Large language models (LLMs) have literally conquered the world by this point. The native data modality used by large language models is obviously text. However, given their power, an active research domain is to try to harness their strong capabilities for other data modalities, and we already see LLMs that can understand images. Today we’re diving into an intriguing paper from NVIDIA, titled: “LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models”.
Introduction to LLaMA-Mesh
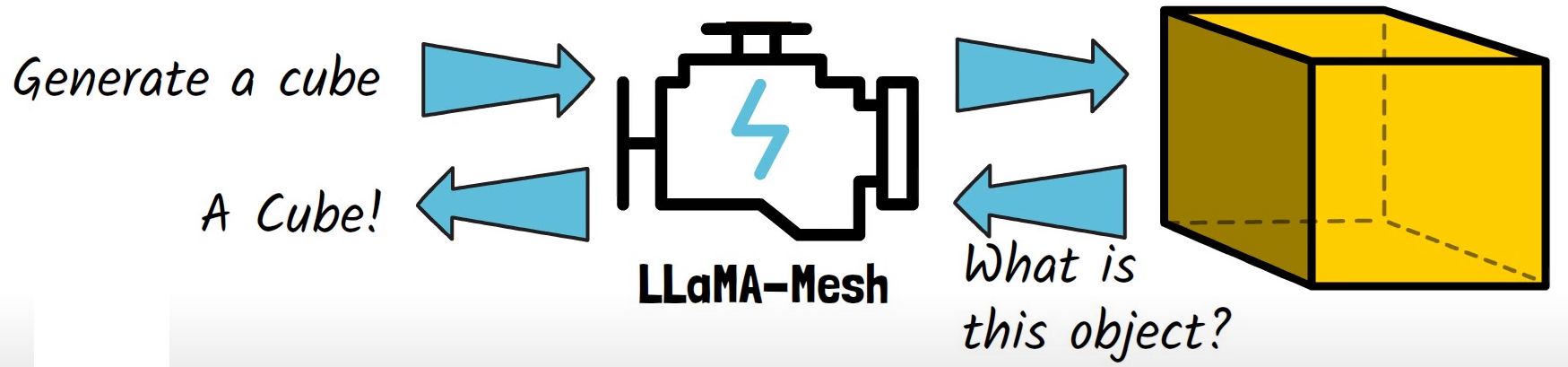
NVIDIA researchers were able to transform a LLM into a 3D mesh expert, teaching it to understand and generate 3D mesh objects, calling it Llama-Mesh. Given a prompt, Llama-Mesh can generate a 3D mesh object, such as a cube. And it works the other way around as well. We can feed the LLM with a cube, ask it what shape it is, and it can recognize and say it is a cube. Various examples can be seen in the following demo from Nvidia’s blog:
How Can LLaMA-Mesh Work With 3D Mesh Objects?
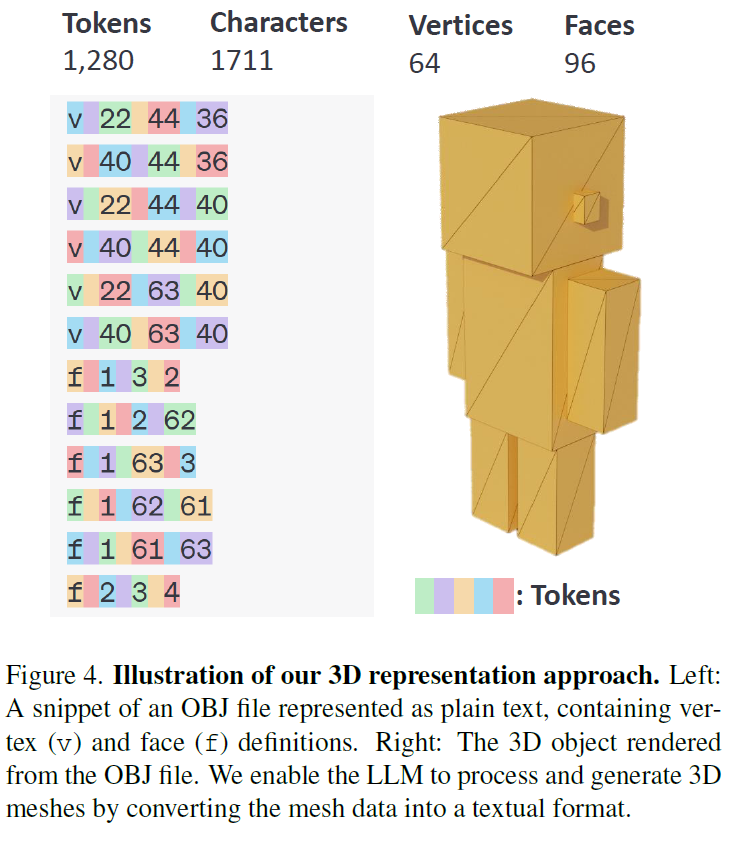
Let’s now understand how a large language model, which was trained on text, can understand and generate 3D objects. The answer is by using a format called OBJ, which is a text-based standard for 3D objects. In the above example from the paper, we see a 3D object of a person alongside a sample of its OBJ representation. The rows that start with “v” represent vertices in the three-dimensional space using x, y, and z coordinates, indicating the positions of the object’s points. The rows that start with “f” represent faces, specifying the list of vertices that make up a surface. By reading and generating this format, the LLM can handle 3D objects, with the output rendered using standard tools for the format.
A notable aspect of this format, which can be shown in the below figure from the paper, is that the vertices’ coordinates are typically provided as decimal values. However, to reduce the number of tokens, the researchers converted these coordinates to integers. This quantization process significantly saves the model’s cost, trading off some precision for efficiency.

Building the LLaMA-Mesh Model

The researchers observed that some spatial knowledge is already embedded in pretrained LLMs, possibly due to the inclusion of 3D tutorials in the pretraining data. However, the initial quality of 3D object generations was not satisfactory. The model which the researchers chose to work with is LLaMA-3.1-8B-Instruct. To improve its mesh understanding and generation capabilities, the researchers constructed a dataset of text-3D instructions. Then, they fine-tuned the model on that dataset using supervised fine-tuning.
Examples from the LLaMA-Mesh Training Dataset

We can see examples from the dataset in the above figure from the paper. The first type of samples (a) is for mesh generation, where an object from an existing dataset is used to automatically create a sample, by using the object label to create a prompt asking the model to generate the object, and use the actual object as the response.
The second type of samples (b) are for mesh understanding, where an object from an existing dataset. For this type, the object is used in the prompt, and an instruction is created for the model to recognize the object, using the label of the object in the response. Additional samples (c,d) were used using LLM-augmentation methods, to create dialogue samples.
Results
LLaMA-Mesh Generations Quality
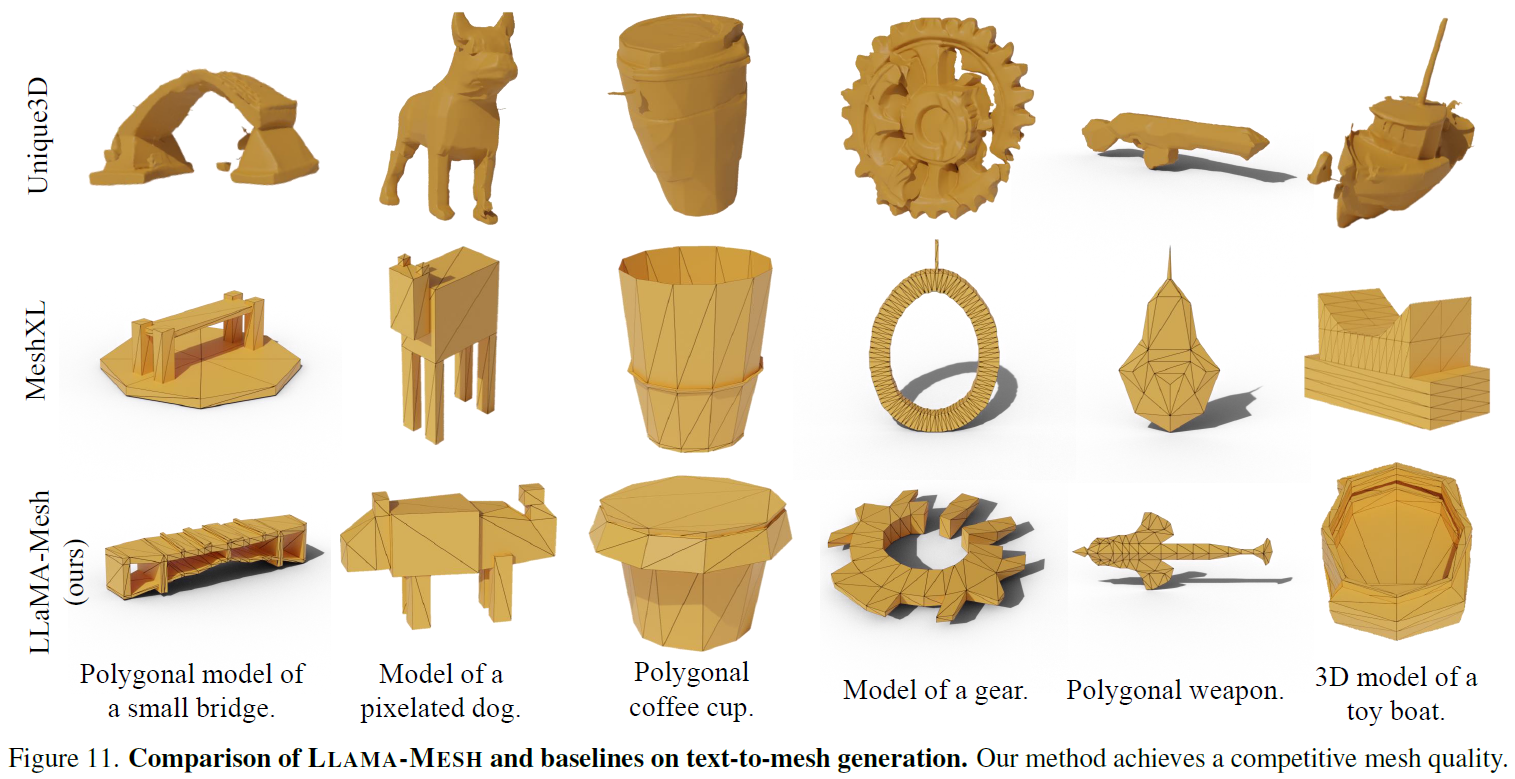
In the above figure, we can see a comparison of generations with other strong mesh generation models. LLaMA-Mesh generations are in the bottom row, showing competitive quality with the other models. However, LLaMa-Mesh has the advantage of being able to communicate with both text and 3D objects.
Does LLaMA-Mesh Preserve Language Capabilities?
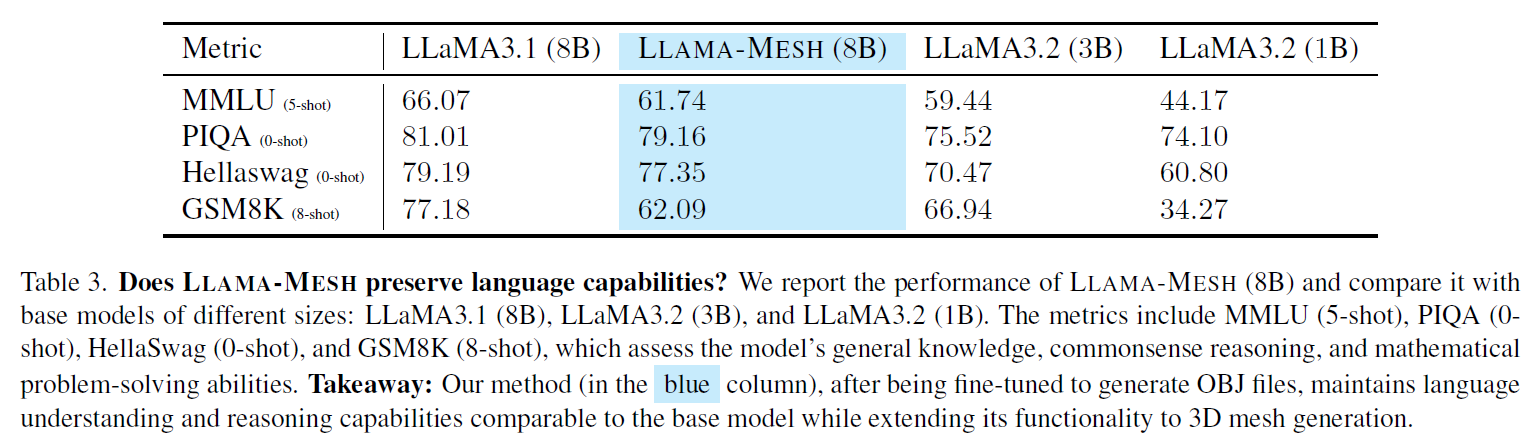
We can see another interesting result in the above table, where the researchers check whether LLaMA-Mesh preserves the language capabilities of the pretrained model. Observing the model results in blue, there is some hit in performance comparing to the pretrained 8 billion parameters model. However, the results are still better than the 3 billion parameters version.
References & Links
- Paper Page
- GitHub Page
- NVIDIA Blog
- Video Summary
- Join our newsletter to receive concise 1 minute summaries of the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.