In this post we break down DINOv2, an open-source computer vision model by Meta that had (and still has) massive impact in the AI community, introduced in a research paper titled DINOv2: Learning Robust Visual Features without Supervision.

Introduction

DINOv2 is a computer vision model from Meta AI aims to establish itself as a foundational model in computer vision, much like those in natural language processing (NLP). In this post, we’ll explain what does it mean to be a foundational model in computer vision and why DINOv2 can count as such.
When DINOv2 was released, it counted as a huge model (relative to computer vision), with one billion parameters. This imposes challenges both for training the model and using it. We’ll review the challenges and what the researchers in Meta AI did in order to overcome them, using self-supervision and distillation. Don’t worry if you are not familiar with these terms, we’ll explain them as we go.
DINOv2 as a Foundational Model

Let’s start by first understanding what DINOv2 provides that make it a foundational model in computer vision. In the life before foundational models, creating a computer vision model required finding or creating a dataset, selecting an architecture, and training the model—a complex and lengthy process.
So here comes DINOv2, a pretrained Vision Transformer (ViT), model which is a known architecture in the field of computer vision, and says that you may not need a robust complex dedicated model.
For example, given a cat image (left in the picture below), we can feed it to DINOv2. DINOv2 will yield a vector of numbers, often called embeddings or visual features. These embeddings contain deep understanding of the input cat image, and once we have them, we can use them in smaller simpler models that handle specific tasks. One model could handle semantic segmentation, which means categorizing related parts in the image. Another model could estimate the depth of the objects in the picture.

Training Task Specific Models On Top Of DINOv2
A very important attribute of DINOv2 is that while training these task specific models, DINOv2 can be frozen, or in other words, no finetuning is needed, which further simplifies the training of the simpler models and their usage. DINOv2 can be executed on an image once and the output can be used by multiple models, unlike if it was finetuned, since then there was a need to run the finetuned DINOv2 version for any task specific model we have. Additionally, finetuning a large model requires proper hardware that is not accessible to everyone.
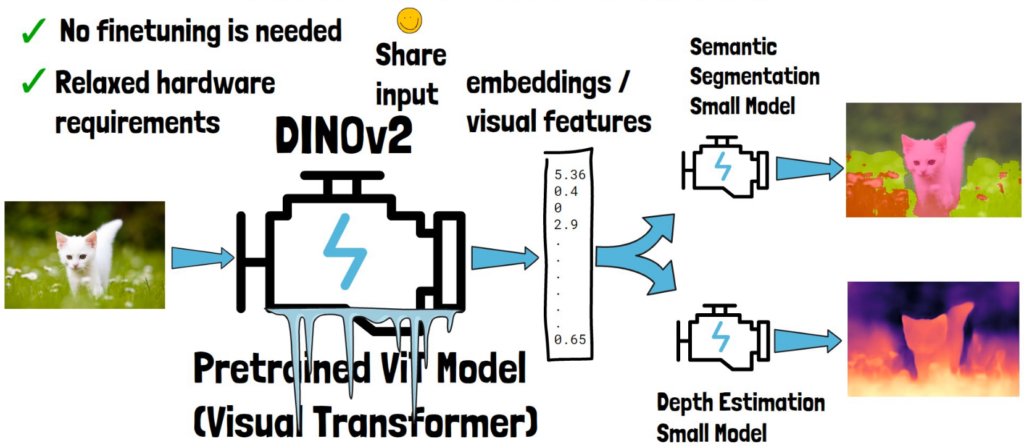
How to use DINOv2?
We do not dive deep into code here, but if you would want to use DINOv2 then you could simply load it using pytorch code as in the following code taken from DINOv2 GitHub page. There are few possible versions of different model sizes to load, so you can decide which version to use based on your needs and resources. The accuracy does not significantly drop when using a smaller version which is cool, especially if using one of the middle size versions.
import torch
dinov2_vits14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vits14')
dinov2_vitb14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitb14')
dinov2_vitl14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitl14')
dinov2_vitg14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitg14')This brings us to talk about how they generated the different DINOv2 model versions, and the answer is distillation.
DINOv2 Models Distillation
Distillation in AI means transferring knowledge from a large trained model into a new smaller model. A common method is teacher-student distillation, where one model acts as a teacher, and another model acts as a student. Applying to DINOv2, a large pretrained DINOv2 model can teach new smaller models.An interesting note is that the researchers achieved better results with distillation, comparing to training smaller models from scratch.
For example, given a cat image, DINOv2 process it and yields visual embeddings. Then, we have a smaller model which we also feed with the same cat image, which generates its own visual embeddings. The distillation process aims to minimize the difference between the embeddings originated from the new model to the one originated from teacher model. The teacher weights are kept frozen in this process.
In practice, to get better results from the distillation process, we do not use just one student but rather multiple ones and each simultaneously gets the same inputs and yields results. During training, an average of all of the student models is created which ends up to be the final graduated distilled model.

Self-Supervised Learning with Large Curated Data
With DINOv2, the model size was increased dramatically from the previous DINO version, which raised the need for more training data to train DINOv2 using Self-Supervised Learning (SSL), which means that the training data has no labels and the model learns solely from the images.
Without data labelling it should be easier to increase training data size right? Previous attempts to increase uncurated data size with self-supervised learning have caused a drop in quality.
With DINOv2, the researchers have built an automated pipeline to create a curated dataset. This is a key factor for reaching state of the art results comparing to other self-supervised learning models. The pipeline starts from 25 sources of data that include 1.2 billion images (!), and ends with 142 million curated images.
The curation pipeline has multiple filtering steps. For example, in the original uncurated dataset we’ll likely find a lot of cat images comparing to non-cat images. Training on such dataset may result in a model that is very good in understanding cats but may not do a very good job in generalizing to other domains.
Therefore, one of the steps in this pipeline is clustering, which basically means grouping images based on similarities. Then, we sample from each group a similar number of images and able to create a smaller but more diverse dataset.

Pixel Level Understanding

Unlike with DINOv2, a common approach in computer vision is using text guided pretraining. The above cat image comes with a description text such as “a white kitten in a field of grass”. Both the image and the text are used for pretraining the model. However, the description text may miss data, such as the fact that the cat is walking, or the small white flowers. This may lead to limiting the learning capability.
With DINOv2’s self-supervised learning approach, the model develops remarkable capability to grasp pixel level information. In the picture below we can see multiple horse images, and a corresponding visualization of DINOv2 visual features on them. Horses in different pictures get similar colors for same body parts, even if there are multiple horses in a picture, and even if they are super tiny, very impressive.
DINOv2 With Registers
DINOv2 builds upon its predecessor, DINO, and enhances performance across various tasks. However, object discovery tasks did not see similar improvements. Meta conducted follow-up research to uncover the cause. They discovered that DINOv2 uses less important input patches for global information, rather than retaining spatial information about the image patches.
To address this, Registers, learnable tokens added at the end of the patch token sequence, were introduced. These registers guide the model to utilize them for global information, freeing up image patches to focus on spatial details. This adjustment improves object discovery results significantly.
However, the benefits for other tasks remain limited. Considering the added computational cost of using register tokens, it’s essential to evaluate whether registers help for your specific task.
For a deeper dive into this research, visit our detailed analysis here.
References
- Paper – https://arxiv.org/abs/2304.07193
- Code – https://github.com/facebookresearch/dinov2
- Join our newsletter to receive concise 1-minute read summaries for the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.
A more recent computer vision progress by Meta AI is human-like I-JEPA model, which we covered here.