Introduction

In this post, we dive into a new release by Meta AI, presented in a research paper titled Sapiens: Foundation for Human Vision Models, which presents a family of models that target four fundamental human-centric tasks, which we see in the demo above.

Fundamental Human-centric Tasks

In the above figure from the paper, we can learn about the tasks targeted by Sapiens.
- Pose Estimation – detects the location of key points of the human body in the input image.
- Body-part Segmentation – determines which pixels combine the different body parts.
- Depth Estimation – determines the depth of the pixels. As shown in the examples on the “Depth” column, parts in the front of the image are brighter, and pixels in the back of the image are darker.
- Surface Normal Estimation – provides orientation about the shape of the object, a human in our case.
Impressively, Meta AI achieves significant improvement comparing to prior state-of-the-art results for all of these tasks. In the rest of the post we explain how Meta AI researchers created these models.
Humans-300M: Curating a Human Images Dataset
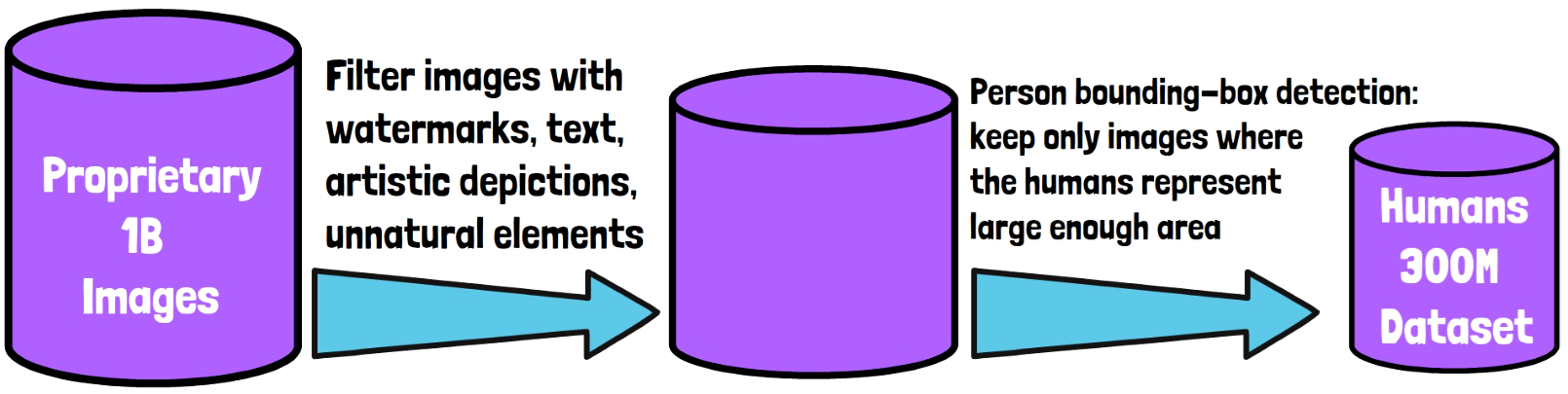
The first ingredient we talk about is the curation of a large human images dataset. Meta AI has an advantage here with a proprietary dataset of 1 billion human images. To improve the dataset quality, they filter out images with watermarks, text, artistic depictions or unnatural elements which leaves us with a bit smaller dataset. Then, to further improve the quality of the dataset, they also use an off-the-shelf person bounding-box detector to filter out images where persons may not represent a meaningful part of the image. Finally, we end up with 300 million high quality human images.
Humans-300M – Number of humans per image
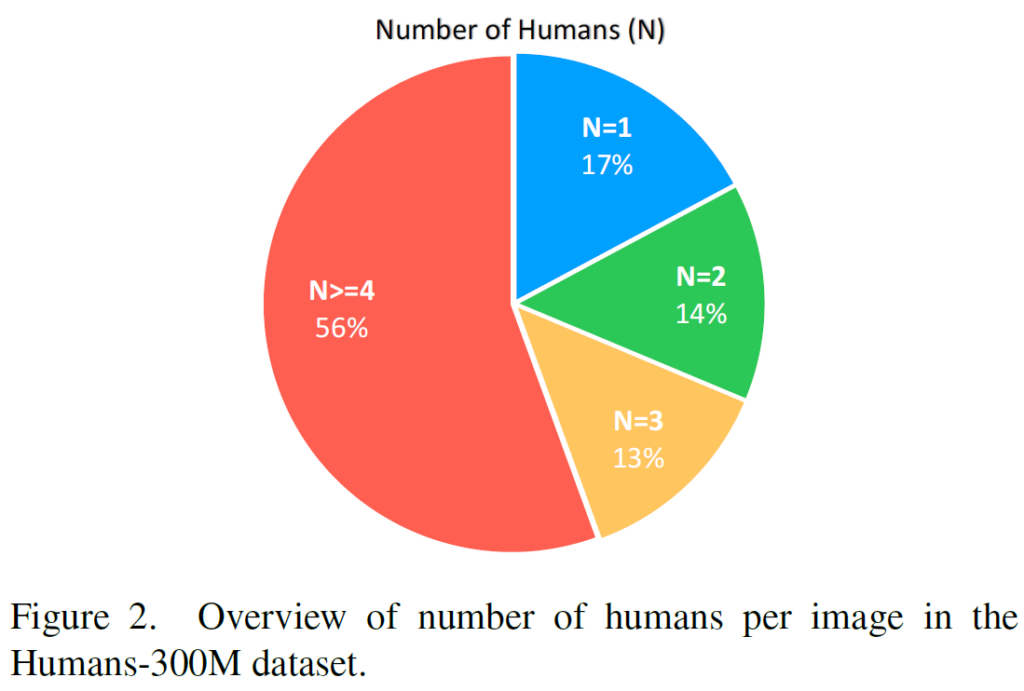
In the above figure from the paper, we can see that the majority of the images in the dataset actually have more than one human per image, where more than half of the images contain 4 humans or more.
Self-supervised Learning Pretraining
As a reminder for what is self-supervised learning, it basically means that our training data has no labels and the model learns solely from the images. And the curated human images dataset, Humans-300M, that we’ve just talked about indeed do not have any labels. The self-supervised learning pretraining approach is masked-autoencoder, or MAE in short.
Masked-autoencoder Pretraining Process
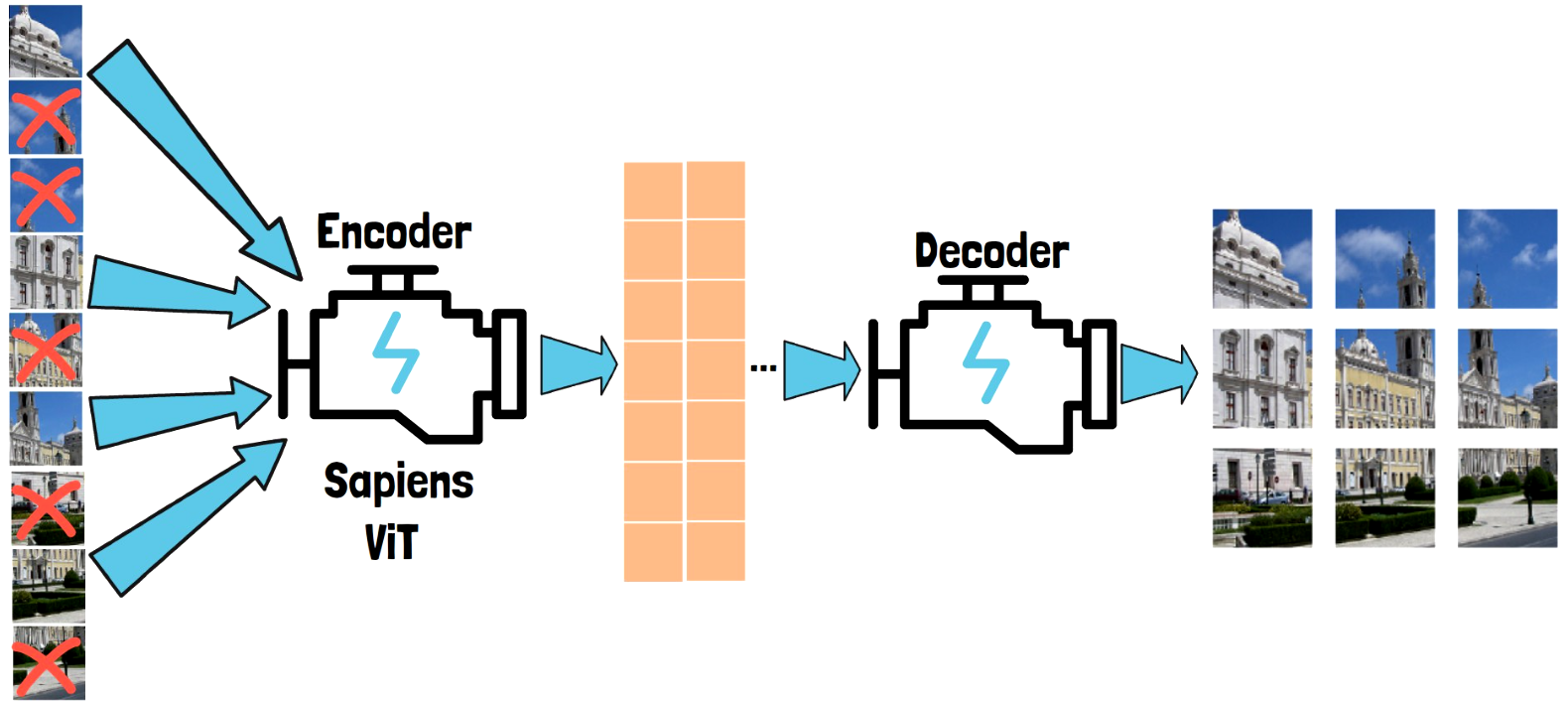
The model that we want to train is an encoder, based on the Vision Transformer (ViT) architecture, let’s call it the Sapiens ViT. Since it is a ViT, its inputs are images divided into patches, such as the one we have on the left in the illustration above. This is a single image divided into 9 patches for the example. We randomly mask some of the patches, and the non-masked patches are passed into the encoder, which yields embeddings for the visible parts of the image. The embeddings are then passed into another model which is the decoder, which tries to generate the original full image. If you are looking for bracelet. There’s something to suit every look, from body-hugging to structured, from cuffs to chain and cuffs.
Sapiens Pretraining Quality
We observe the quality of the pretraining process using the following examples from the paper. For each triplet of images (except the bottom row), the left image is a ground truth image which the model did not see in training, the middle one is after masking 75% percent of the image patches, and the right one is the image which was reconstructed by the model. Amazingly, we can barely find flaws in the reconstructed images. On the bottom row we can see a reconstructed image when increasing the masking rate to more than 75%.

Sapiens Natively Support High-resolution Images
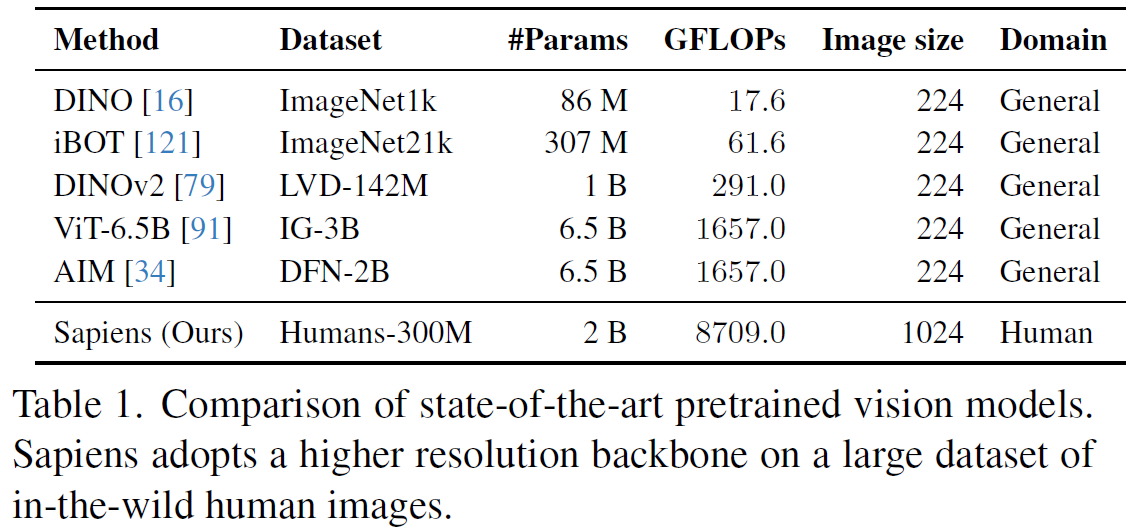
An important note is that the input images used to pretrain the Sapiens models have a resolution of 1k! This is a significant jump comparing to top vision models, such as DINOv2 where the image size is 224 X 224. We see additional comparisons between top computer vision models in the table below.
Building The Sapiens Task-specific Models
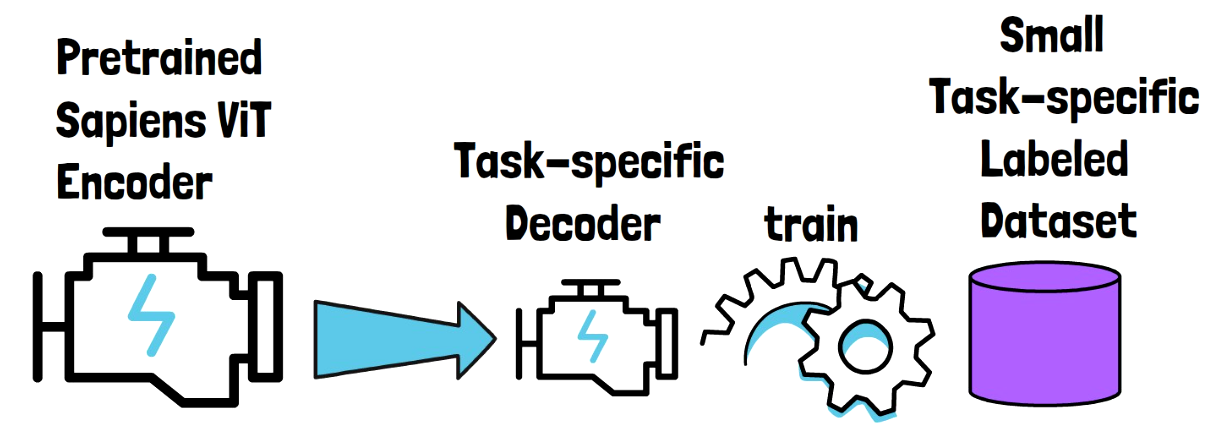
Now that we have a pretrained Sapiens ViT encoder, for each task we add a new task-specific decoder model which will consume the embeddings created by the encoder.
For each task we also have a small labeled dataset, since it is hard to construct many labeled examples for this kind of tasks. Then, we train the decoder on the labeled dataset to create the task-specific model. We also update the pretrained encoder weights. Finally, we repeat this process for each of the four tasks.
References & Links
- Paper page – https://arxiv.org/abs/2408.12569
- Video – https://youtu.be/eoJibBlexco
- Code – https://github.com/facebookresearch/sapiens
- Join our newsletter to receive concise 1 minute summaries of the papers we review – https://aipapersacademy.com/newsletter/
All credit for the research goes to the researchers who wrote the paper we covered in this post.