
Multimodality Papers
Looking for a specific paper or subject?

Continuous Thought Machines (CTMs) – The Era of AI Beyond Transformers?
Dive into Continuous Thought Machines, a novel architecture that strive to push AI closer to how the human brain works…

Perception Language Models (PLMs) by Meta – A Fully Open SOTA VLM
Dive into Perception Language Models by Meta, a family of fully open SOTA vision-language models with detailed visual understanding…

DeepSeek Janus Pro Paper Explained – Multimodal AI Revolution?
Dive into DeepSeek Janus Pro, another magnificent open-source release, this time a multimodal AI model that rivals top multimodal models!…
Large Concept Models (LCMs) by Meta: The Era of AI After LLMs?
Explore Meta’s Large Concept Models (LCMs) - an AI model that processes concepts instead of tokens. Can it become the next LLM architecture?…
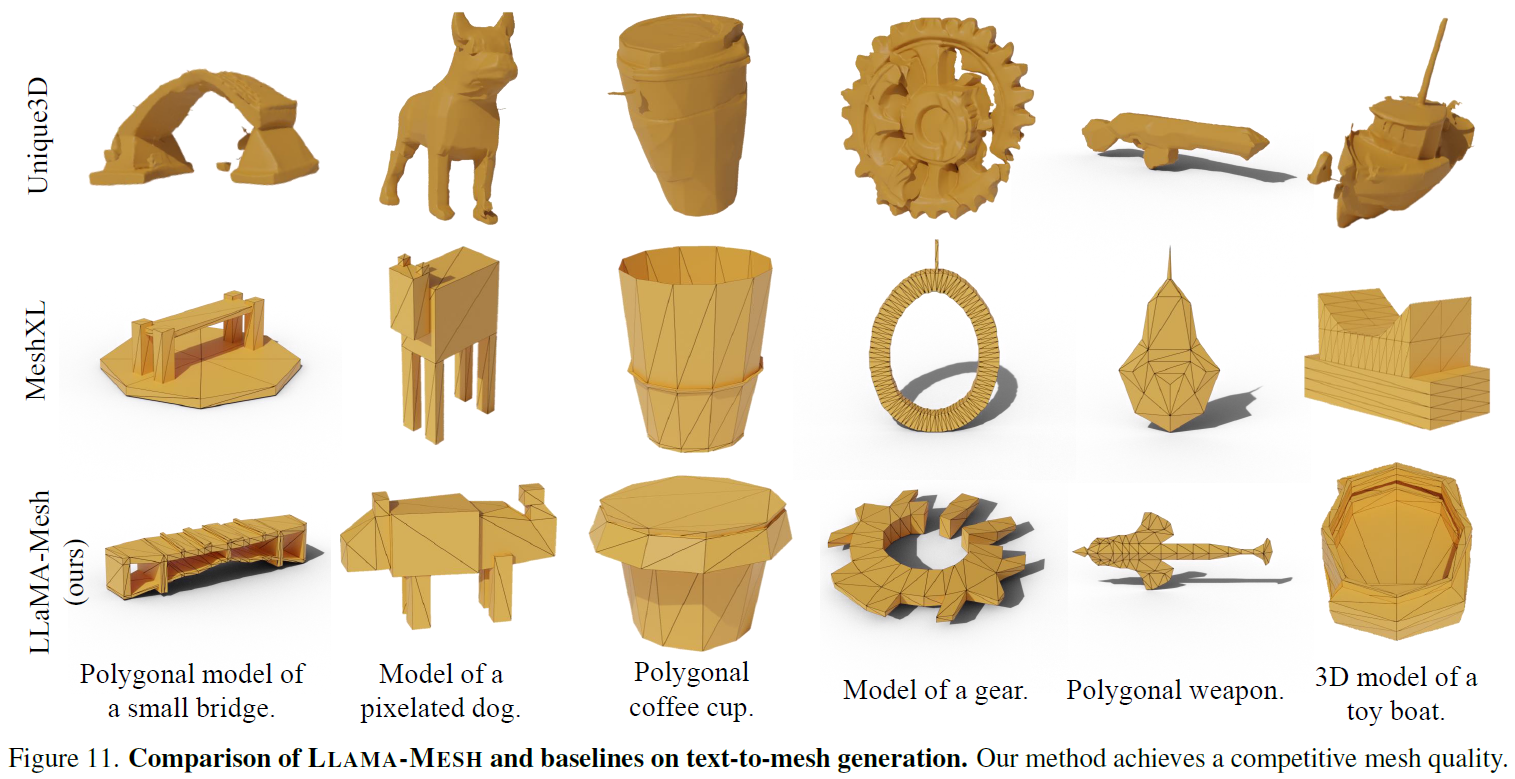
LLaMA-Mesh by Nvidia: LLM for 3D Mesh Generation
Dive into Nvidia’s LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models, a LLM which was adapted to understand 3D objects…
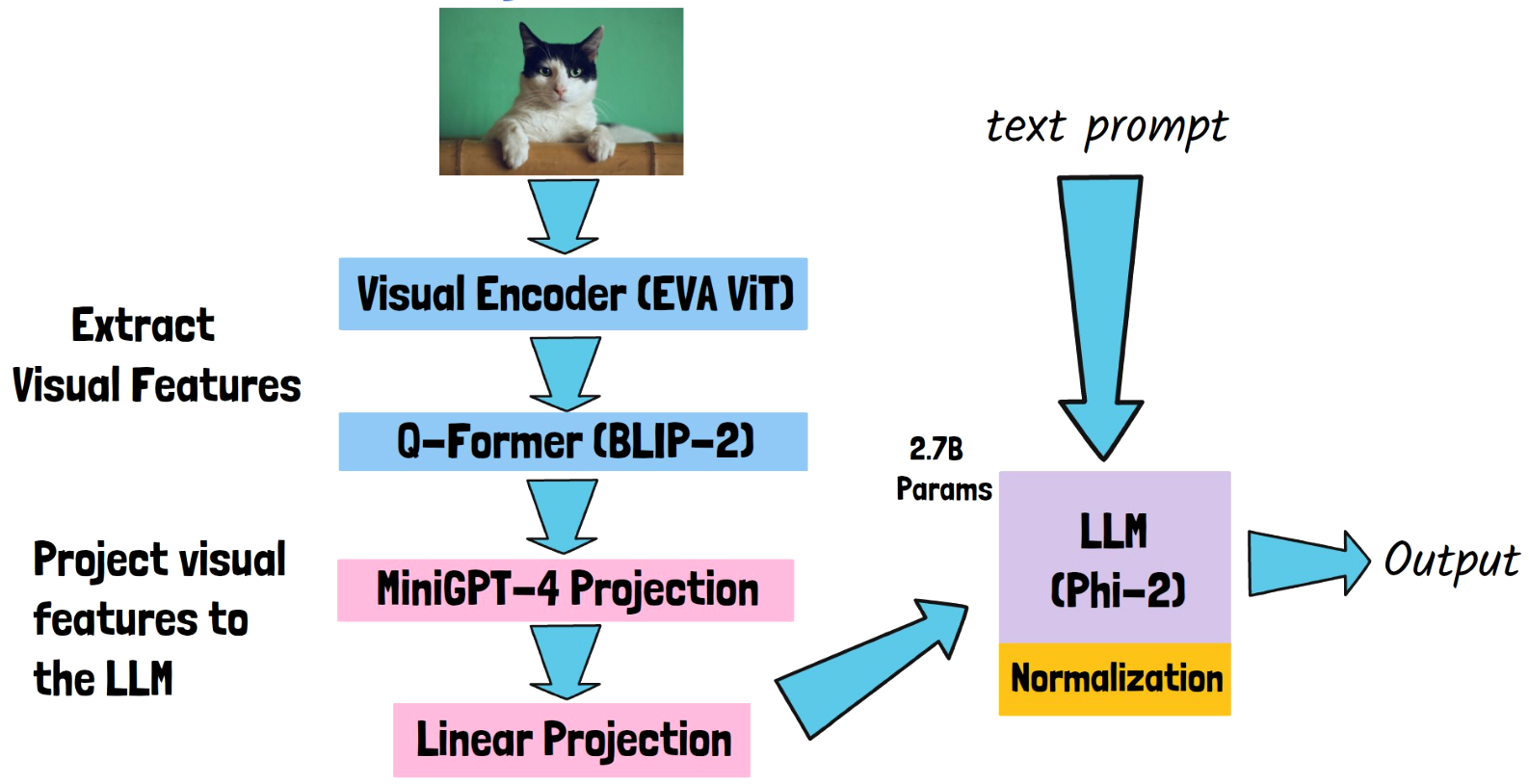
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
In this post we dive into TinyGPT-V, a small but mighty Multimodal LLM which brings Phi-2 success to vision-language tasks…

NExT-GPT: Any-to-Any Multimodal LLM
In this post we dive into NExT-GPT, a multimodal large language model (MM-LLM), that can both understand and respond with multiple modalities…
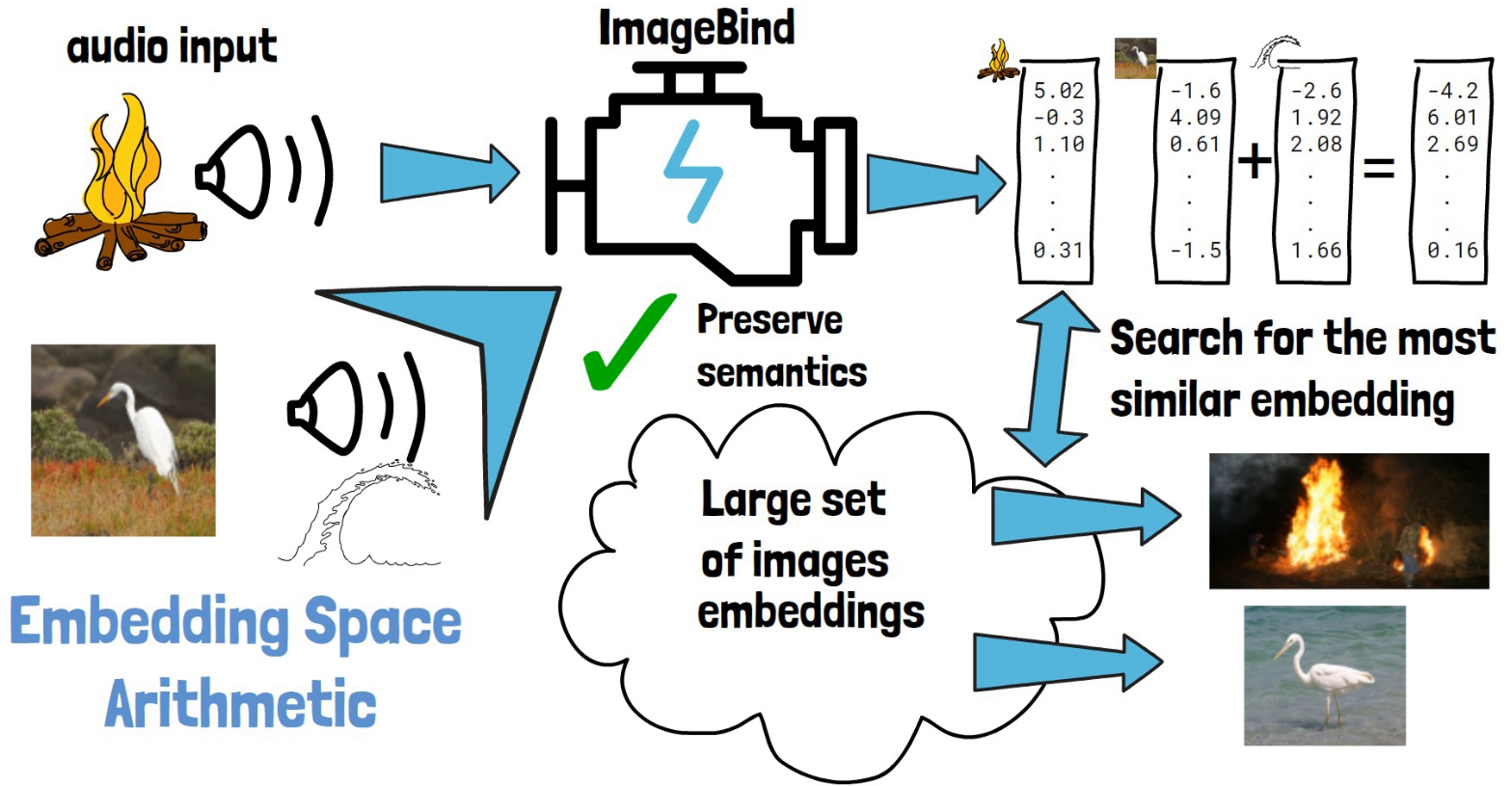
ImageBind: One Embedding Space To Bind Them All
ImageBind is a multimodality model by Meta AI. In this post, we dive into ImageBind research paper to understand what it is and how it works…
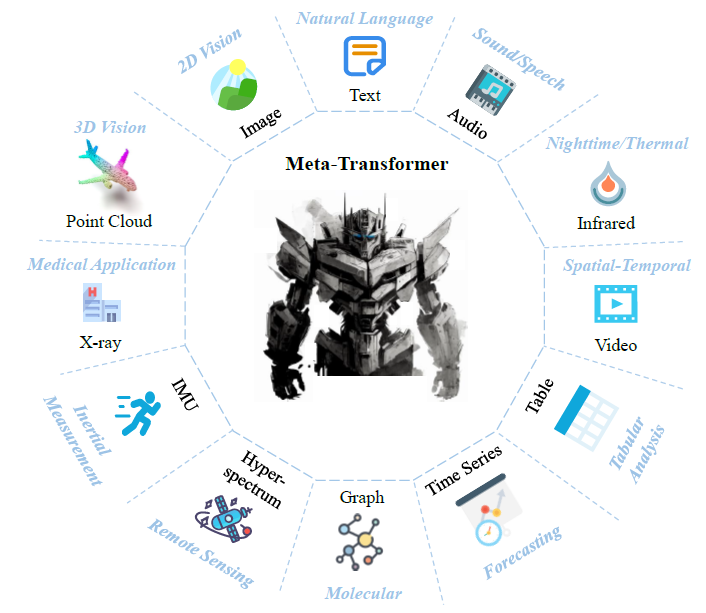
Meta-Transformer: A Unified Framework for Multimodal Learning
In this post we dive into Meta-Transformer, a unified framework for multimodal learning, which can process information from 12(!) modalities…