
In this post we dive into TinyGPT-V, a new multimodal large language model which was introduced in a research paper titled “TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones”.
Before divining in, if you prefer a video format then check out our video review for this paper:
Motivation

In recent years we’ve seen a tremendous progress with large language models (LLMs) such as GPT-4, LLaMA-2 and more, where we can feed a LLM with a prompt and get in response a meaningful answer. More recently, LLMs have been taken another step forward by being able to also understand images. With vision-language models such as the closed source GPT-4V (where V stands for vision) and open source LLaVA and MiniGPT-4, we can now add images to the prompt, and we’ll get a meaningful response that takes both types of inputs into account. However, these models require a substantial amount of resources to run, making them not easily accessible to all people. To overcome that, in this paper the researchers present TinyGPT-V, a smaller vision-language model that needs less resources to run, making it more accessible, yet still impressively powerful.
TinyGPT-V Model Architecture
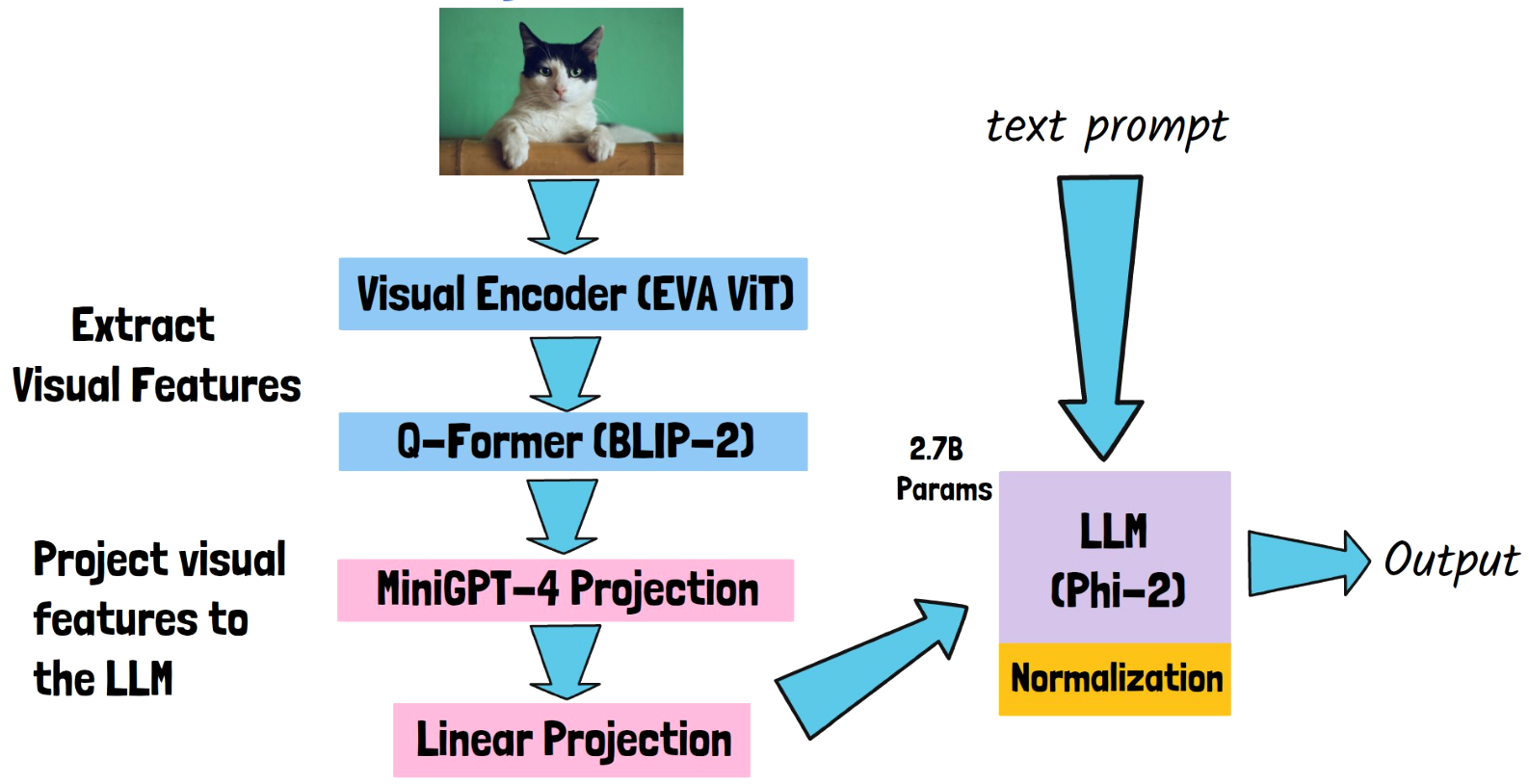
LLM Backbone
The secret sauce that helps TinyGPT-V model to achieve good results while being relatively small, is by using Phi-2 model as its large language model backbone. Phi-2 model has 2.7B params, yet it beats much larger models. The LLM backbone contains most of the TinyGPT-V model params, so using a small LLM such as Phi-2 keeps TinyGPT-V small. The text prompt can be directly fed into the LLM of course, but how do TinyGPT-V leverage Phi-2 for image inputs?
Processing Images with Phi-2
In order to feed an image into Phi-2, we process the image in two stages:
- Extract visual features – We extract visual features from the image in two steps. First, we pass the image via a visual encoder, specifically TinyGPT-V is using a pretrained vision transformer (ViT) from EVA. Second, the visual features are passed via a pre-trained Q-Former from BLIP-2, a component that is trained to align the visual features from the ViT with the text instruction.
- Projection – Once we have the visual features, we need to project them to be in the dimension which Phi-2 can process. We do that using two projection layers. The first is taken from MiniGPT-4 model, in order to save some time in training, and another one that converts the size from MiniGPT-4 to Phi-2. Then, after passing the projection layers, we can feed the embedded features into Phi-2, combined with the text prompt, to get an output with reasoning on both text and image.
We’ll expand a bit more about the training process in a minute, but in the meanwhile we need to mention that the researchers needed to add normalization layers to Phi-2 in order to stabilize the training process, which we can see are part of the architecture drawing above.
TinyGPT-V Trainable Parameters

Many of the components in the TinyGPT-V model are pre-trained, so which parts are trained as part of the TinyGPT-V training? The ViT and Q-Former are kept completely frozen during the entire process. The projection layers, even though one of them is initialized with pre-trained weights from MiniGPT-4 are both trained. Phi-2 is mostly kept frozen, except the added normalization layers which are trained, and additional LoRA weights that are also added. This way the training process is efficient since we don’t need to train a large number of weights.
TinyGPT-V Training Process
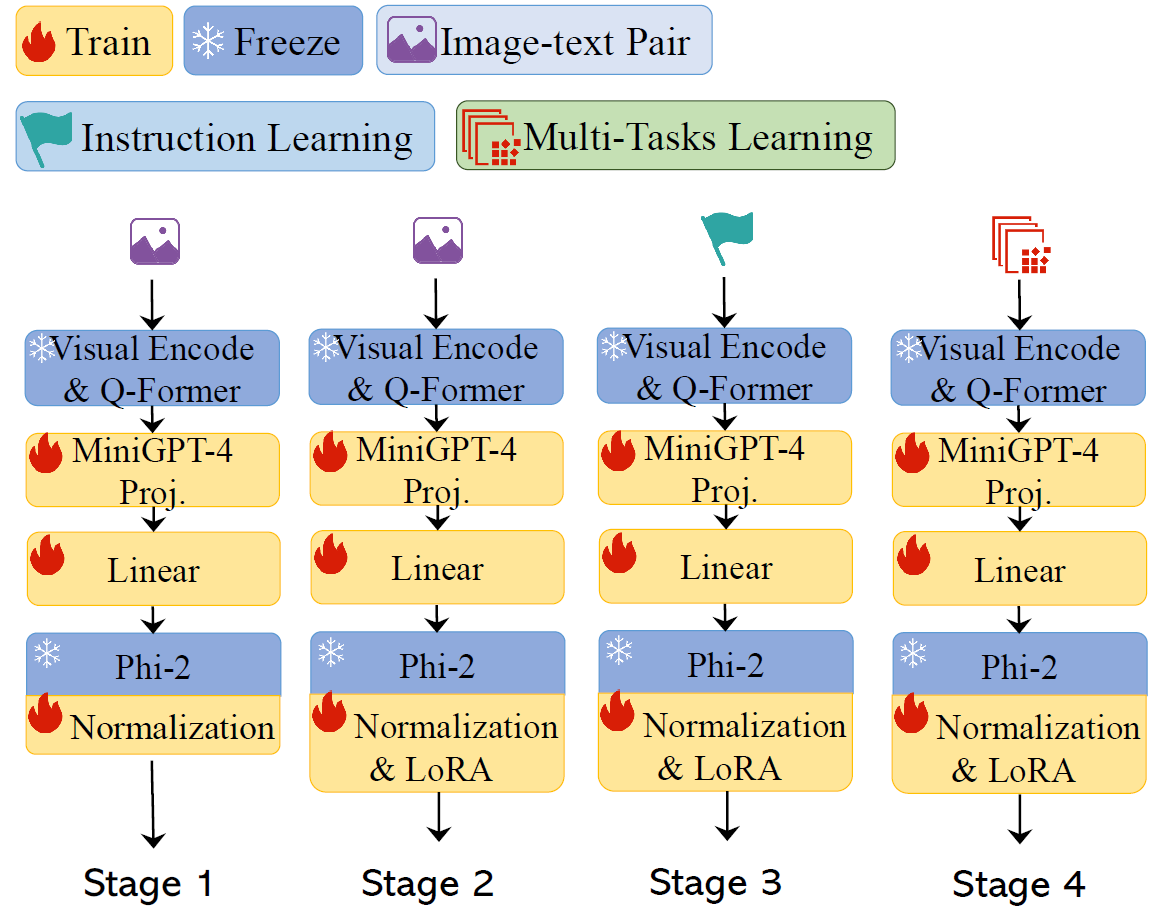
We can learn about the training process from the above figure from the paper, where we see it has 4 training stages.
- Warm-up stage – In the first stage, the model is trained using image-text pairs. The purpose here is to let Phi-2 process images, by processing the output from the projection layers, and create relevant text given the image input.
- Pre-training – The data used in the second stage is the same as in stage 1. So, what is the difference from stage 1? We can notice that in the drawing, that in stage 1 the LoRA weights were not included yet, so the purpose in stage 2 is to train the LoRA weights, but the projection and normalization layers also keep on training here.
- Instruction Learning – The meaning of instructions here is to instructions that contain both images and text. The researchers take such examples from MiniGPT-4 data, and keep on training the trainable components on such instructions.
- Multi-tasks Learning – In the last stage, \the model is trained on multiple datasets for various vision-language tasks.
TinyGPT-V Results

So how does TinyGPT-V performs comparing to other models? In the above figure from the paper, we can see the performance for multiple models on various vision-language tasks. First, it is important to keep in mind here that TinyGPT-V has 2.8 billion params, while the other models here are significantly larger. Flamingo has 9 billion params and the other models here are all with 13 billion params. We can see the TinyGPT-V results on the bottom right, and even though it is of smaller size, it is able to achieve impressive results which are comparable to larger models in various tasks.
References & Links
- Paper page – https://arxiv.org/abs/2312.16862
- Project page – https://github.com/DLYuanGod/TinyGPT-V
- Video – https://youtu.be/9mc_uFLw67c
- Join our newsletter to receive concise 1 minute read summaries of the papers we review – https://aipapersacademy.com/newsletter/
All credit for the research goes to the researchers who wrote the paper we covered in this post.