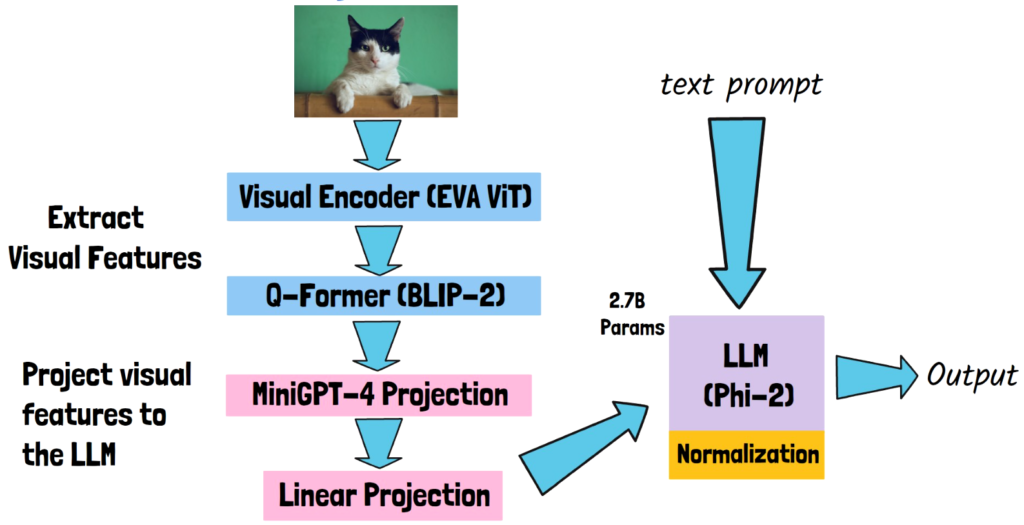
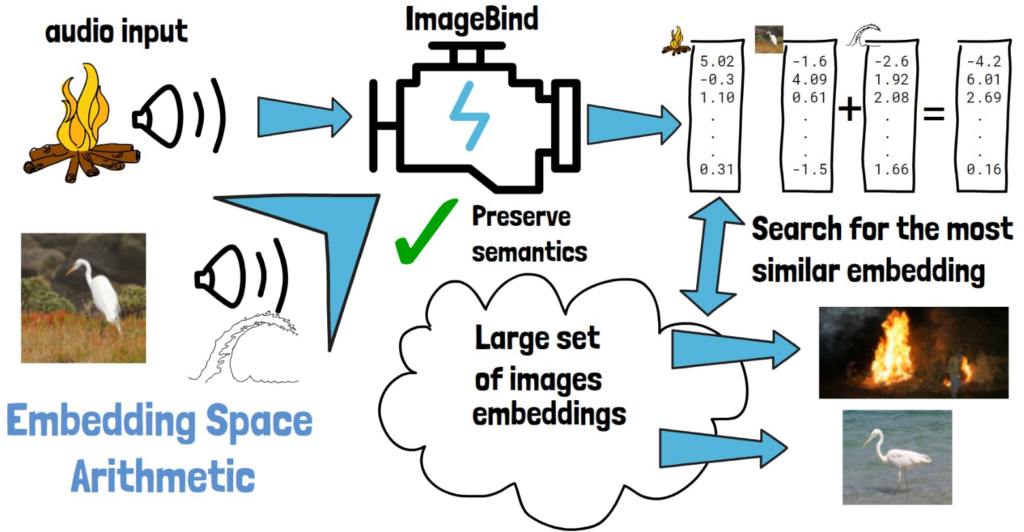
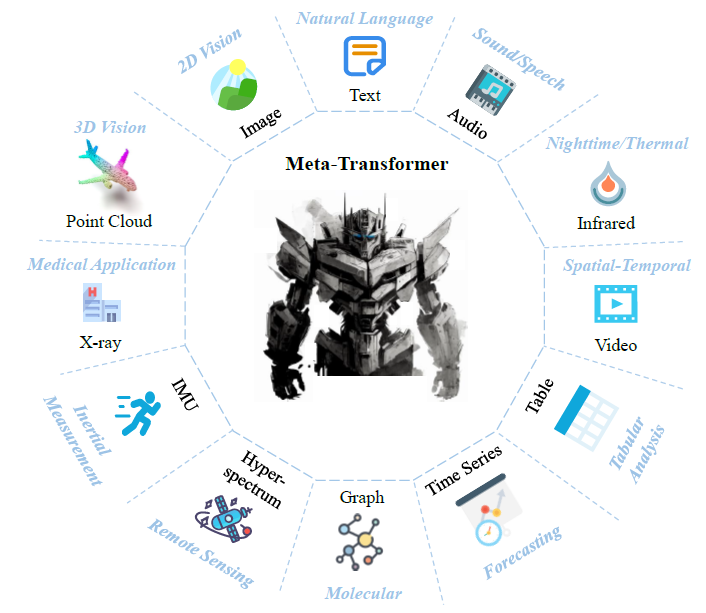
Continuous Thought Machines (CTMs) – The Era of AI Beyond Transformers?
Dive into Continuous Thought Machines, a novel architecture that strive to push AI closer to how the human brain works
Continuous Thought Machines (CTMs) – The Era of AI Beyond Transformers? Read More »