
Computer Vision Papers
Looking for a specific paper or subject?

DINOv3 Paper Explained: The Computer Vision Foundation Model
In this post we break down Meta AI’s DINOv3 research paper, which introduces a state-of-the-art Computer Vision foundation models family…

Continuous Thought Machines (CTMs) – The Era of AI Beyond Transformers?
Dive into Continuous Thought Machines, a novel architecture that strive to push AI closer to how the human brain works…

Perception Language Models (PLMs) by Meta – A Fully Open SOTA VLM
Dive into Perception Language Models by Meta, a family of fully open SOTA vision-language models with detailed visual understanding…

DeepSeek Janus Pro Paper Explained – Multimodal AI Revolution?
Dive into DeepSeek Janus Pro, another magnificent open-source release, this time a multimodal AI model that rivals top multimodal models!…

Sapiens by Meta AI: Foundation for Human Vision Models
In this post we dive into Sapiens, a new family of computer vision models by Meta AI that show remarkable advancement in human-centric tasks!…
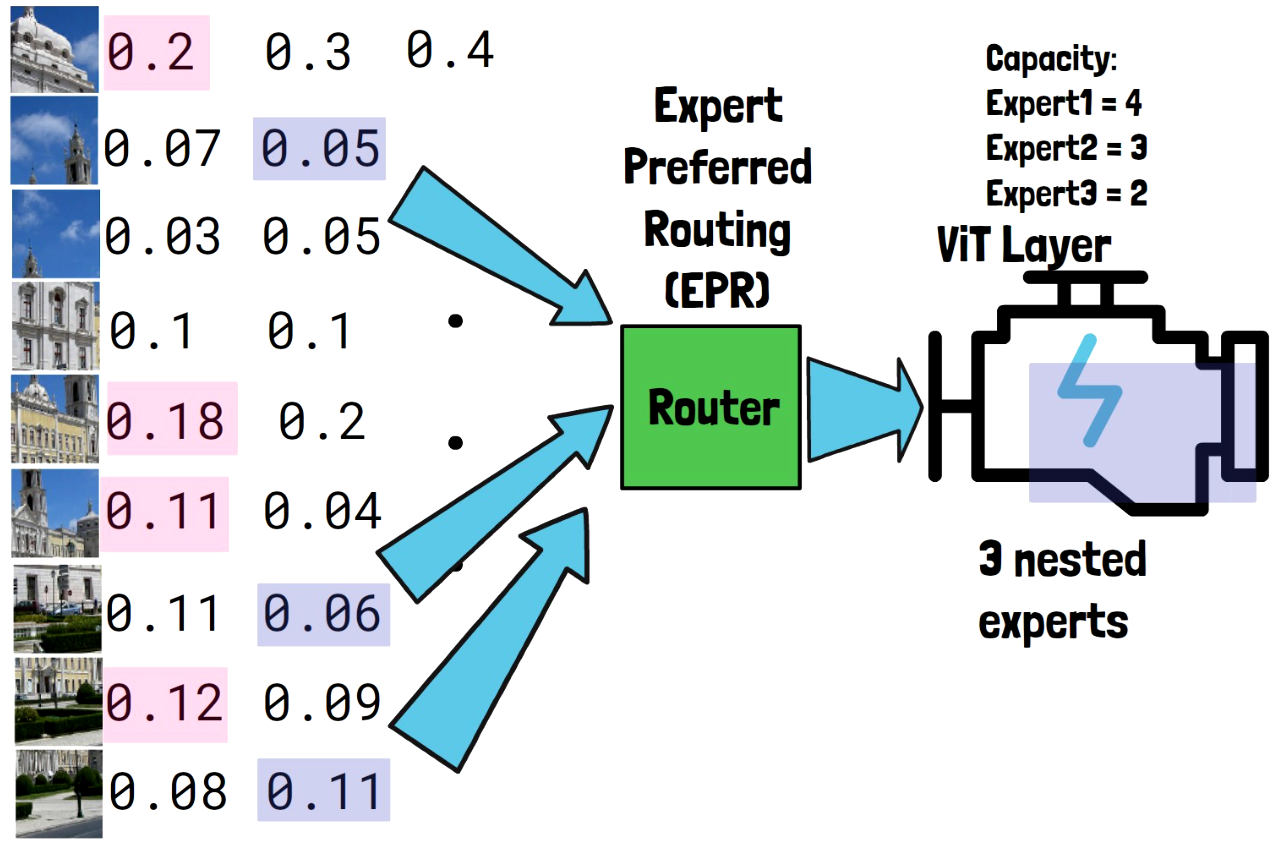
Mixture of Nested Experts: Adaptive Processing of Visual Tokens
In this post we dive into Mixture of Nested Experts, a new method presented by Google that can dramatically reduce AI computational cost…
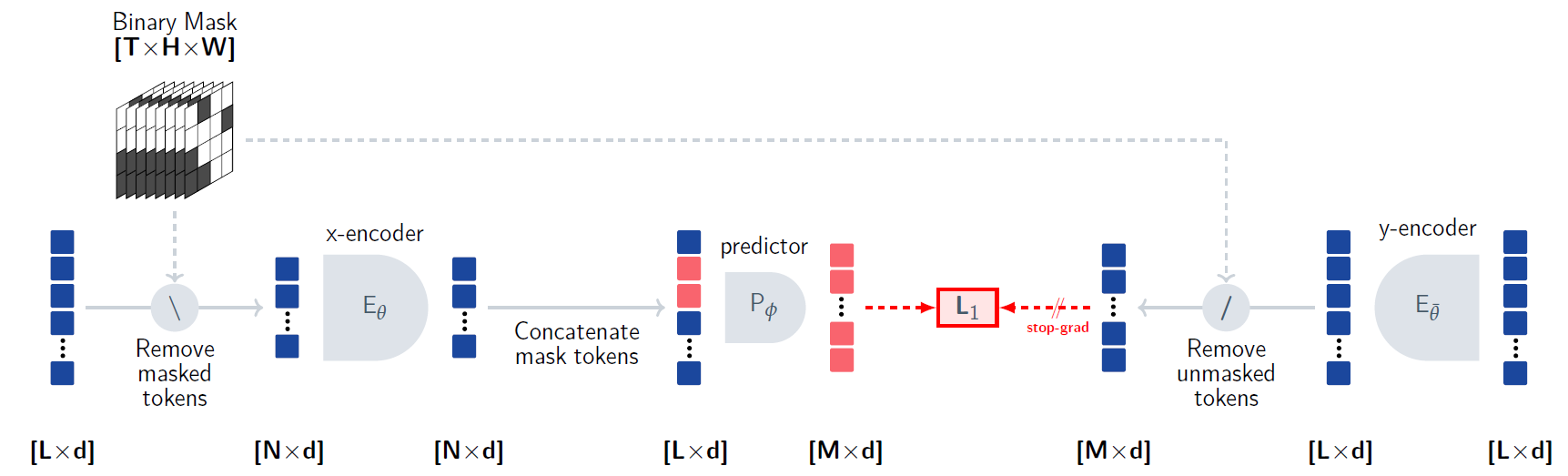
How Meta AI ‘s Human-Like V-JEPA Works?
Explore V-JEPA, which stands for Video Joint-Embedding Predicting Architecture. Another step in Meta AI’s journey for human-like AI…
Vision Transformers Explained | The ViT Paper
In this post we go back to the important vision transformers paper, to understand how ViT adapted transformers to computer vision…
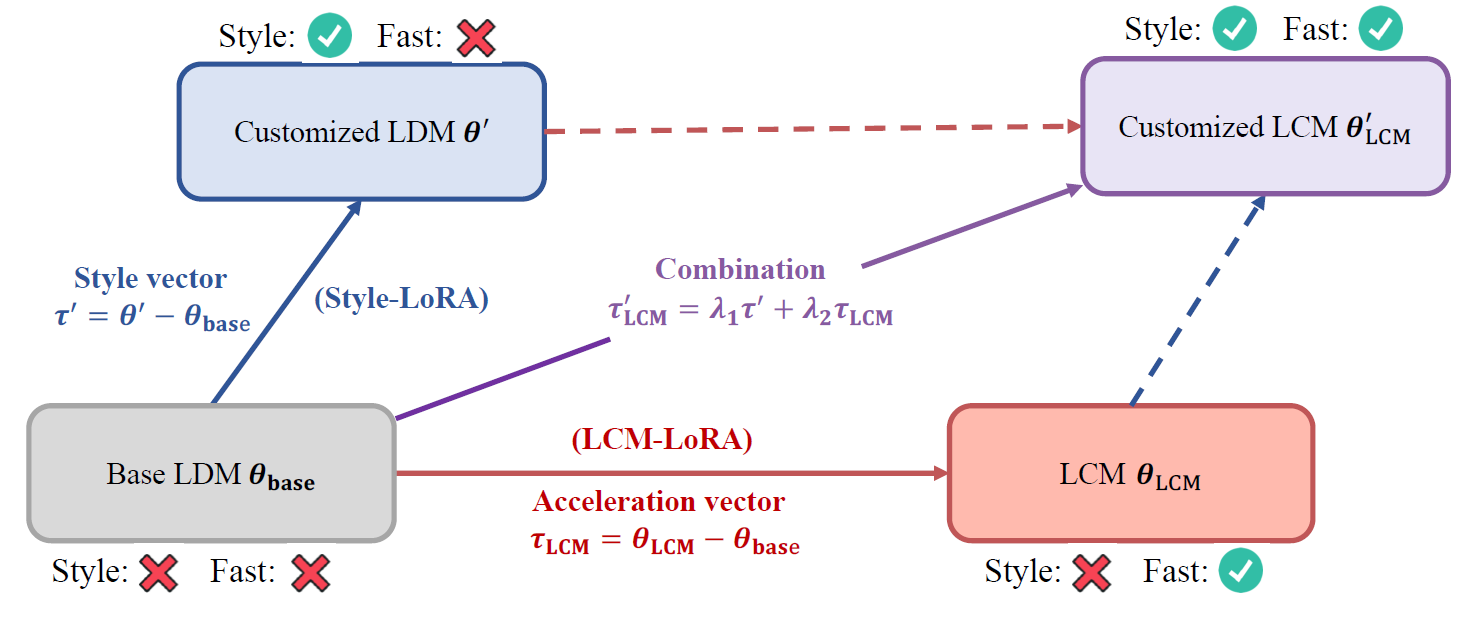
From Diffusion Models to LCM-LoRA
Following LCM-LoRA release, in this post we explore the evolution of diffusion models up to latent consistency models with LoRA…

Vision Transformers Need Registers – Fixing a Bug in DINOv2?
In this post we explain the paper “Vision Transformers Need Registers” by Meta AI, that explains an interesting behavior in DINOv2 features…

Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
In this post we dive into Emu, a text-to-image generation model by Meta AI, which is quality-tuned to generate highly aesthetic images…
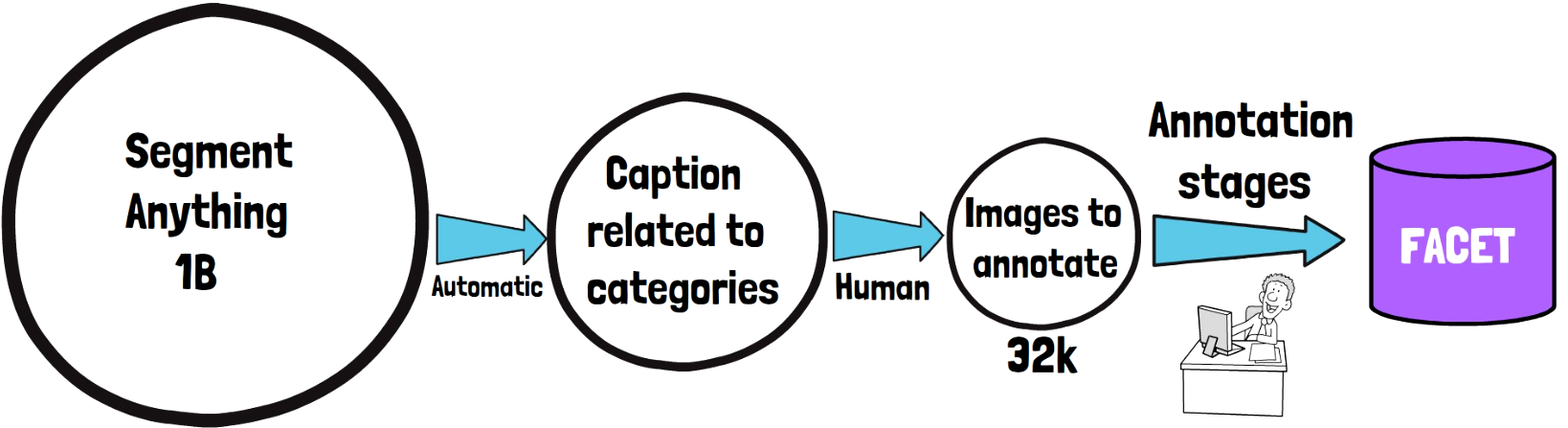
FACET: Fairness in Computer Vision Evaluation Benchmark
In this post we cover FACET, a new dataset created by Meta AI in order to evaluate a benchmark for fairness of computer vision models…
DINOv2 from Meta AI – A Foundational Model in Computer Vision
DINOv2 by Meta AI finally gives us a foundational model for computer vision. We’ll explain what it means and why DINOv2 can count as such…

I-JEPA: The First Human-Like Computer Vision Model
Dive into I-JEPA, Image-based Joint-Embedding Predictive Architecture, the first model based on Yann LeCun’s vision for a more human-like AI…

Consistency Models – Optimizing Diffusion Models Inference
Consistency models are a new type of generative models which were introduced by Open AI, and in this post we will dive into how they work…
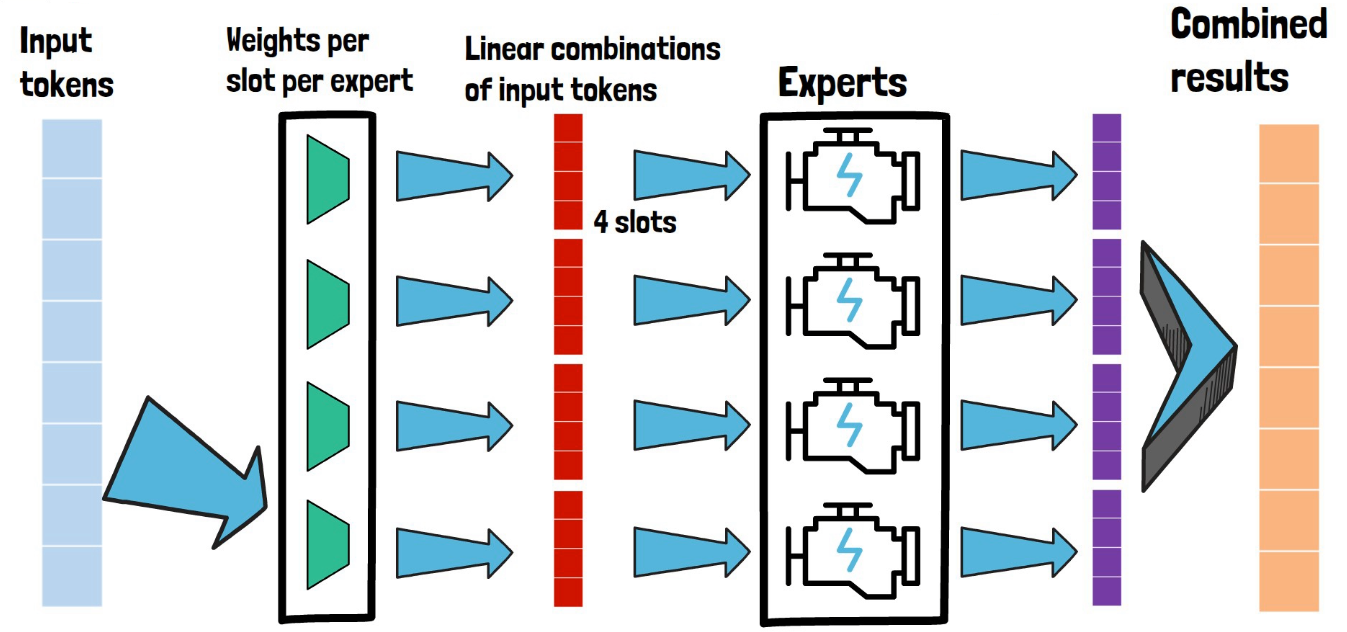
From Sparse to Soft Mixture of Experts
In this post we review Google DeepMind’s paper that introduces Soft Mixture of Experts, a fully-differentiable sparse Transformer…

What is YOLO-NAS and How it Was Created
YOLO-NAS is an object detection model with the best accuracy-latency tradeoff to date. In this post we explain how it was created…