In this post, we explore Microsoft’s Orca research paper, titled: ‘Orca: Progressive Learning from Complex Explanation Traces of GPT-4‘, which presents a language model trained using a novel imitation learning approach and demonstrates very impressive results.

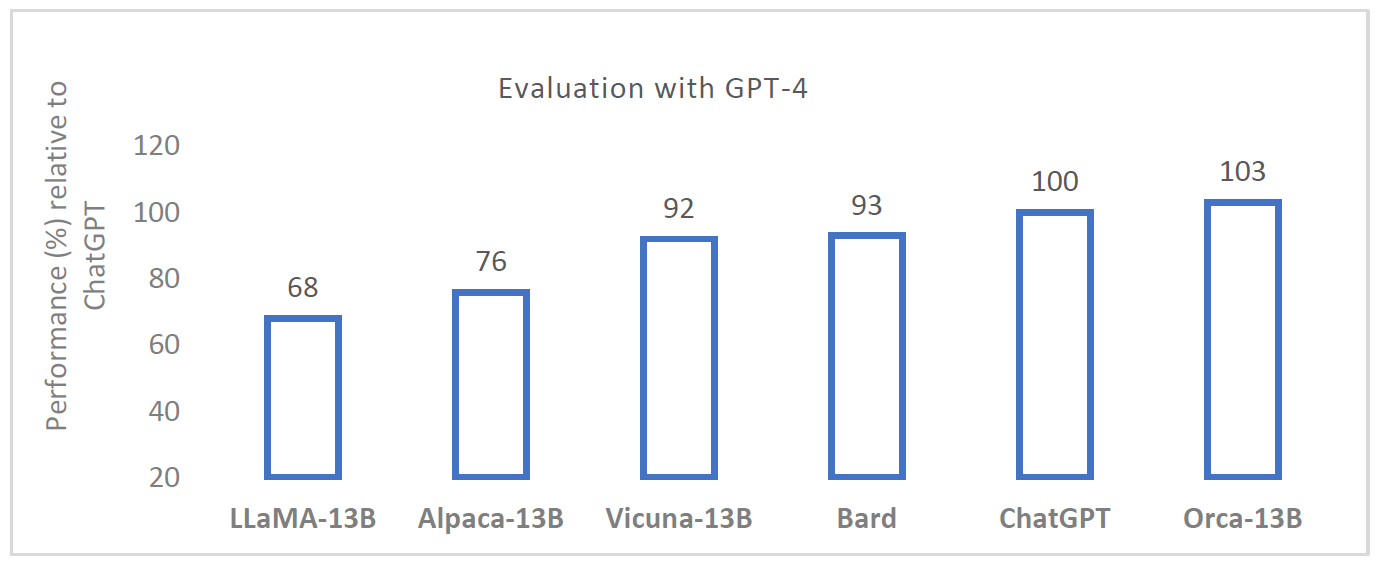
In the chart below, GPT-4 judges the performance on the Vicuna evaluation set. Results are visualized with a relative performance to ChatGPT. It shows that Orca achieves better results than many famous large language models, including ChatGPT, despite being about 7% of its size! We’ll explain how Microsoft researchers did that and why it is so interesting.
Imitation Learning

Top large language models (LLMs) like Vicuna, Alpaca, and WizardLM start with a base LLM, primarily LLaMA, which is significantly smaller than the massive ChatGPT or GPT-4. They then enhance the base model’s capabilities by fine-tuning it on a dataset created using responses from ChatGPT or GPT-4. This method of learning from the outputs of another model is known as imitation learning.
Orca Results – Was Imitation Learning Done Right?

Up until Orca, with imitation learning as been done so far, the models learn to imitate the style rather than the reasoning process of the strong larger models. The researchers claim that common evaluation methods are causing to overestimate the smaller model capability.
In the chart at the top of the post, Vicuna reaches 92% of ChatGPT’s quality, with GPT-4 as the judge. However, this is problematic because GPT-4 may prefer responses from models fine-tuned on GPT responses. And really, when the researchers ran evaluations on complex datasets, like professional and academic exams from AGIEval (chart above), we see that Vicuna legs behind much more significantly than the 92% of ChatGPT quality. However, Orca’s performance is significantly closer to ChatGPT.
Orca’s Most Impressive Results
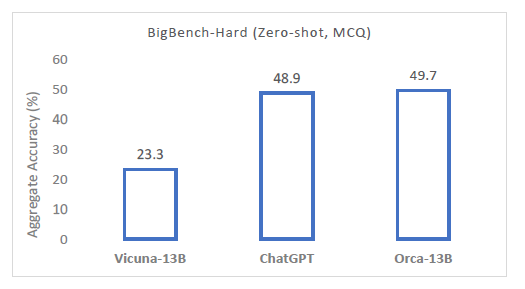
In the above chart, we see the likely most impressive result in this paper. We compare Orca to ChatGPT and Vicuna on BigBench-Hard (BBH) dataset, which includes tasks which humans still dominant over LLMs. For example, boolean expressions like “not true and true” which should result in “false”. We see that Orca outperforms even ChatGPT, and improves over Vicuna by more than 100%!
Building Orca
Orca model also starts from LLaMA, with 13 billion params, and fine-tuned on ChatGPT and GPT-4 outputs but the key idea is with how they build their training dataset.
Let’s review the key factors for their success.
Explanation Tuning
The first factor contributing to this improvement is explanation tuning. Explanation tuning is a new approach for imitation learning. Explanation tuning aims to help the model understand the thought process of the teacher model, such as ChatGPT. The idea is that the reason current imitation-learning based models fail to reach higher quality is because the responses they use for fine-tuning are mostly simple and short. In Orca dataset, we use detailed responses from GPT-4 and ChatGPT, that explain the reasoning process of the teacher as it generates the response. So, for example, before Orca, to generate a sample for training, GPT-4 would get a query that includes an instruction and an input as the prompt, and would generate a response. We see in the following example that the output is simple and short.

When generating a sample for Orca training, using the same query as above, but in the following example we have an addition to the prompt of a system instruction, which provide guidelines for GPT-4 regarding how it should generate the response. For example, here it says: “You are an AI assistant. Provide a detailed answer so user don’t need to search outside to understand the answer”, and we get a very detailed response that include reasoning for the answer. Overall, 16 hand-crafted system instructions we used across Orca training samples, which helped Orca learn the reasoning process of ChatGPT and GPT-4 rather than imitate their styles.

Task Diversity and Data Scale

The second key factor that helps Orca outstand is task diversity and data scale. In the above table, we see a comparison of the data sizes used by similar models, which shows the order of magnitude increase in scale with Orca. Orca’s training involved 5 million samples, compared to WizardLM, the largest of the other models, which utilized 250k samples. The dataset for Orca was extracted from Flan, a Google dataset containing a wide variety of tasks and instructions. From Flan, they selectively sampled a collection of 5 million instructions from diverse and complex tasks. They then gathered 5 million responses from ChatGPT and additionally collected GPT-4 responses for 1 million of those samples.

Key Takeaways from Orca
We have two key takeaways from this paper.
- We can use foundational language models such as GPT-4 or ChatGPT as teachers for smaller models. This is the opposite claim comparing to the recent paper about the false promise of model imitation. Microsoft shows with Orca that model imitation is in fact not a false promise.
- Explanation tuning results shows that learning from step-by-step explanations is a promising direction and can improve model capabilities.
References & Links
- Paper page – https://arxiv.org/abs/2306.02707
- Join our newsletter to receive concise 1-minute read summaries for the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.