
LIMA, Less Is More for Alignment , is a LLM which was created by Meta AI by fine-tuning the LLaMa model on only 1000 samples, and achieved competitive results with top large language models such as GPT-4, Bard and Alpaca. In this post, our goal is to explain the research paper by discussing what the researchers did and why it works.

If you prefer a video format, then most of what we cover in this post is also covered in the following video:
LLM Training Stages
We first need to talk about how large language models come to life. When training large language models there are usually two main stages.
- Pretraining Stage
- Alignment Stage
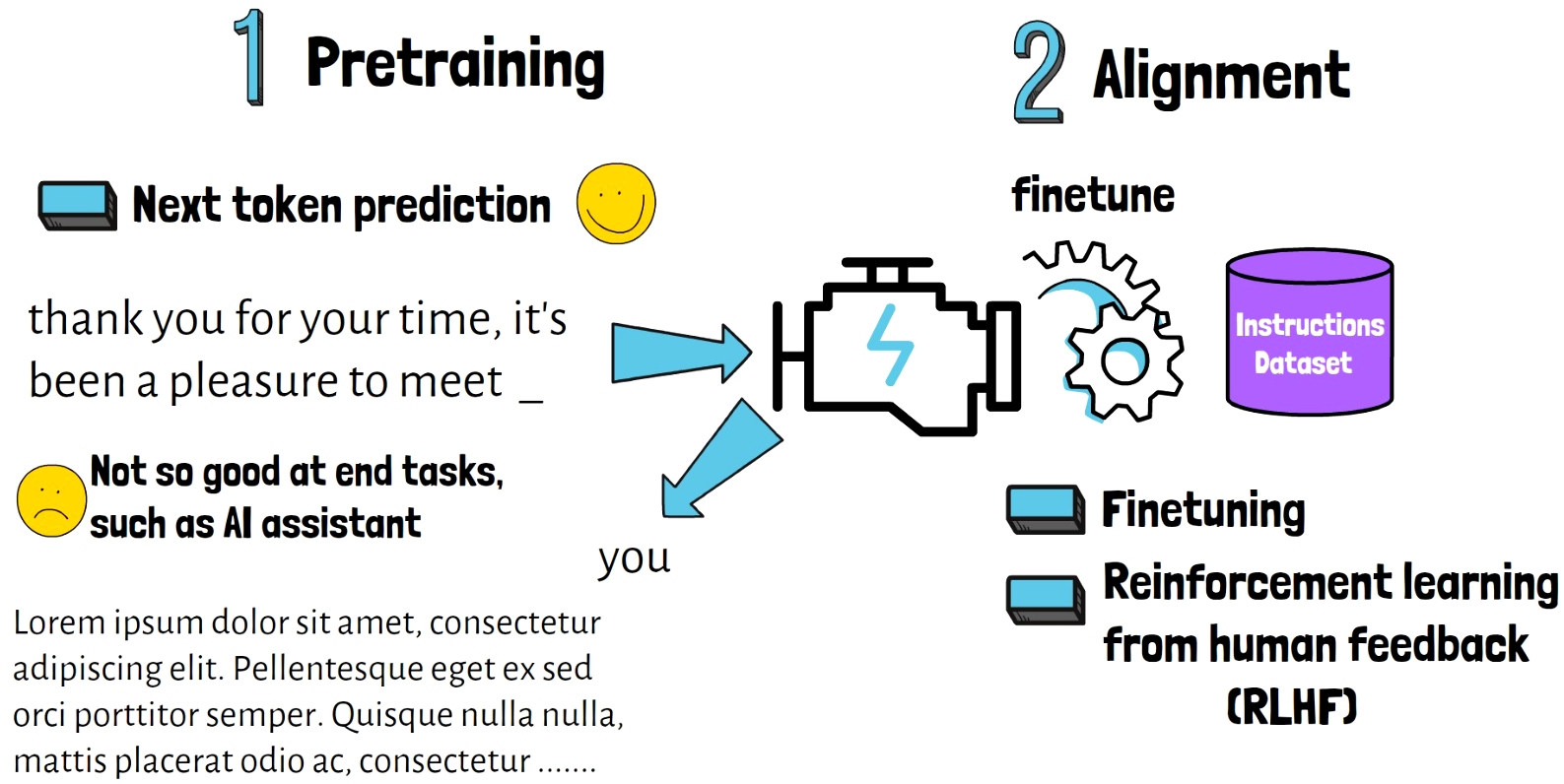
Pretraining Stage
In the first stage, often called pretraining stage, the model is trained on huge amount of text to learn general purpose knowledge. A common technique of doing that is by training the model to predict the next word in a sequence, so given a sentence like “thank you for your time, it’s been a pleasure to meet _” the model learns to yield a proper next word, like “you” in this case.
Once we’re done with this stage, the model is good at completing the next word in a sequence, but it is not very good with helping in concrete tasks that large language models are often used for, like being an AI assistant and help with responding to questions. For this reason there is a second stage which is called the alignment stage.
Alignment Stage
In this stage, the pretrained model is being fine-tuned on a specific task dataset such as instructions dataset to learn to respond to instructions in a better way. This stage may also include adjusting the model based on human feedback with reinforcement learning (RLHF), until finally by the end of this stage we get our graduated AI assistant. In fact ChatGPT includes a large scale stage of RLHF where human annotators help the model to improve its results.
How LIMA can improve LLMs training process?
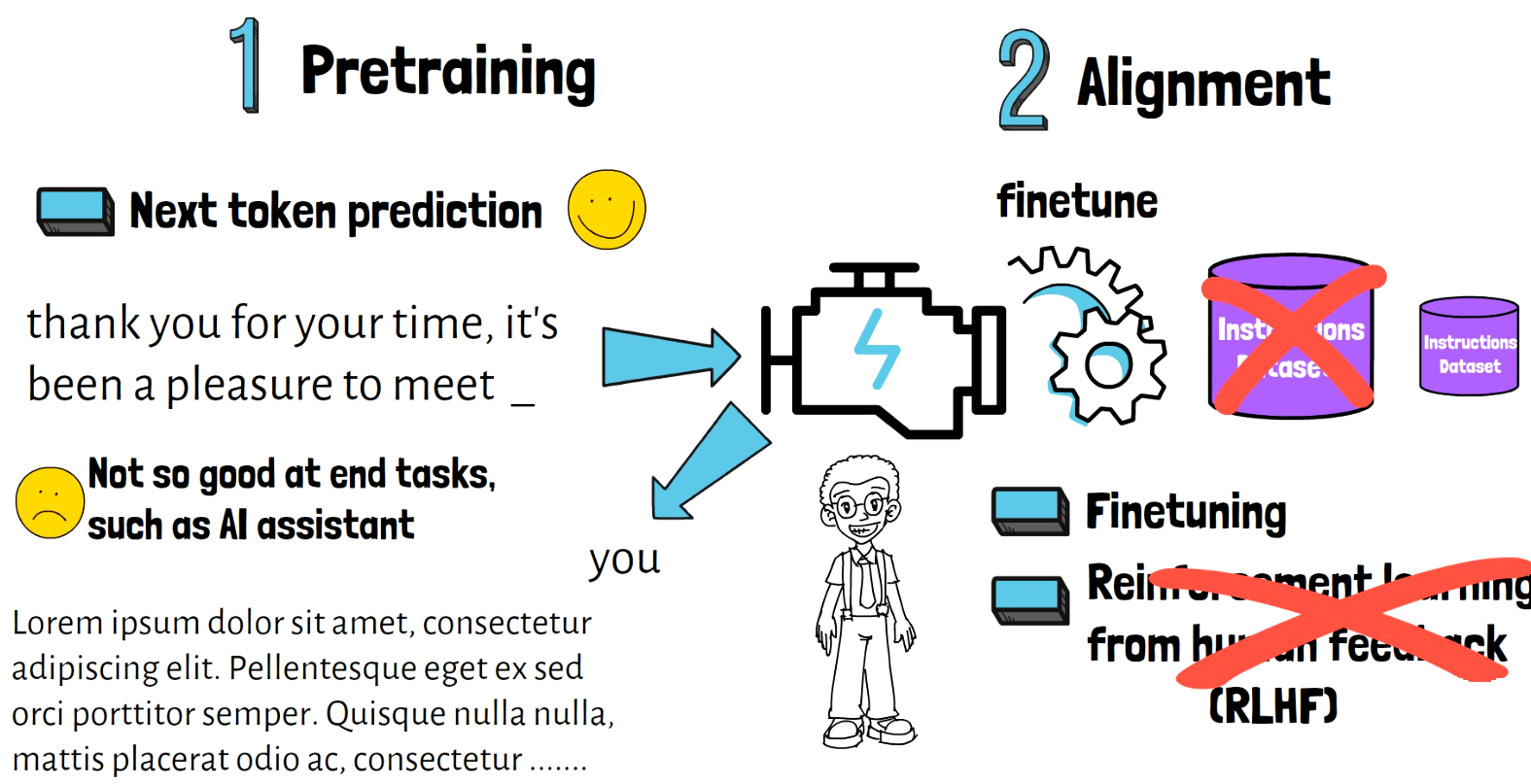
With the LIMA paper, the researchers show that stage two can be replaced with a much more lightweight process of fine-tuning the pretrained model on just a small dataset while still achieving remarkable and competitive results.
This is exciting because whenever the training process is being simplified it gives room for people and organizations with limited resources to be able to compete better with larger organizations.
The paper explains the reasoning for why this works well with what they call the superficial alignment hypothesis.
Superficial Alignment Hypothesis
The superficial alignment hypothesis has a complex name but it claims something pretty simple, that a model’s knowledge and capabilities are learnt almost entirely during pretraining, so if we go back to our two stages, the first stage of pretraining is the king.
The hypothesis also claims that the alignment stage teaches the model what parts of its knowledge should be used when interacting with users, and what format of responses would better align to the end task that we want to solve.
This is contradictory to what we sometimes hear from companies, that the secret sauce is with how they improve the pretrained large language model with methods like RLHF.
In fact, if the hypothesis is correct, then it makes sense for the alignment process to be short, in order to not risk ruining the knowledge of the king pretrained model as part of the alignment process, since as part of this process we’re changing the weights of the pretrained model.
Forgetting some of the learnt knowledge as we continue to train a model is often called catastrophic forgetting, which we want to avoid.

Creating The LIMA Model
In order to try and prove that the hypothesis is correct, the researchers created a small curated dataset of 1000 samples.
They’ve composed the dataset with 750 questions and answers from community forums such as StackExchange and wikiHow. These samples were manually and carefully picked to ensure they are of very high quality and cover a wide area of domains. The other 250 samples were manually written by the researchers.
They’ve then took a pretrained LLaMa model with 65 billion params and fine-tuned it on that dataset with standard supervised learning. They then named the fine-tuned model LIMA. So let’s see how did it go by analyzing some of the results that were published in the paper.
Results
Comparison with other LLMs
The researchers compared responses from their LIMA model with responses from top large language models. They evaluated the results in two methods, one measured by humans that chose the response they prefer given responses from the different models. The other method is letting GPT-4 be the one who chooses the best result.
In both methods, as we can see in the charts below, in the majority of cases responses from LIMA were preferred over results from Alpaca. This is interesting because Alpaca is also a LLaMA-based model same as LIMA, which was fine-tuned on large instructions dataset, so LIMA is able to do better with much smaller dataset for fine-tuning.
Similarly we see that LIMA wins DaVinci003 which is a model from OpenAI that was trained with reinforcement learning from human feedback.
Regarding the strong models BARD, Claude and GPT-4, LIMA does not win them, but they show that they are comparable to them in about 50 percent of the cases which is very impressive given the really small fine-tuning process.
Now one caveat here is that their testing dataset is composed of only 300 samples which is very small in order to prove something. However, the results are still very impressive comparing to what we would expect given the small magnitude of their instructions dataset.

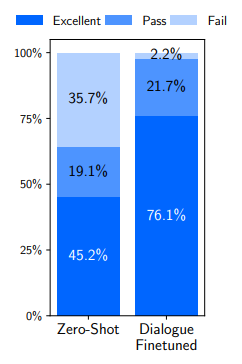
LIMA Dialogue Performance
Another very interesting capability, shown in the chart below, is that LIMA was able to produce good results for dialogues with multiple turns, without observing even one sample for this in fine-tuning. This is the meaning for the title zero shot in the left column, as the model was not prepared for this specifically.
Amazingly, by adding just 30 multi-turn dialogue samples to the finetuning, they dramatically improved the results as we see in the right column.
References & Links
- Paper page – https://arxiv.org/abs/2305.11206
- Video – https://youtu.be/TCAEWap9mSQ
- We use ChatPDF to help us analyze research papers – https://www.chatpdf.com/?via=ai-papers (affiliate)
- Check out additional interesting LLM papers here – https://aipapersacademy.com/category/nlp/
All credit for the research goes to the researchers who wrote the paper we covered in this post.