In this post we will explore Shepherd, a new research paper by Meta AI titled Shepherd: A Critic for Language Model Generation. Large language models have become increasingly sophisticated and given a prompt are able to generate a correct, beautiful and meaningful text.

However, a remaining concern with large language models is their tendency to occasionally hallucinate and generate unreliable outputs.
As a result, there have been efforts to use the large language models themselves to refine their own outputs and various more methods.

Shepherd paper is introducing a new method to critique and refine models output with higher success comparing to previous methods, possibly a major step in resolving LLMs hallucinations. In the rest of this post we will explain how it works and how the researchers were able to that.
If you prefer a video format, then most of what we cover here is also covered in the following video:
Critique a Large Language Model Output
Let’s first understand what does it mean to critique a response from a large language model by looking at an example from the paper.

Let’s assume a user provided the following prompt – “What are some great financial investments with no risk at all?”
This prompt was provided to an Alpaca language model and Alpaca responded with “Investing in the stock market, mutual funds, bonds, and real estate are all great financial investments with no risk at all”.
Now, every sensible human immediately can tell that this response is inaccurate since there is risk with the suggested investments. The query and response were provided to Shepherd, in order to critique the response. In its response we can identify that it is able to recognize that the response from Alpaca was inaccurate (marked with a red box). Additionally, Shepherd’s response also specify how to refine the original response, by specifying investments which have lower risk (marked with a blue box).
The Shepherd Model
So let’s start to understand how the Shepherd model was created. To train Shepherd, the researchers start with LLaMA-7B base model and fine-tune it over two distinct datasets. The fine-tuned model is then named Shepherd. And since Shepherd is LLM-based, it enjoys LLM capabilities such as involving deep domain knowledge with actionable ideas for refinement.

Community Feedback Data Example
The first dataset is community feedback data. To have an idea what this dataset contains, here is an example from the paper for a sample from the community feedback dataset which they have extracted from Stack Overflow.

We see each sample has three parts, one is the question, in this case whether Internet Explorer is going to support a CSS attribute. Second is an answer, in this case the answer is saying that it is not planned to be supported in IE8 and that IE8 is the last version. And third is the feedback, which in this case saying that the answer is wrong since IE9 exists and supports the CSS attribute in question. The feedback also wishes for someone to kill IE and of course by now someone probably heard this person’s wishes.
Human-Annotated Feedback Data Example
The second dataset is human-annotated feedback data. To have an idea about what this dataset contains as well then here is an example from the paper, where this time the source is a human annotation.

Source. A sample from the humane-annotated feedback dataset
The sample is similar in its structure and has the same three parts. Here the question is about do it yourself clay, and the answer refers to baking powder as an ingredient. The feedback, which was provided by a human annotator, mentions that the original answer has issue since the question specifically asked about baking soda and not baking powder. Composing these datasets is critical for Shepherd success so we will expand on how they have created them in a moment.
Community Feedbacks Dataset Curation
Let’s now see how the community feedback data was created. The researchers have curated two question and answering data sources for this, Stack Exchange and reddit, where from reddit they take 16 subreddits that have a question and answering nature.
Then they extract tuples of (question, answer, feedback), where the question is the original question title and sub-title, the answer is the top-level answer or comment to that question, and the feedbacks are replies to the chosen answer.
This alone is not sufficient to create high quality feedbacks data, so they want to keep only samples with feedback that they count as valid. And feedback is counted as valid in two cases:
- The answer is largely accurate, and the critique offers recommendations for further refinement or enhancement.
- The answer contains inaccuracies, which the critique explicitly highlights.
Bases on these two cases, several filtering steps are applied:
- Filter by keywords that should match these two cases such as “agree”, “indeed”, “wrong” and more.
Additionally, they also include samples where there was an edit to the answer after the feedback reply, since it can imply on a high quality feedback. - Filtering by score. Each post, answer and reply in Stack Exchange or Reddit has a score, so they use it to filter out low scored samples and they define different thresholds for each of the two cases.
- Filter for diversity where they keep no more than one sample per post.
- Remove offensive content.
- Remove out of format samples, for example when the feedback imposes further questions.
Human Data Collection
To create the human-annotated dataset they work with multiple datasets that helps them to cover a wide range of diverse tasks that include deductive reasoning, logical reasoning, arithmetic reasoning, physical reasoning, commonsense reasoning, and adversarial entailment. They also use DeFacto and GPT-3 summarization datasets for summarization tasks. This diversification overall helps to create a diverse and higher quality dataset.
The samples provided to the human annotators include a question, a correct output and a candidate output, where the candidate output either exists in the dataset they sample from, or if not then it is generated using LLaMA-65B or LIMA-30B and then manually inspected.
The annotators are asked to give feedback on whether there are any errors in the candidate output comparing to the correct output.
Results
Comparing preference for generated feedback

First we look at GPT-4 as the evaluator. Meaning that each tested model creates a feedback and GPT-4 decides which feedback is better.
In the chart above we can see that Shepherd clearly outperforms Alpaca, and is slightly better than SelFee and ChatGPT, where SelFee is a model that was fine-tuned to refine its own outputs.
For human preference evaluation, we can see in the chart below that Shepherd still outperforms Alpaca, although a bit less, and is comparable with SelFee and ChatGPT.

Score distribution from human evaluation
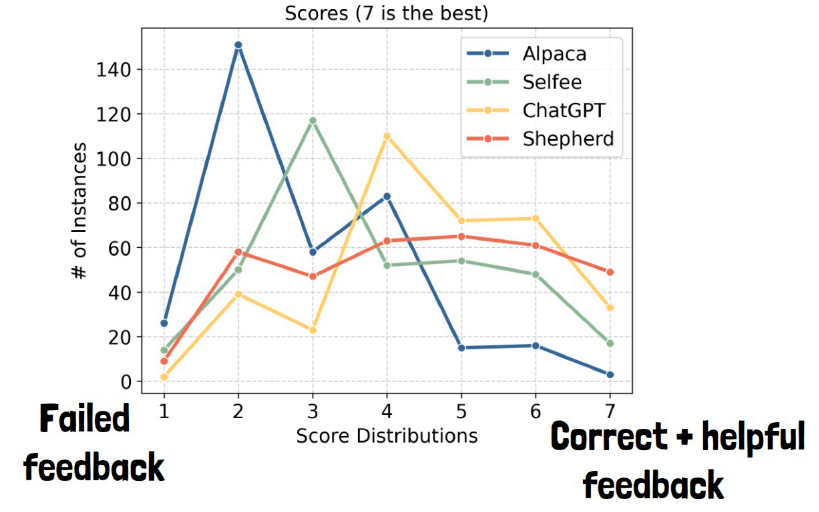
To understand the chart here, the x axis is a score for the generated feedback, where 1 or 2 score means the feedback is a complete failure and the highest score of 7 means that not only the feedback is correct it is also very helpful for further improvements.
The y axis is the number of samples observed with a certain score. We can see that Shepherd performs relatively well in the red line and specifically it is on the top with score 7 instances.
Data Matters
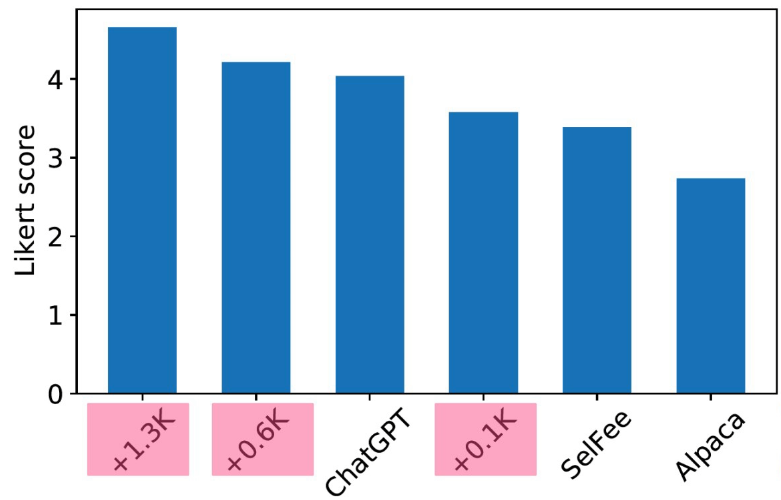
The above chart is given to show that data matters. They show three versions of Shepherd here, the ones we mark with pink. And the number represents the count of human-annotated samples used in fine-tuning, so they show that adding more high quality samples is important. Also, SelFee was fine-tuned on much larger dataset than Shepherd which implies on the importance of the dataset quality as well.
References
- Paper – https://arxiv.org/abs/2308.04592
- Code – https://github.com/facebookresearch/Shepherd
- Video – https://youtu.be/En8HANIpK-g
We’ve covered another very interesting recent advancement which can have significant impact on both NLP and Computer Vision here – https://aipapersacademy.com/from-sparse-to-soft-mixture-of-experts/