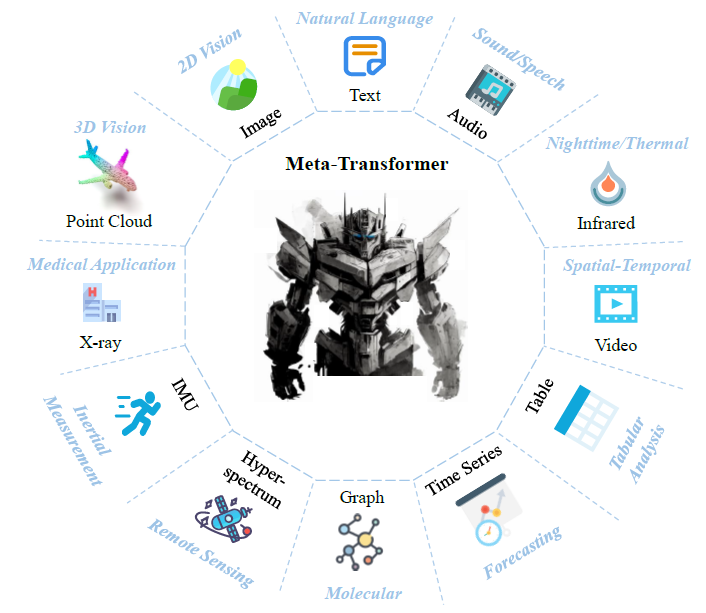
In this post we dive into Meta-Transformer, a multimodal learning method, which was presented in a research paper titled Meta-Transformer: A Unified Framework for Multimodal Learning. In the paper, the researchers show they were able to process information from 12(!) different modalities that we see in the picture above, which includes image, text, audio, infrared, tabular data and more. This is inspired from the human brain, which is able to process information from various types of inputs.
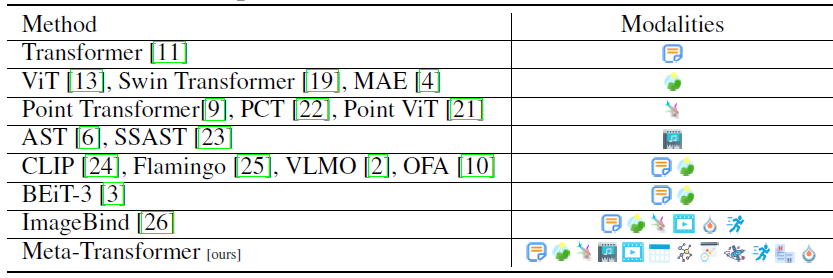
Designing models that are capable of processing wide range of data formats is challenging since each data modality is structured differently and has unique data patterns. In the above table, we see that Meta-Transformer supports significantly wider range of data types comparing to previous models and in this post we’ll explain the Meta-Transformer framework to understand how the researchers were able to do that.
If you prefer a video format, then most of what we cover here is also covered in the following video:
Meta-Transformer Architecture

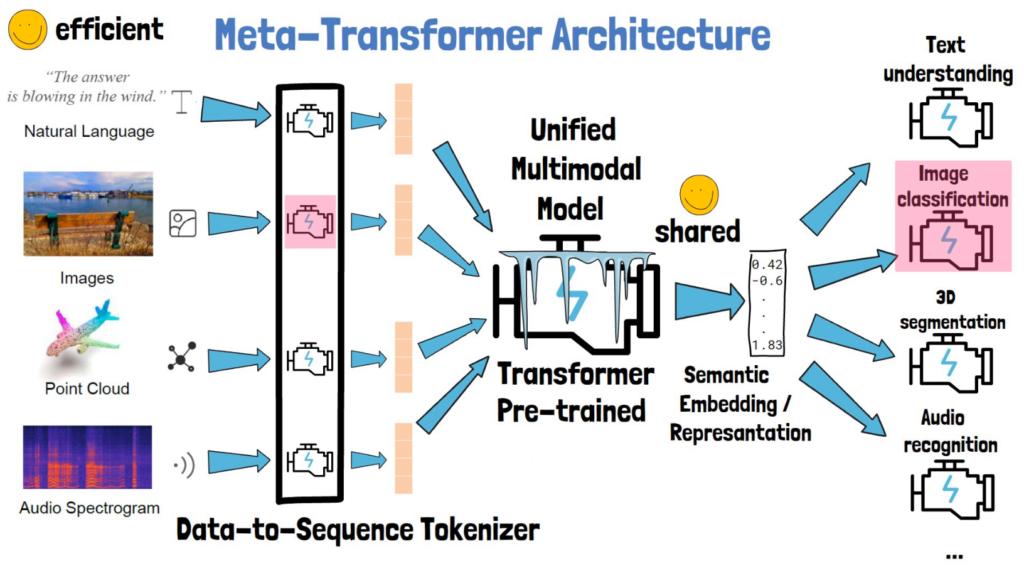
Let’s start with understanding the Meta-Transformer architecture. The Meta-Transformer has a large unified multimodal model which is transformer-based, which can process different modalities as inputs, such as the inputs we see on the left in the picture above. The types of input are text, images, point cloud, which is the representation of three dimensional object and an audio spectrogram, and more.
The purpose of the unified multimodal model is to yield for any input, from any supported modality, a vector of numbers, which is the semantic embedding or representation of the input data, which grasp the meaning of the input.
The semantic representation is then used by smaller and simpler task specific models for whatever purpose we want, such as text understanding, image classification, segmentation, audio recognition and many more. But how can the transformer process information from different types of data? For this the Meta-Transformer has another layer which is called data-to-sequence tokenizer, which consists of small tokenizers where each small tokenizer is a modality specialist that converts an input from the modality it knows, to a sequence of tokens. The transformer is then capable of processing that sequence of tokens.
Training a task-specific model
In order to handle a task, such as image classification, we do not train all of this from scratch, but rather, the unified multimodal model is pre-trained, and we’ll explain a bit more about its pretraining process in a minute, but for now, the components we train to support this task, are the small simpler end task model, and the small tokenizer model which is the specialist of the type of model we process for this task, images in the example we highlight above. This is efficient because the models here are small and during this process the larger transformer model is kept frozen. Since the transformer is frozen, it can be shared to support many different end tasks. This process trains the specialist tokenizer to bring the input embeddings into the same embedding space that the pre-trained transformer is used to work with. Optionally the transformer can be fine-tuned as part of this process for better results, but then it can’t be shared.
Unified Multimodal Transformer Per-training
Let’s complete the missing piece of how the unified multimodal model is pre-trained. The paper does not share a lot of information about the pre-training process, but it does share that they use the LAION-2B dataset. This dataset is comprised of text and image pairs from the internet. They also mention that they use a contrastive learning approach, so what does it mean?

Given the transformer model we want to train, in the pre-training process we take samples of text and image pairs which have similar meaning like the example for a pair in the image above. The image and text are passed via the relevant tokenizer to create tokens in the same space, and these tokens are passed via the transformer to create semantic embeddings. The embeddings we got from the transformer are different for the text and the image, but since the meaning of the text and image is similar, we punish the transformer so it will learn to yield similar results for them.

Similarly, during the pre-training process we can also take pairs that are unrelated, like in the image above for example, and then we’ll train the transformer to yield different results for the text and image.
A very important note here is that the researchers do not start from scratch at all here as well. Rather, we actually use CLIP as the text encoder, which CLIP is a pretrained model that connects text and images so its embeddings already grasp semantic meaning of the text. Overall it is very interesting that this pretrained model was able to adapt to other modalities since it was only trained on texts and images, and the only adaptation process is training the other modalities tokenizers to yield input embeddings in the same space that the model saw in pre-training.
Results
Now that we have a better idea about how Meta-Transformer works, let’s see some of the results that were shared in the paper. The researchers ran various experiments to test the performance of meta-transformer on each of the 12 different modalities, on different tasks and various datasets and we’ll see the results for some of them.

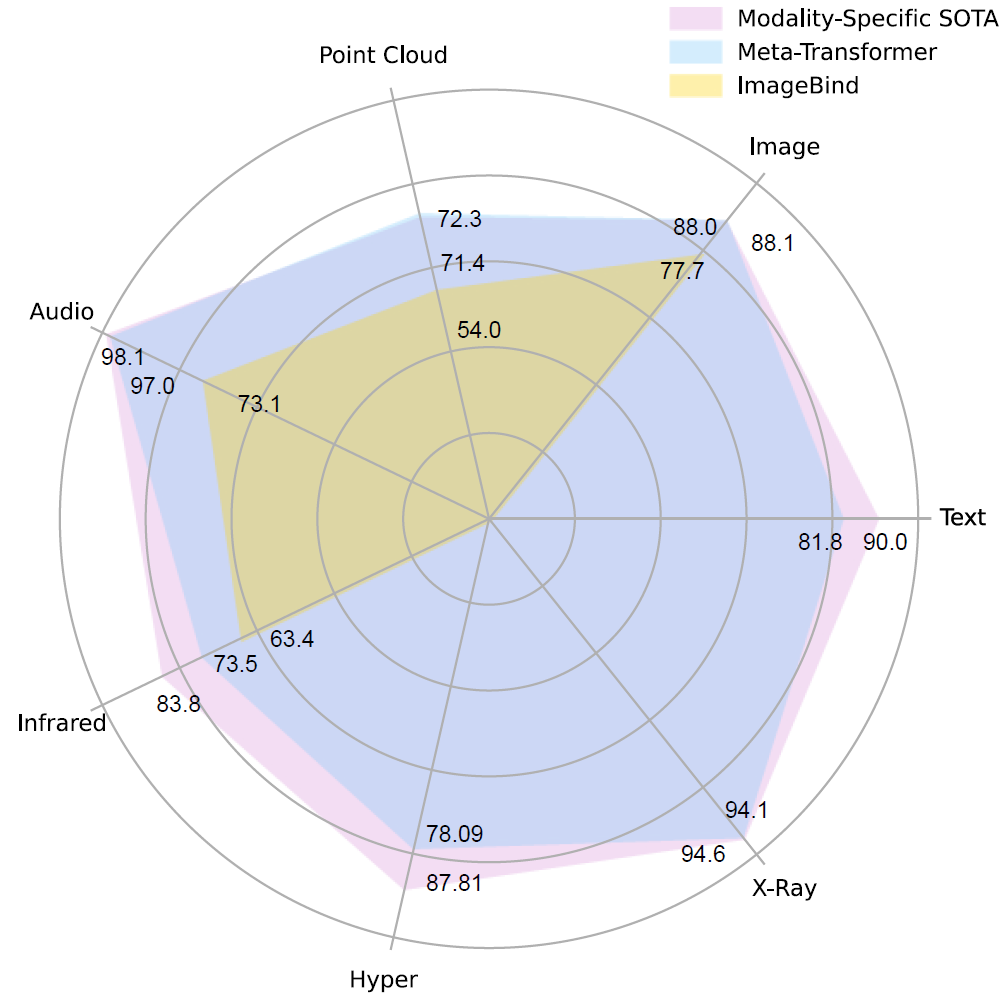
First, in the image below we can see a summarized view of the results where in blue we can see the performance of Meta-Transformer and in pink we see the state-of-the-art performance for each modality. We can see that Meta-Transformer achieves very impressive results. In yellow we see the results of ImageBind which is a model from Meta AI that can also handle part of the modalities examined here. We covered ImageBind model as well here.
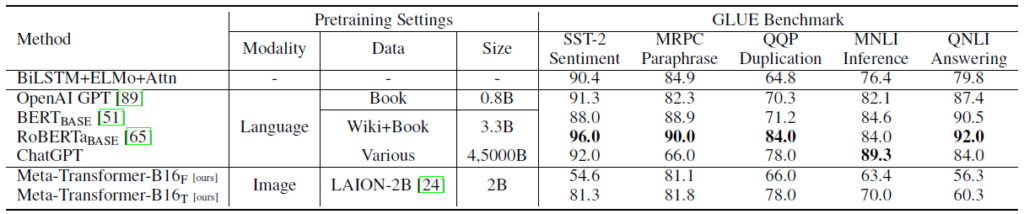
Diving deeper into the model results for text data, in the below table we see results for the GLUE benchmark which stands for General Language Understanding Evaluation, and we see Meta-Transformer achieves relatively good results, not as good as the large language models but remember that the Meta-Transformer has no pre-trained large language model, so this is quite impressive. The difference between the two Meta-Transformer models evaluated here is that the upper one, with the capital F, kept the unified multimodal transformer frozen during training and the lower one, with capital T, fine-tuned the transformer as part of training of the end task model. We can see in the numbers that the results are better when fine-tuned.
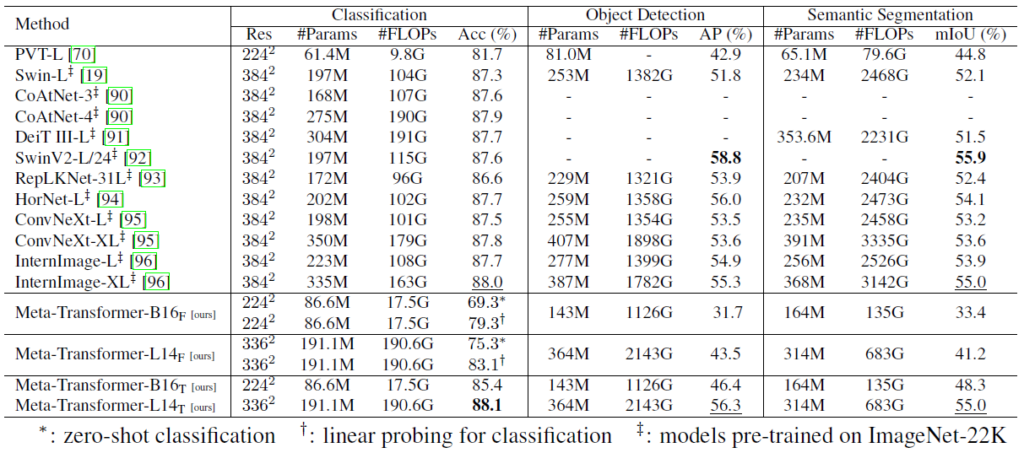
Next, for image, we see in the table below evaluation results for image classification task, object detection and semantic segmentation, and here Meta-Transformer in its tuned version was able to achieve the best results for image classification, and quite close to it for object detection and semantic segmentation.
References
- Paper – https://arxiv.org/abs/2307.10802
- Video – https://youtu.be/V8L8xbsTyls