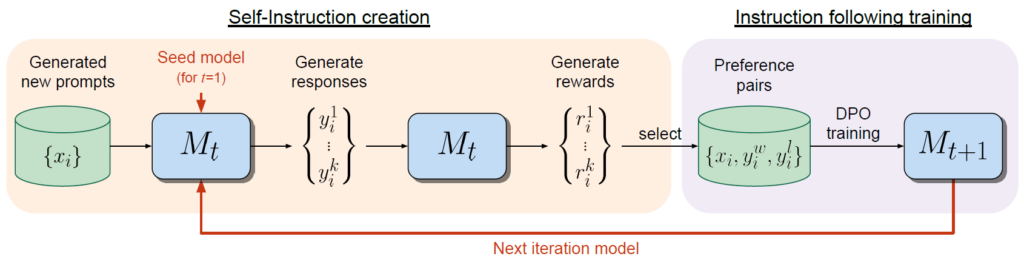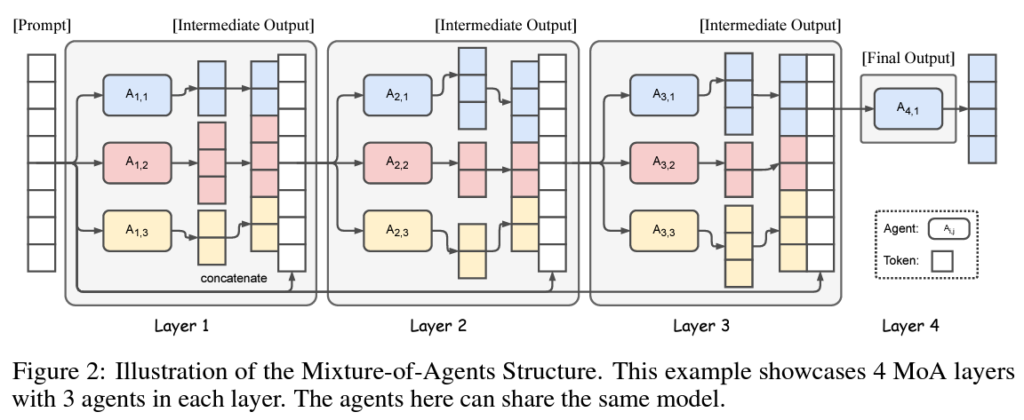
Mixture-of-Agents Enhances Large Language Model Capabilities
In this post we explain the Mixture-of-Agents method, which shows a way to unite open-source LLMs to win GPT-4o on AlpacaEval 2.0
Mixture-of-Agents Enhances Large Language Model Capabilities Read More »