From Sparse to Soft Mixture of Experts
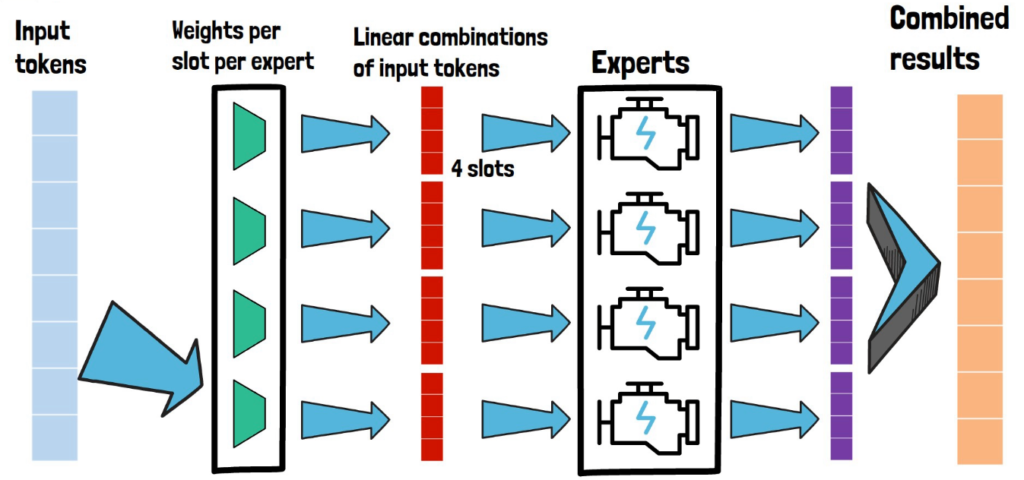
In this post we review Google DeepMind’s paper that introduces Soft Mixture of Experts, a fully-differentiable sparse Transformer.
In this post we review Google DeepMind’s paper that introduces Soft Mixture of Experts, a fully-differentiable sparse Transformer.