Motivation
It’s hard to imagine AI today without Transformers. These models are the backbone architecture behind large language models that have revolutionized AI. Their influence, however, is not limited to natural language processing. Transformers are also crucial in other domains, such as computer vision, where Vision Transformers (ViT) play a significant role. As we advance, models grow larger, and training the models from scratch becomes increasingly costly and unsustainable, raising environmental concerns.
Introducing Tokenformer
The paper we review today is titled: “Tokenformer: Rethinking Transformer Scaling with Tokenized Model Parameters,” and it introduces a fascinating change to the Transformer architecture, named Tokenformer. Tokenformer eliminates the need to retrain the model from scratch when increasing model size, dramatically reducing the cost.

Transformer vs Tokenformer – Architecture Comparison
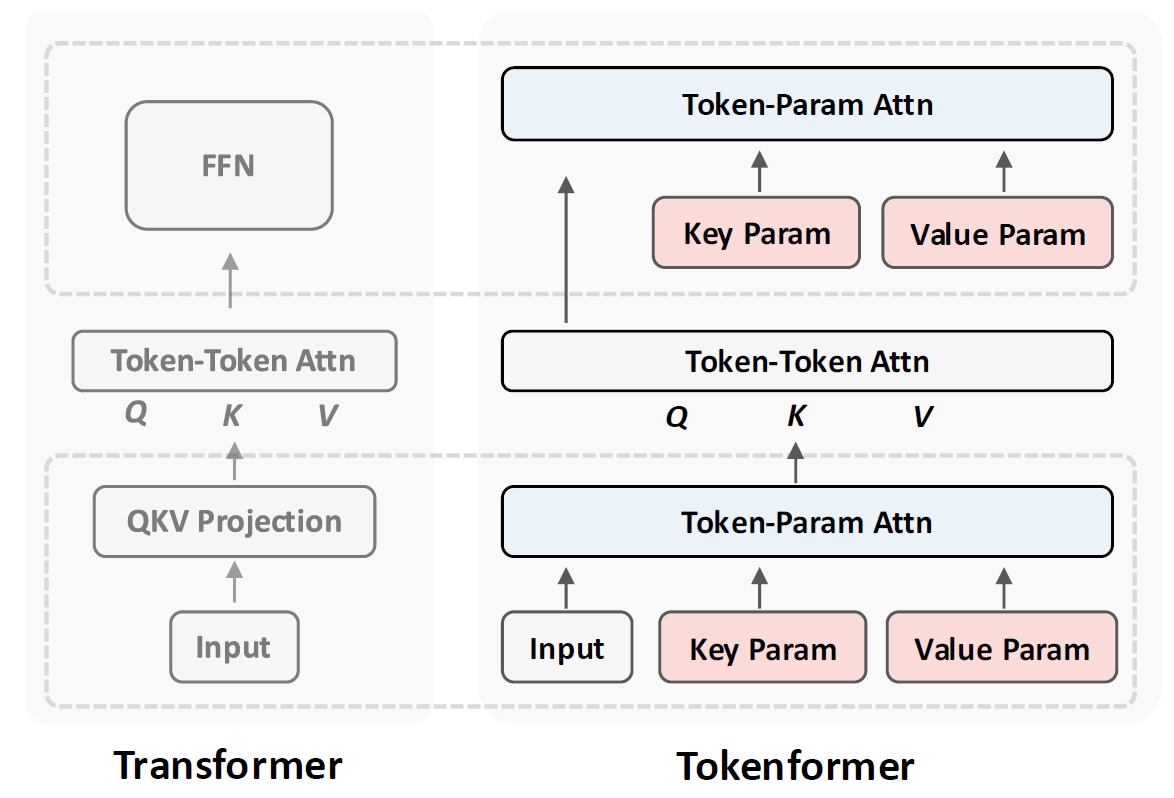
Let’s start with a high-level comparison between the traditional Transformer architecture and Tokenformer, as depicted in the figure from the paper.
Transformer High-level Flow
On the left, we have a simplified view of the original Transformer architecture. Given an input sequence of tokens at the bottom.
- The input first passes through a linear projection block to calculate the inputs for the attention block, the matrices Q, K, and V. This phase involves interactions
between the model parameters and the input tokens, calculated using a linear projection. - Then, the self-attention component allows input tokens to interact with each other, calculated via an attention block.
- Finally, a feedforward network (FFN) produces the output for the next layer, again representing interactions between tokens and parameters calculated using linear
projections.
Tokenformer Idea
Typically, token-parameter interactions are calculated via linear projection components, which hold a fixed size of parameters. This is necessitating training from scratch when increasing
model size.
The main idea behind Tokenformer is to create a fully attention-based model, including token-parameter interactions, to have a more flexible architecture that supports incremental parameter count increases.
Tokenformer High-Level Flow
On the right of the figure above, we can see a simplified view of the Tokenformer architecture.
- To calculate the inputs for the self-attention block (Q, K, and V matrices), we feed the input tokens into a new component called token-parameter attention, where in addition to the input tokens, we also pass parameters. The input tokens represent the query part, and the parameters represent the key and value parts of the token-parameter attention block.
- Then, we have the same self-attention component as before.
- To prepare the output for the next layer, we replace the feed forward network with another token-parameter attention block, where we use the output from the self-attention block as the query, and we again have different parameters for the key and value matrices.
Tokenformer Architecture In More Details
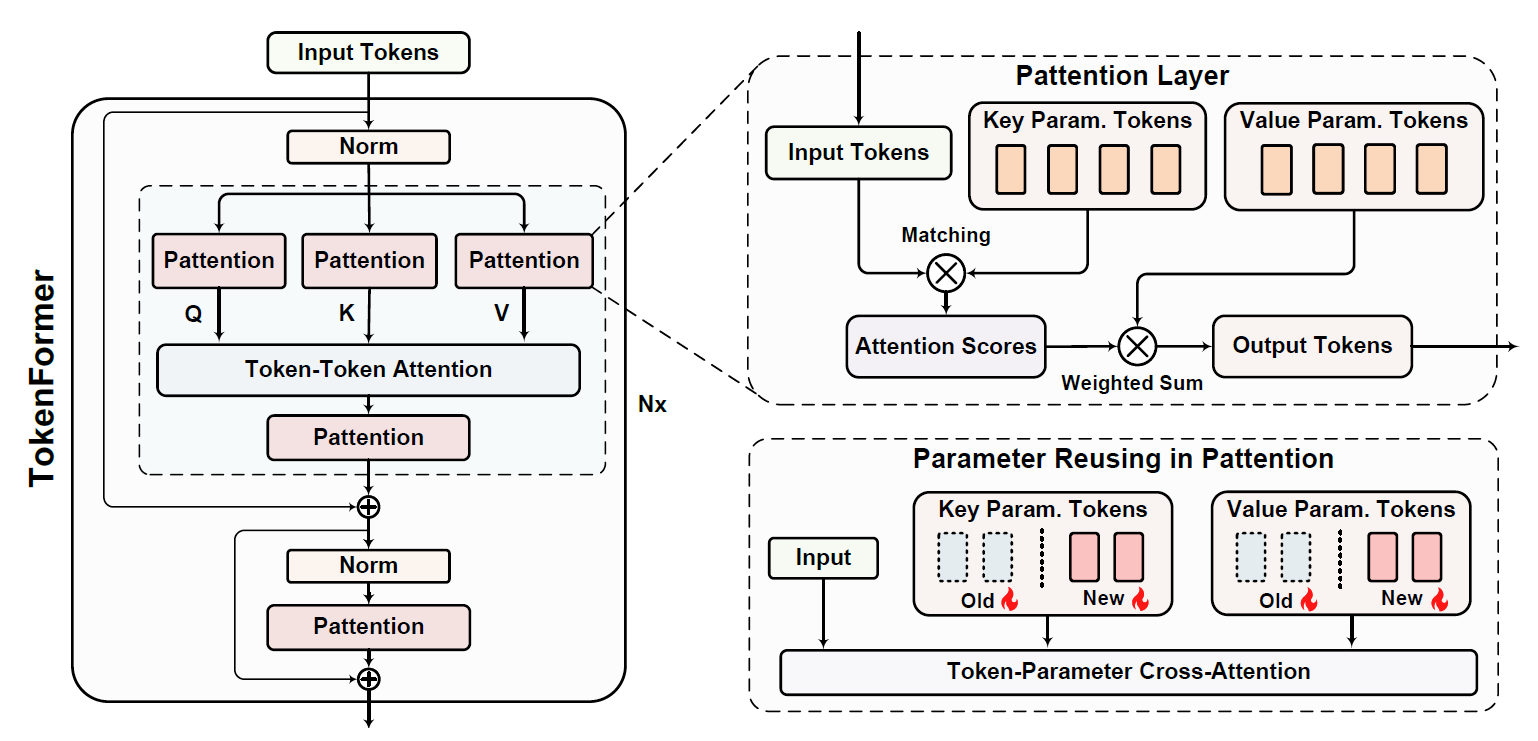
Calculating the inputs for the self-attention block
Zooming into the Tokenformer architecture, after normalization, input tokens are passed to three Pattention blocks, where Pattention is the name of the token-parameter attention block. Each of the three Pattention blocks has its own weights and is responsible for creating the inputs for the self-attention blocks, the Q, K, and V matrices, one per each Pattention block.
How is the Tokenformer’s Pattention Different Than Attention?
The original attention block is calculating the following formula:
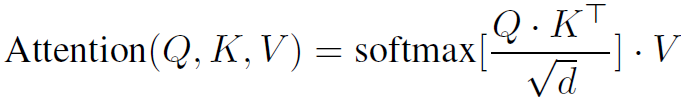
And the Pattention block calculate a very similar equation:
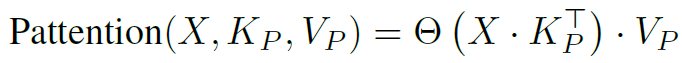
The input tokens are used as the query, and the key and value matrices are given by parameters of the pattention block. A modified softmax with different scaling mechanism (the theta function) is used comparing to attention, to improve the optimization stability. The modified softmax of X multiplied by K matches the input tokens to the key parameters, yielding the attention scores. The attentions scores are then weighted using the V parameters matrix to generate the final output from this block.
Replacing The FFN With Pattention
After the standard self-attention block process the outpurt from the three pattention blocks, instead of a feed forward network, we have two more sequential pattention blocks, where between them we merge with the input tokens via a residual connection, as we can see on the bottom left in the figure above.
Incremental Model Growth
On the bottom right of the architecture figure, we see an illustration for increasing model size incrementally by adding new parameters. We append more parameter token rows to the key and value matrices in each pattention block. We keep the already-trained parameter tokens so they do not start from scratch. Then, we train the larger model and update all tokens in this process. We see in the results below that incremented models are trained much faster comparing to training from scratch.
Results
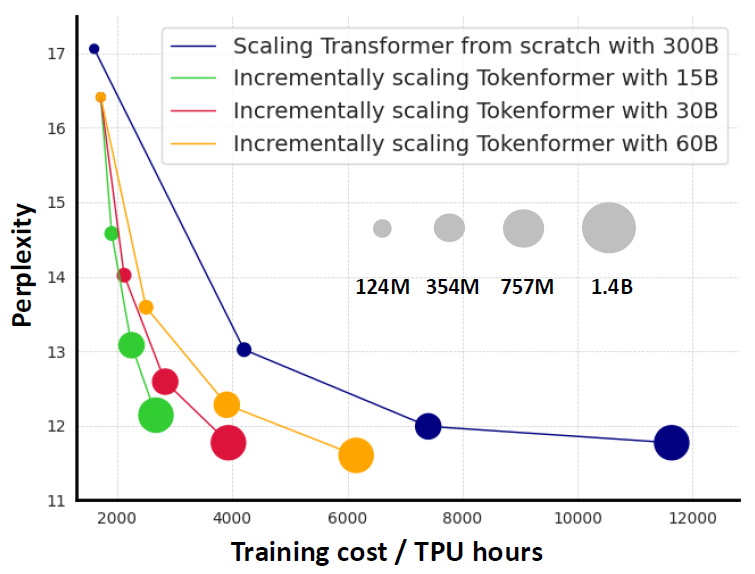
Above, we see Tokenformer performance relative to the training cost, compared to a Transformer trained from scratch.
The blue line represents Transformer models trained from scratch using 300 billion tokens. Different circle sizes represent different model sizes, listed in gray circles in the middle. Other lines represent Tokenformer models, with each color representing a different number of tokens used to train the incremented versions. For example, the red line starts with 124 million parameters and scales up to 1.4 billion parameters, using 30 billion tokens out of the 300 billion tokens used to train from scratch. The final version is comparable in performance to the Transformer of the same size but with dramatically lower training costs! The yellow line shows that using 60 billion tokens to train the incremented versions outperforms Transformer, with lower training costs.
References & Links
- Paper page
- Video
- Code
- Join our newsletter to receive concise 1 minute summaries of the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.