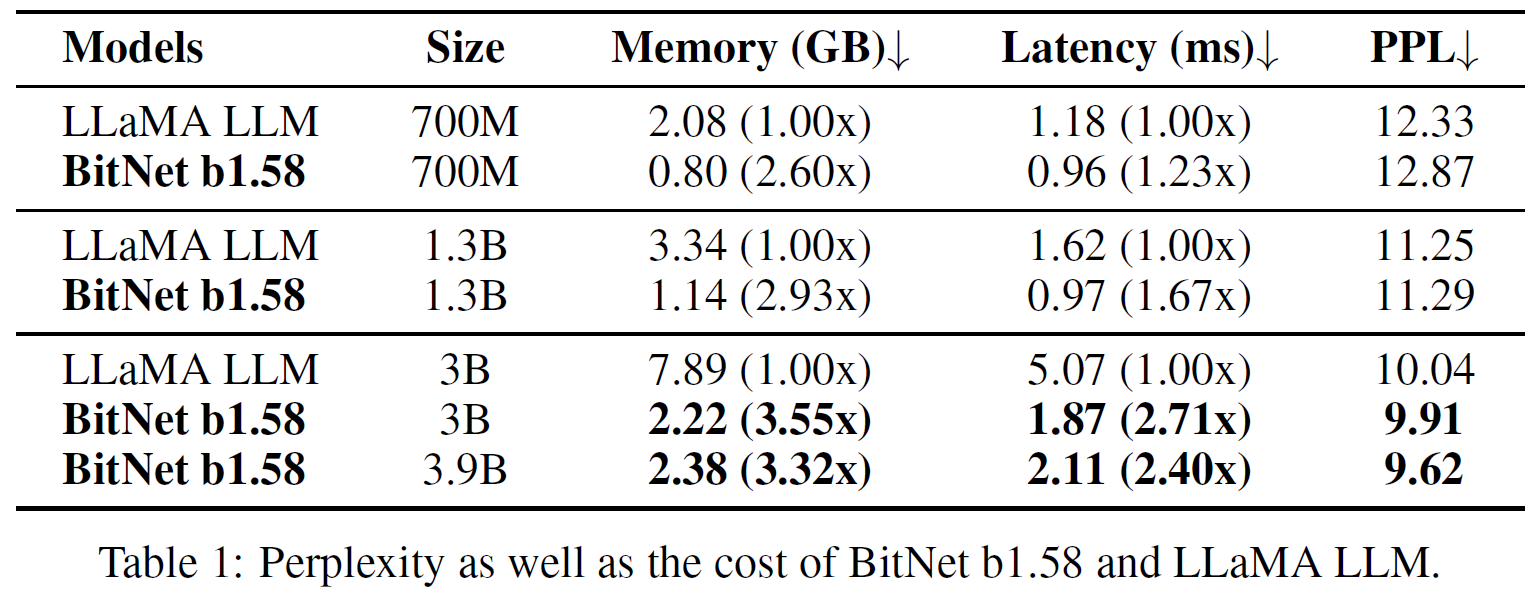
In the above table we can see comparison between the new BitNet model and LLaMA in few sizes. The used memory is much lower as we would expect, most significantly for the 3B version, we see that even with a BitNet of almost another billion params (3.9B) than the LLaMA 3B version, the BitNet model is using 3.3 times less memory. A significant improvement is also observed in the latency, most noticeably for the 3B versions. Interestingly, for the 3B versions, the perplexity is even lower for the BitNet models! Very promising.
Better accuracy results than LLaMA
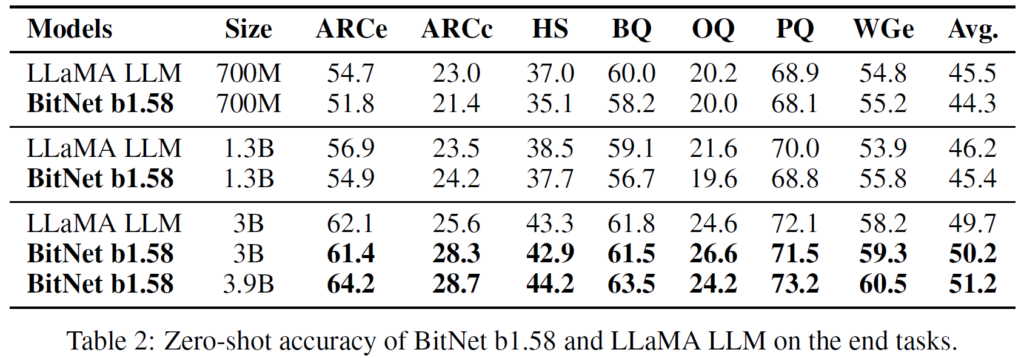
Another interesting table from the paper, shows the accuracy of LLaMA and BitNet on various kinds of tasks, and focusing again on the 3 billion versions, we can see that the BitNet model does not fall behind and is actually a bit better overall.
Cost reduction trend
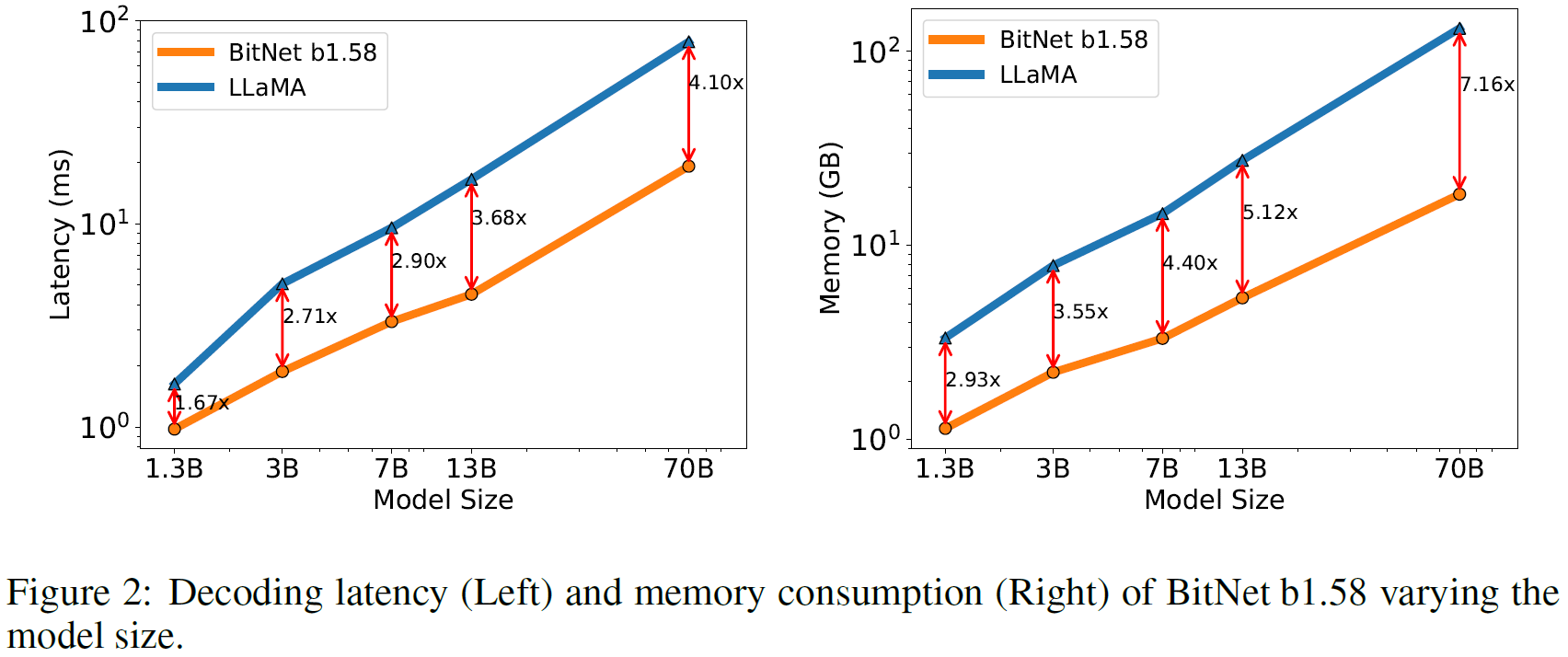
The researchers also trained larger versions of the models, and in the following chart from the paper, we can see the trend of latency and memory, which shows that as the model scales up, the cost reduction also increases. For example, the latency improvement in the 3 billion version is 2.7 while for the 70 billion version it is already 4.1 times faster.
References & Links
- Era of 1-bit LLMs paper page – https://arxiv.org/abs/2402.17764
- Video – https://youtu.be/ZpxQec_3t38
- Original BitNet paper – https://arxiv.org/abs/2310.11453
- Join our newsletter to receive concise 1 minute read summaries of the papers we review – https://aipapersacademy.com/newsletter/
All credit for the research goes to the researchers who wrote the paper we covered in this post.