Several months ago, Microsoft released the first version of Orca, which achieved remarkable results, even surpassing ChatGPT on data from BigBench-Hard dataset, and the ideas from Orca 1 helped to create better language models released in the recent period.
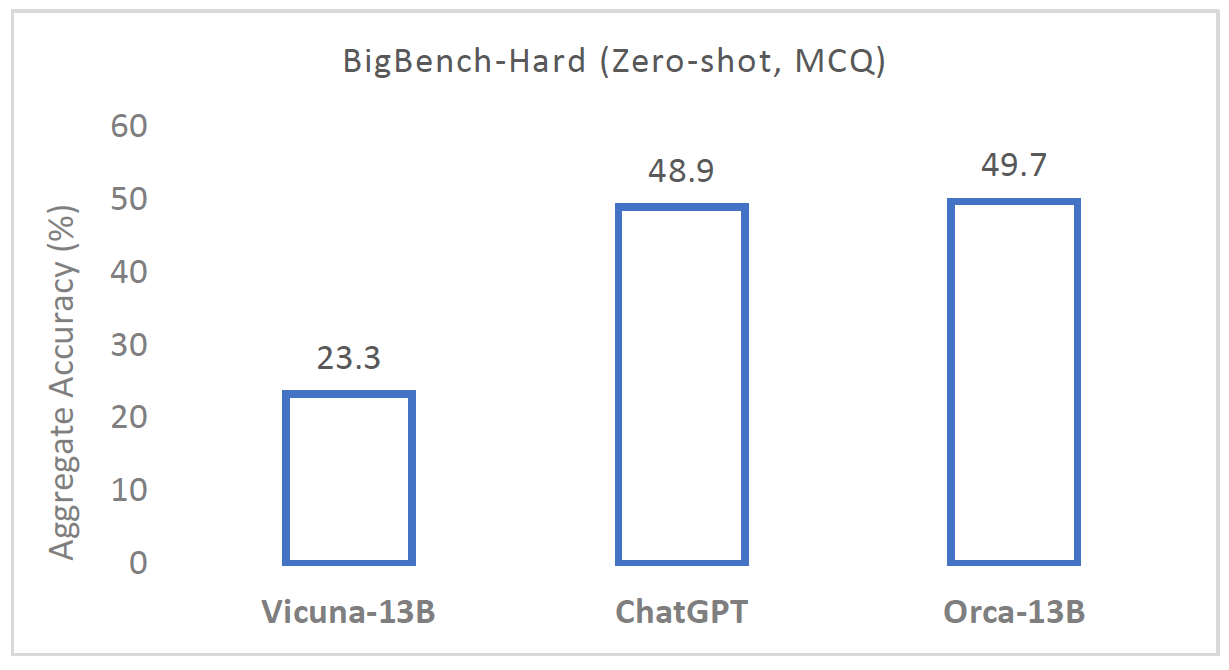
The Orca 2 model, presented in the paper we review in this post, achieves significantly better results than the previous version, and this time, Microsoft also release the model weights. We’ll explain the research paper to understand how Orca 2 was created and how it is different than Orca 1. We do not assume previous knowledge about Orca 1 and we’ll build up the needed background as we go. You may find more details about Orca 1 though in our dedicated Orca 1 post.

If you prefer a video format, then check out our video:
Imitation Learning
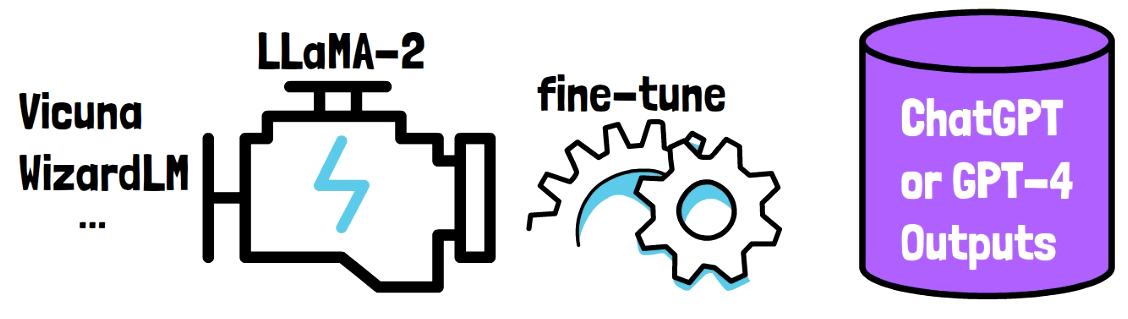
Many top large language models such as Vicuna and WizardLM take a base large language model, such as LLaMA-2, and enhance the base model capabilities by fine-tuning the base model on a dataset that was created using responses from ChatGPT or GPT-4. This process of learning from the outputs of a different model is called imitation learning. We refer to the trained model as the student model and refer to ChatGPT or GPT-4 here as the teacher model.
Orca 1 Recap
An insight from Orca 1 paper is that with imitation learning, up until Orca, the student models mostly learn to imitate the teacher model style, rather than its reasoning process, which can cause the tuned student model to generate responses in the same style as the teacher model, but wrong. To overcome that, Orca 1 paper presented explanation tuning.
Explanation Tuning
With explanation tuning, the student model learns the thought process of the teacher model. How does it work? The idea is that the reason previous imitation learning based models fail to reach higher quality is because the responses they use for fine-tuning were mostly simple and short. For example, before Orca 1, to generate a sample for training, GPT-4 would get a query that includes an instruction and an input as the prompt, and would generate a response. We see in the following example that the output is simple and short.

In Orca 1 dataset, the researchers have used detailed responses from GPT-4 and ChatGPT that explain the reasoning process of the teacher as it generates the response. In the example below, we generate a sample for Orca training using the same query as above, but with an addition of a system instruction, which provides guidelines for GPT-4 regarding how it should generate the response. Here it says: “You are an AI assistant. Provide a detailed answer so the user won’t need to search outside to understand the answer”, and we get a very detailed response that include reasoning for the answer. With this approach Orca 1 model was able to achieve remarkable results with a relatively small model, showing great potential for small models.

Orca 2 Improvements
So, what’s new with Orca 2?
- Use the right tool for the job.
- Cautious Reasoning –Learn to use the right tool for the job.
Use the right tool for the job

There are various types of system instructions, such as step-by-step, recall-then-generate, explain-then-answer, direct-answer and more, and each system instruction guides the model to use a specific solution strategy that helps the model to reach the correct answer. There are also different types of user instructions that are clustered into tasks such as text classification, open ended questions, multiple choice questions, math, and more. An important observation is that not every system instruction matches every user instruction, so for a given user instruction, one system instruction may cause GPT-4 to yield an incorrect response, while other system instruction will cause GPT-4 to yield a correct response. In Orca 2, an effort is devoted to map properly between solution strategies and user-instruction types, so the responses the model is trained on will be more accurate. How do the researchers assign system instructions to task types? They run Orca 1 on examples for a certain task type, and see which system instructions perform better on that task type. This process helps Orca 2 to learn various reasoning techniques.
Cautious Reasoning
The second improvement with Orca 2 is cautious reasoning, which means that the model learns to use the right tool for the job. In other words, cautious reasoning means deciding which solution strategy to choose for a given task. So, given a user instruction, Orca 2 as a cautious reasoner, should be able to choose the proper reasoning technique for the input instruction, even without a system instruction that will guide him to choose that strategy. How do we achieve that? the answer is called Prompt Erasing.
Prompt Erasing

With prompt erasing, at training time, we replace the system instructions in the input with a generic system instruction. For example, when training Orca 2 on the example training sample above, we replace the system instruction used to generate that response with a generic system instruction. By observing the response without the system instruction in training, Orca 2 learns to decide which solution strategy to use for each task type. If you’re asking yourself how the generic system instruction looks like, then it goes like this:
Generic System Instruction:
You are Orca, an AI language model created by Microsoft. You are a cautious assistant. You carefully follow instructions. You are helpful and harmless and you follow ethical guidelines and promote positive behavior. As we can see, it does not contain specific details about how to generate the response.
Training Orca 2

To train Orca 2, the researchers start with the 7 billion and 13 billion versions of LLaMA-2, and continue training on data from the FLAN-v2 dataset, the dataset from the first Orca paper, and a new dataset created for Orca 2 based on the two ideas we’ mentioned above of using the right tool for the job and cautious reasoning. We then end up with a 7 billion and 13 billion versions for Orca 2.
Results
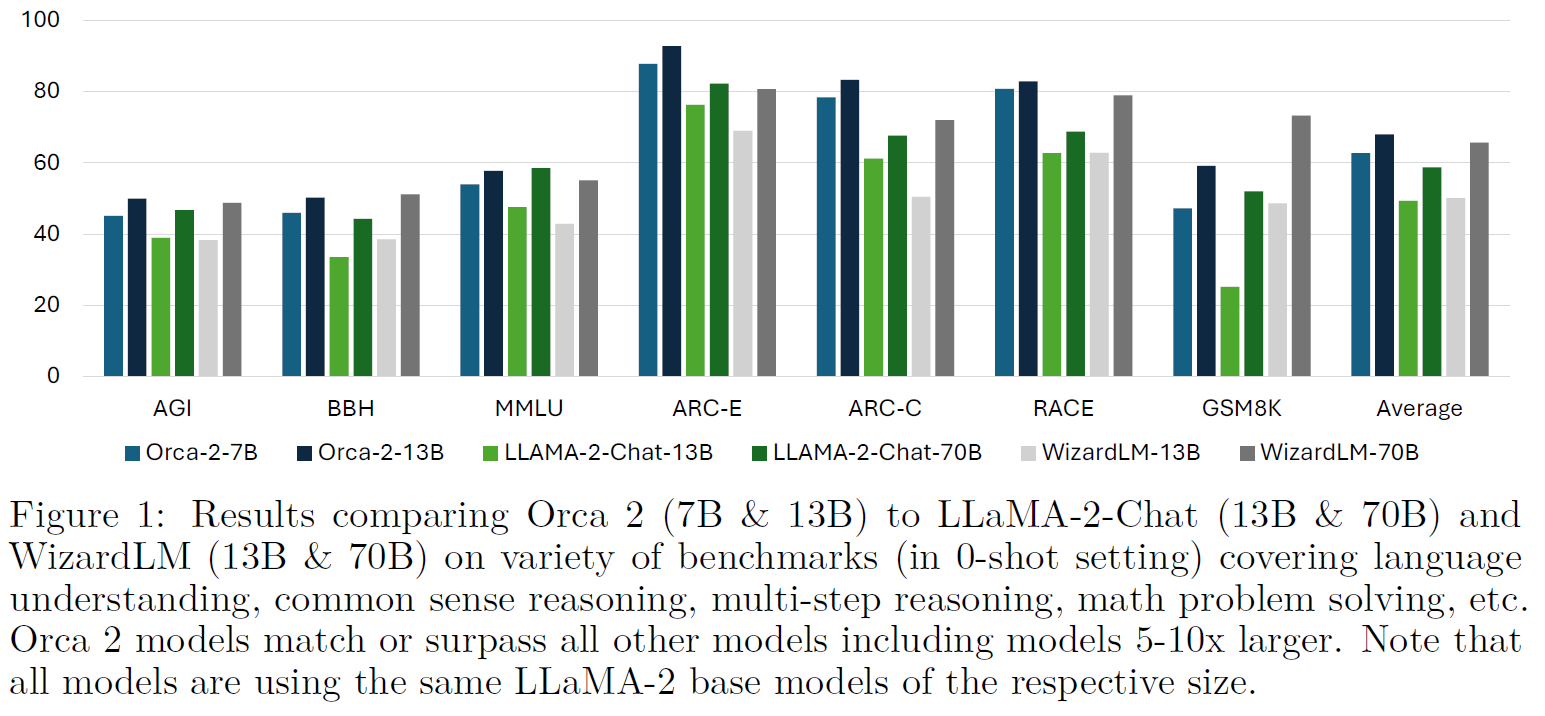
So how does Orca 2 perform comparing to other models? In the above figure from the paper, we can see various benchmarks comparison of the 7 billion and 13 billion Orca 2 versions with the 13 billion and 70 billion versions of Llama-2-Chat and Wizard LM. And we can see that except for the GSM8k math dataset, Orca 2 models outperform or match the other models, even the 70 billion versions which are much bigger than Orca2, which is obviously very impressive.
References & Links
- Paper page – https://arxiv.org/abs/2311.11045
- Model page – https://huggingface.co/microsoft/Orca-2-13b
- Video – https://youtu.be/fDcBg2JcrsM
- Join our newsletter to receive concise 1 minute summaries of the papers we review – https://aipapersacademy.com/newsletter/
All credit for the research goes to the researchers who wrote the paper we covered in this post.