
Orca 2: Teaching Small Language Models How to Reason
Dive into Orca 2 research paper, the second version of the successful Orca small language model from Microsoft,
Orca 2: Teaching Small Language Models How to Reason Read More »
Dive into Orca 2 research paper, the second version of the successful Orca small language model from Microsoft,
Orca 2: Teaching Small Language Models How to Reason Read More »

In this post we dive into Microsoft’s CODEFUSION, an approach to use diffusion models for code generation that achieves remarkable results
CODEFUSION: A Pre-trained Diffusion Model for Code Generation Read More »
In this post we dive into Table-GPT, a novel research by Microsoft, that empowers LLMs to understand tabular data

In this post we dive into the Large Language Models As Optimizers paper by Google DeepMind, which introduces OPRO (Optimization by PROmpting).
Large Language Models As Optimizers – OPRO by Google DeepMind Read More »

Discover an in-depth review of Code Llama paper, a specialized version of the Llama 2 model designed for coding tasks
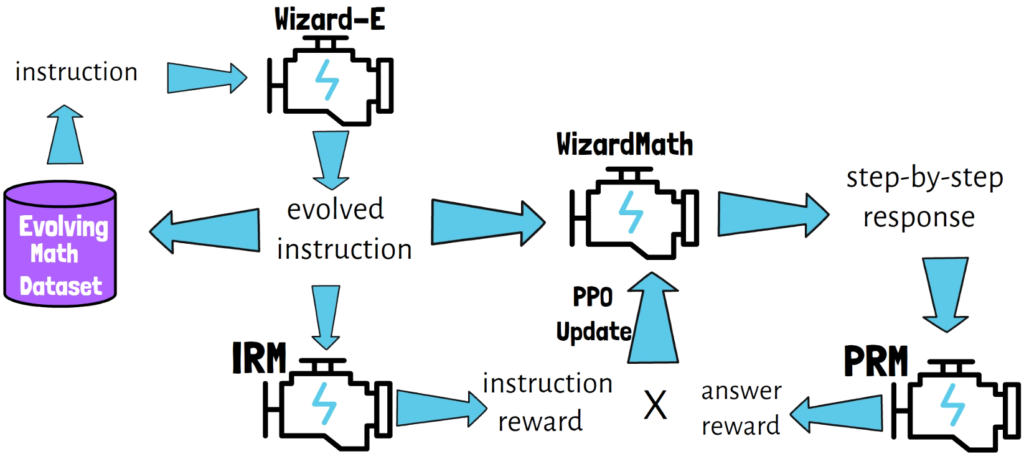
Diving into WizardMath, a LLM for mathematical reasoning contributed by Microsoft, surpassing models such as WizardLM and LLaMA-2.

In this post we dive into Orca’s paper which shows how to do imitation tuning effectively, outperforms ChatGPT with about 7% of its size!
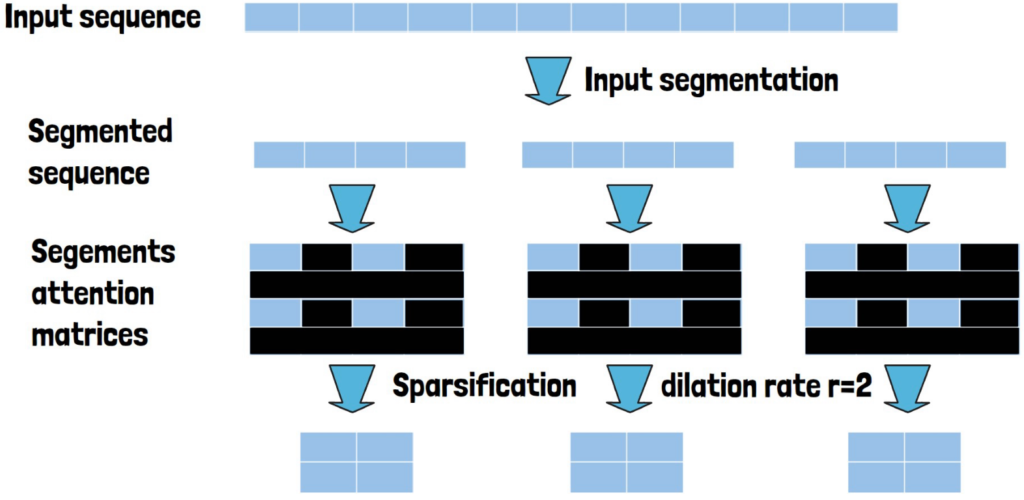
In this post we dive into the LongNet research paper which introduced the Dilated Attention mechanism and explain how it works
LongNet: Scaling Transformers to 1B Tokens with Dilated Attention Read More »

In this post we explain LIMA, a LLM by Meta AI which was fine-tuned on only 1000 samples, yet it achieves competitive results with top LLMs
LIMA from Meta AI – Less Is More for Alignment of LLMs Read More »

Dive into Shepherd, a LLM from Meta AI which is purposed to critique responses from other LLMs, a step in resolving LLMs hallucinations.
Shepherd: A Critic for Language Model Generation Read More »