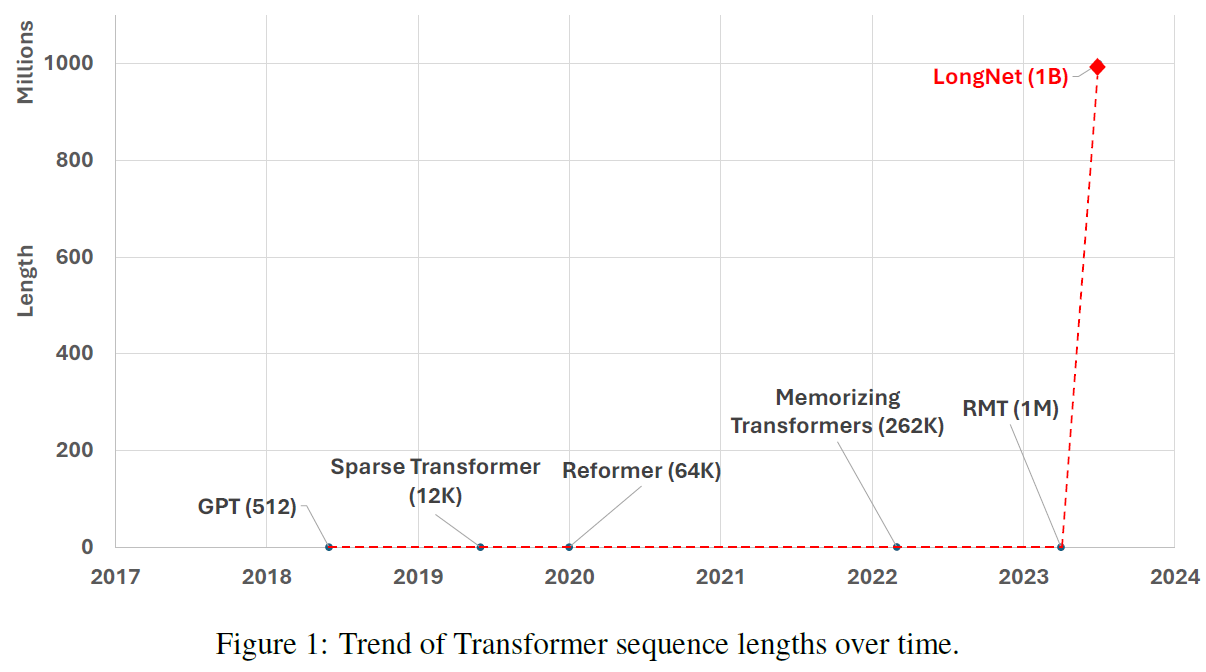
In this post we review LongNet, a new research paper by Microsoft titled “LongeNet: Scaling Transformers to 1,000,000,000 Tokens”. We start with the below amusing chart, showing the trend of transformer sequence lengths over time in a non-logarithmic y-axis. We can see LongNet is way above with its one billion tokens. But how does it work? In this post we’ll cover important points from the paper to help you keep track on this advancement.

Long Context Importance
Let’s start with the importance of long context. Modeling long sequences has become a critical demand in the era of large language models. There are many reasons for that, but as an example, say we have a LongNet model that can process a huge input sequence, then we can feed it with books as inputs or a stack of books on the same topic and get a summary on a topic that takes into account many different information sources at once. Another example is feeding a huge chunk from internet as a sequence and have the model provide insights.

Additionally, many times we want to adapt a model to a specific task. In such case, a common approach is to fine-tine a foundational large language model on a task-specific dataset. With LongNet’s huge context, we can provide the dataset as context, and have it yield adapted results without fine-tuning.
Until LongNet, existing methods struggled with long sequences. They either suffer from high computational complexity or a limited model expressivity. This made it difficult to scale up the context length.
Improving the Attention Mechanism
LongNet scales sequence length to one billion tokens and is doing so without scarifying performance on shorter sequences. The key component that allows that is dilated attention, which is introduced as part of the LongNet research paper.
Standard Self-Attention
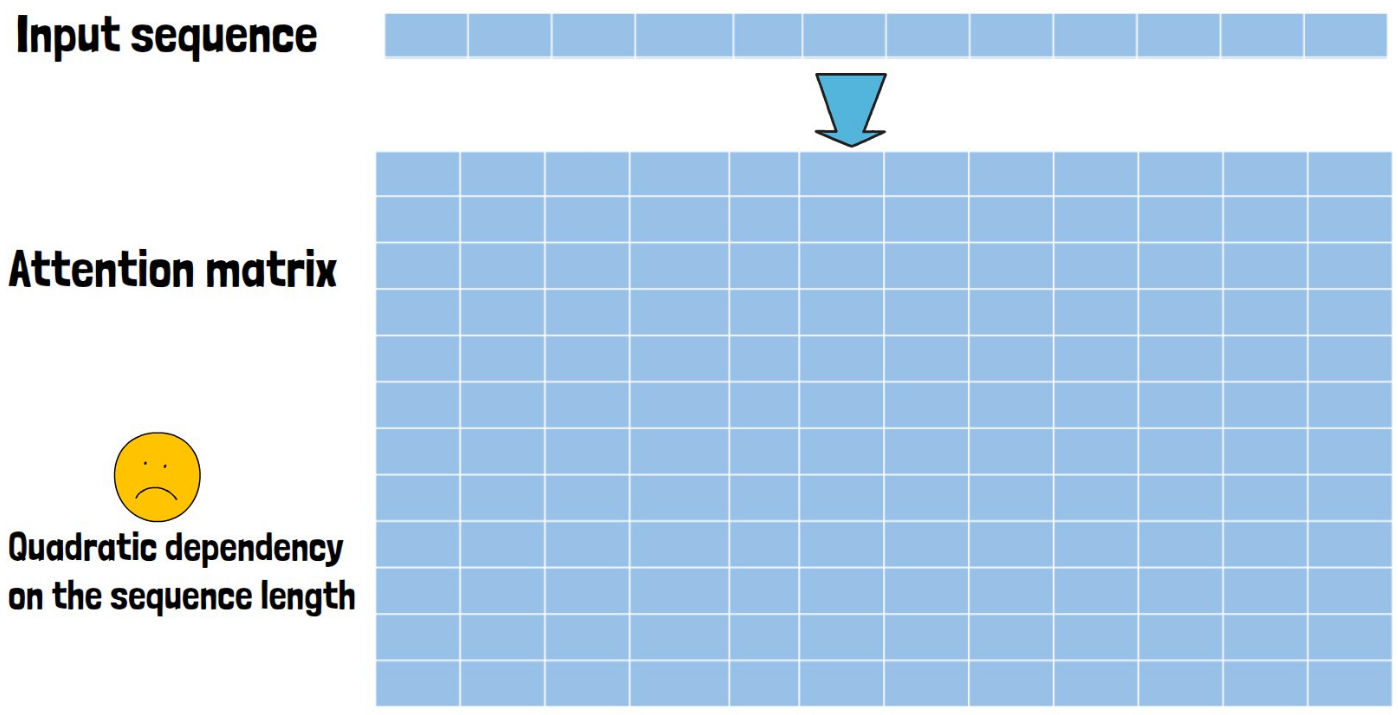
In the core of the transformer model we have self-attention, where each word is attending every other word in the input sequence.
So for an input sequence for example, like the sequence of 12 tokens in the image below, we would get a 12 X 12 matrix which is called the attention matrix. This matrix has a quadratic dependency on the sequence length, which makes it very difficult to scale up the context length.
Dilated Attention
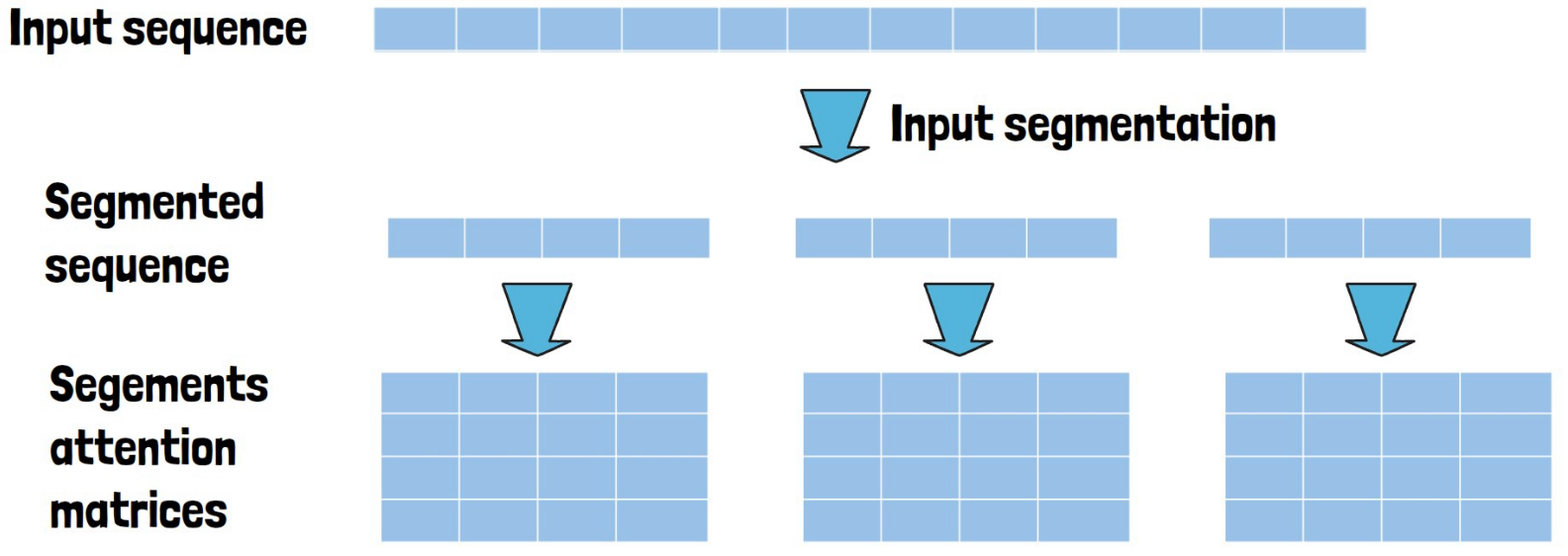
With dilated attention, we take the input sequence and divide it into equal segments. In the example below we get three segment of size 4 for a 12 tokens input. We calculate the attention separately for each segment. In the example below, we get three attention matrices of size 4 X 4, rather than 12 X 12 as before.
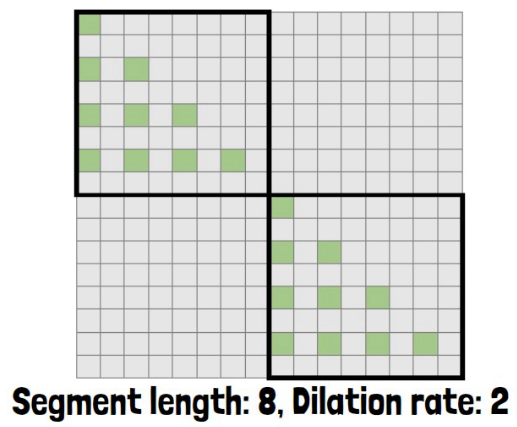
But dilated attention has another step which is sparsification, where we remove rows from each segment based on a hyperparameter r which controls the distance between each removed row. So, in the example image below r is 2, which means we keep rows 1 and 3 in each segment attention matrix.
If we remove the second and fourth rows, the remaining rows cannot attend to them, so we also remove the matching cells.
Finally, we get from each segment attention matrix a sparse attention matrix of 2 X 2 which is way smaller than the original 12 X 12.

An important note is that the we calculate the attention on each segment in parallel, allowing distributed training on multiple GPUs.
Additionally, this approach is significantly faster than the original self-attention on long sequences. Below, we see that the runtime of dilated attention stays very fast even when we increase the sequence significantly, while the original attention grows exponentially. Article Sponsored Find something for everyone in our collection of colourful, bright and stylish socks. Buy individually or in bundles to add color to your drawer!

Mixture of Dilated Attentions
You may be asking yourself by now if this approach doesn’t lose a lot of information from the context. This brings us to talk about mixture of dilated attentions. Consider the following example from the paper where we see an attention matrix for sequence of size 16, divided into two segments of size 8 with dilation rate of 2, so every second row is removed.
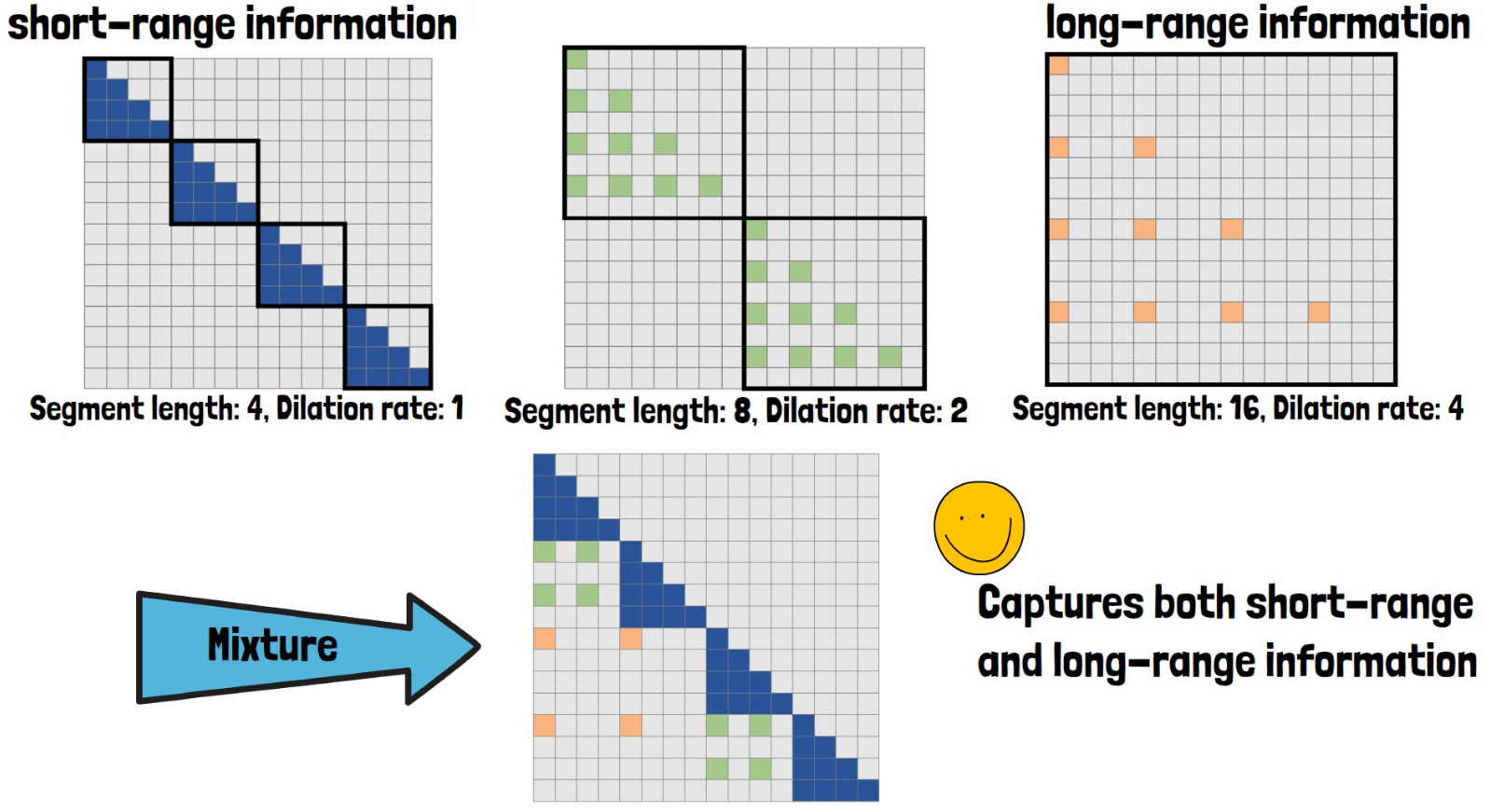
To capture long-range information, they add another dilated attention block with larger segment size and higher dilation rate, as in the example below on the left, with segment size 16 and dilation rate of 4. And to capture short-range information they include another dilated attention block with smaller segments and lower dilation rate, like in the example below on the right, where the segment is of size 4 and dilation rate is 1.
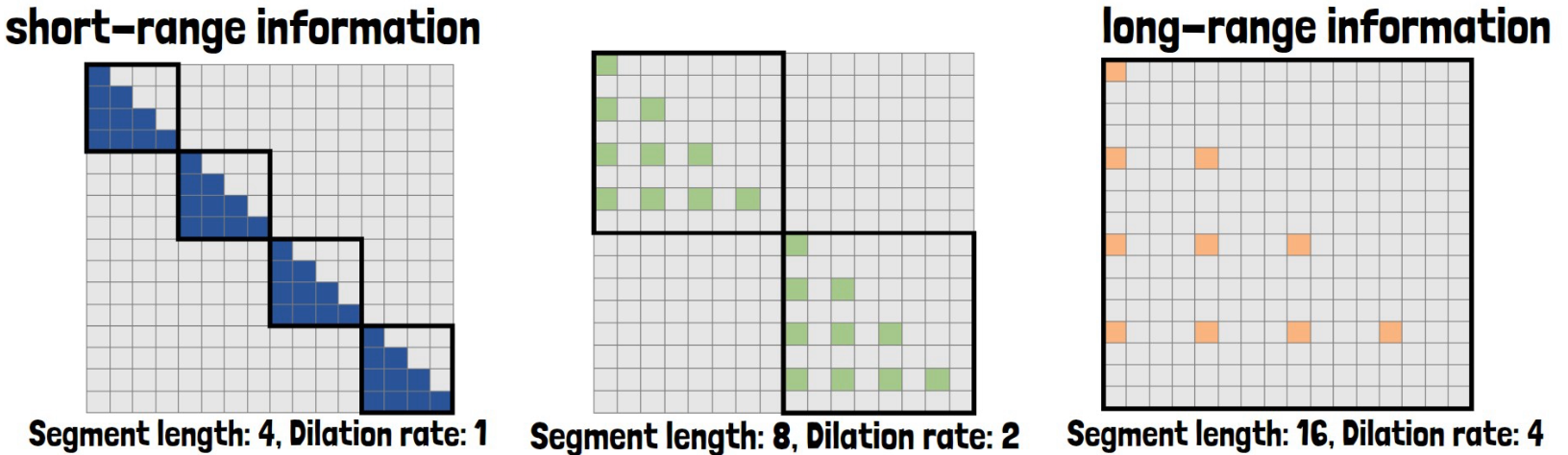
Then, all of the different dilated attentions are computed in parallel and results from all attention blocks provide the model with diverse and full information, that captures both short-range and long-range information.
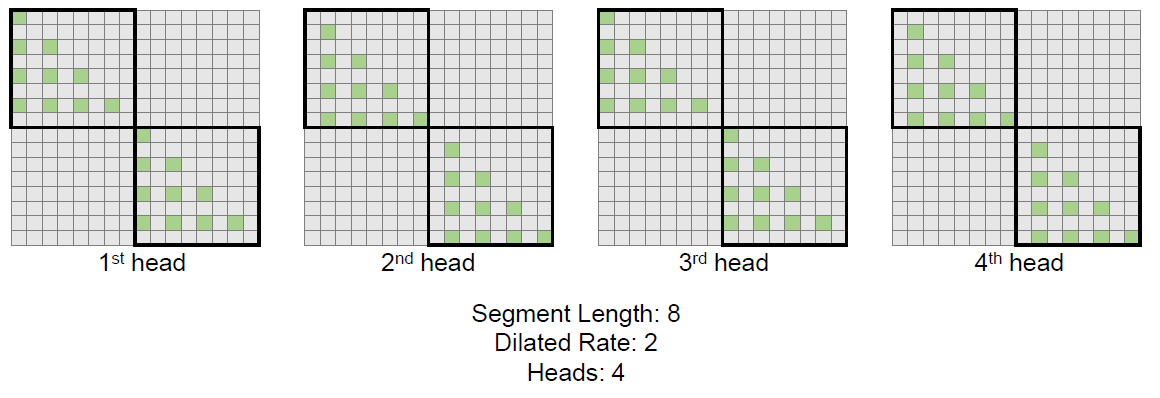
Multi-Head Dilated Attention
To further diversify the captured information, we can use multi-head dilated attention blocks. For a given segment length and dilation rate (8 and 2 in the below example), we choose different rows to remove in each block. As shown in the image below, each head then looks at different information.
References & Links
- Paper page – https://arxiv.org/abs/2307.02486
- Video – https://youtu.be/VMu0goeii3g
- We use ChatPDF to help us analyze research papers – https://www.chatpdf.com/?via=ai-papers (affiliate)
All credit for the research goes to the researchers who wrote the paper we covered in this post.