ImageBind is a model by Meta AI which can make sense out of six different types of data. This is exciting because it brings AI a step closer to how humans are observing the environment using multiple senses. In this post, we explain what is this model, and why should we care about it.
What is ImageBind?
In the most simple level, ImageBind is a model that yields vectors of numbers, called embeddings. These embeddings grasp the meaning of the model inputs.
In the picture below for example, a cat image is provided to a model which yields embeddings.
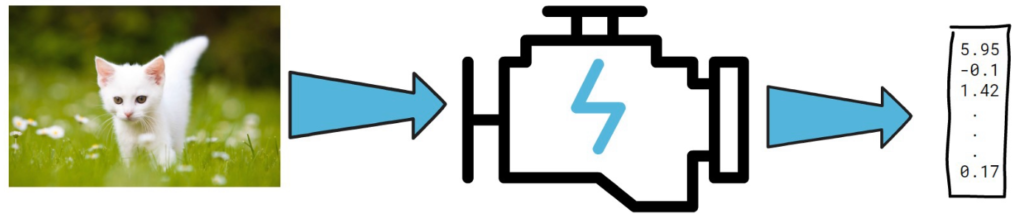
ImageBind offers an exciting feature where you can provide various input types. For instance, along with a cat image, you can input a cat sound, and the model will generate a vector of embeddings. Similarly, describing a white cat standing on grass yields another embedding. Though these embeddings aren’t identical, they share a common embedding space, capturing the same meaning across different cat inputs. Beyond image, audio, and text, the model also comprehends video, depth sensor data, IMU (sensors that detect phone tilts and shakes), and thermal data.

That’s cool but why is it so interesting? Let’s take a look at the power it gives us starting with cross-modal retrieval.
Cross-Modal Retrieval with ImageBind
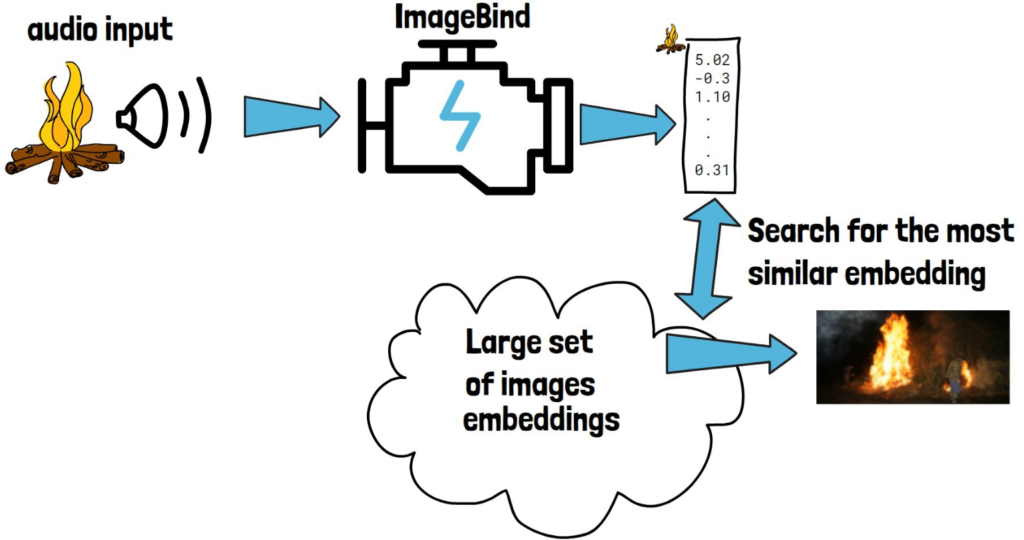
In data terminology, “modal” refers to a type of data, such as image or text. Cross-modal retrieval involves providing a query input from one modality, like the sound of a crackling fire, and retrieving a matching item from another modality, such as an image of fire.
ImageBind facilitates this by first processing the input audio (or any other modality) to generate an embedding. The large dataset of images is stored with their corresponding embeddings, allowing us to search for the image with the most similar embedding to the query.
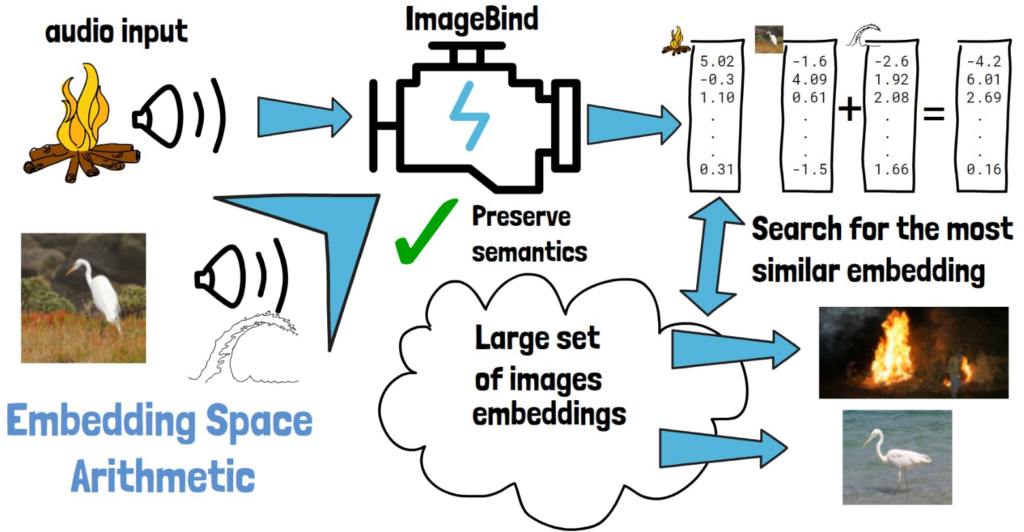
This is super cool capability already but what’s even crazier is that with ImageBind we can also take an image of a bird and the sound of waves (see picture below on the bottom left), get their embeddings from ImageBind, then sum these embeddings together and retrieve an image that is similar to the embeddings sum, and get an image of the same bird in the sea. This shows that embedding space arithmetic naturally composes their semantics which is simply mind blowing.
Audio to Image Generation with ImageBind
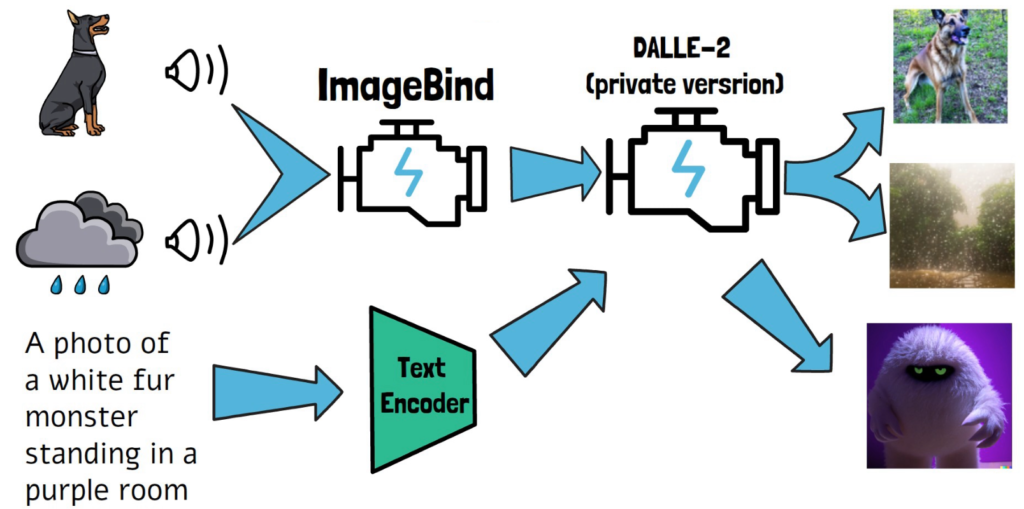
One of the remarkable capabilities of the ImageBind model is its ability to generate images from audio. For example, researchers successfully provided the sound of a dog’s bark as input and generated an image of a dog. They also used the sound of rain to generate a rainy image.
To achieve this, they utilized a pre-trained version of the image generation model DALLE-2, specifically a private Meta AI implementation of DALLE-2. Typically, DALLE-2 requires a text prompt to create an embedding and generate an image. However, with ImageBind, researchers ran the audio through ImageBind to obtain an embedding, which was then used instead of a text prompt embedding in DALLE-2. This innovative approach enables image generation from audio, demonstrating impressive results.
This breakthrough opens the door for similar advancements with other models that operate on text embeddings, suggesting we may see further progress in this area in the future.
Building the ImageBind Model
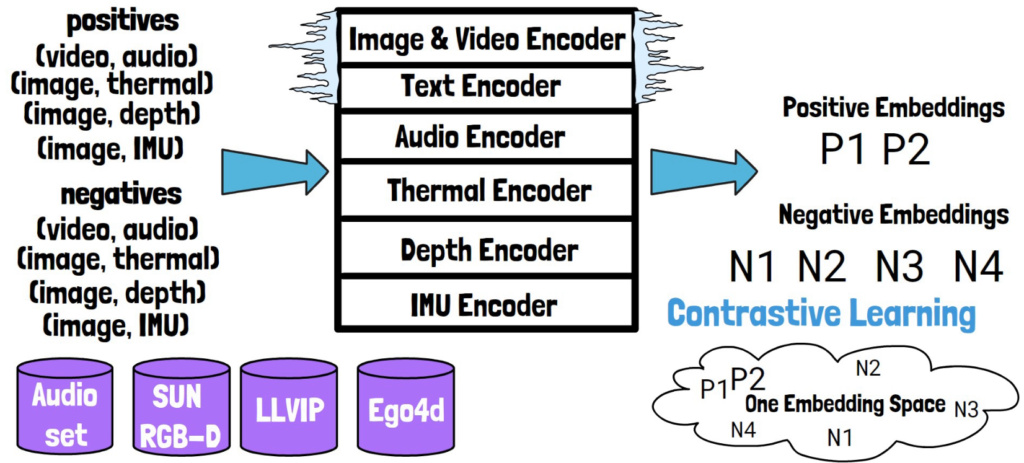
The ImageBind model features six channels, each acting as an encoder for different data types. It uses the same encoder for images and videos, while employing distinct encoders for other data types. Interestingly, the image and text encoders are borrowed from CLIP, an OpenAI model that links text and images, and remain frozen during training to ensure stability. This reliance on CLIP is likely what enabled the text encoder replacement in DALLE-2 for generating images from audio.
To train the additional encoders, the team uses pairs of naturally matching samples, such as audio and video from the Audioset dataset, and extracted images with corresponding thermal, depth, and IMU data from datasets like SUN RGB-D, LLVIP, and Ego4d. They also create non-matching (negative) pairs.
In training, we feed the model with a batch containing both matching and non-matching samples, to obtain encodings for each input. Utilizing a contrastive learning approach, the loss function minimizes the distance between embeddings of positive samples while increasing the distance between those of negative samples, gradually aligning all modalities into the same embedding space.
It’s important to note that finding matching pairs for all different modalities is impractical. Therefore, the team focuses on pairing each modality with images, leading to the name ImageBind—as the image modality binds all other modalities together, encapsulating the essence of the paper: “one embedding space to bind them all

References
- Paper page
- Meta AI Demo
- Join our newsletter to receive concise 1-minute read summaries for the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.