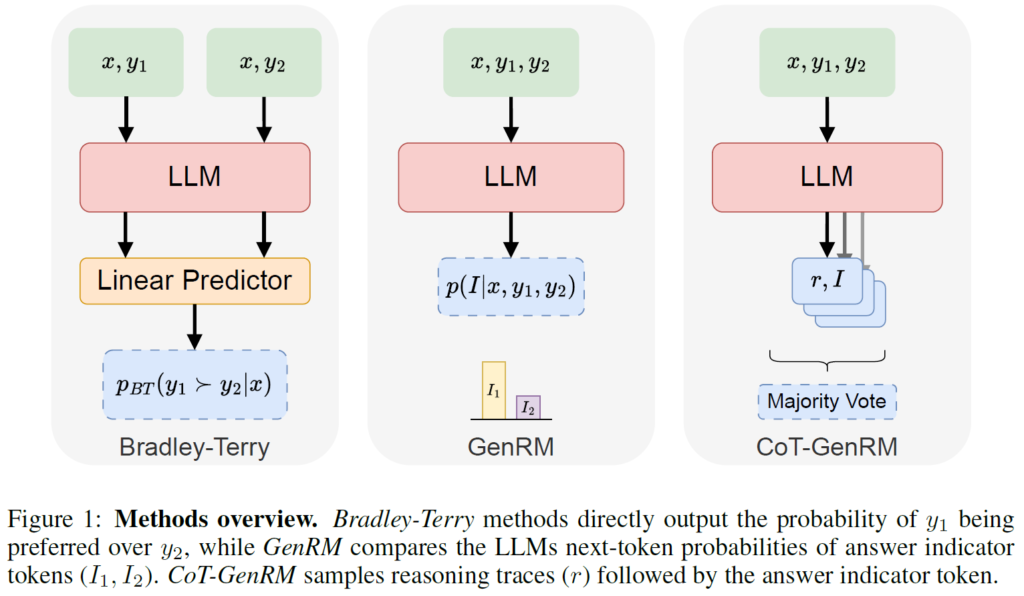
Generative Reward Models: Merging the Power of RLHF and RLAIF for Smarter AI
In this post we dive into a Stanford research presenting Generative Reward Models, a hybrid Human and AI RL to improve LLMs
Generative Reward Models: Merging the Power of RLHF and RLAIF for Smarter AI Read More »