Motivation
Transformers – Dominant LLM Architecture
Large language models (LLMs) today commonly utilize Transformers as their backbone architecture. Transformers have proved to be extremely capable, driving LLMs to achieve remarkable results that revolutionize our lives. However, their memory consumption and efficiency are quadratically dependent on the sequence length, making them very expensive to train and run.
Mamba Is An Efficient Alternative?
Given Transformers efficiency issues, State Space Models (SSMs), such as Mamba, gain interest due to their linear dependency on the sequence length, allowing them to be extremely fast. Despite Mamba’s impressive speed, transformers remain the top choice due to their overall better performance. Specifically, SSMs struggle with memory recall tasks, meaning their ability to utilize specific information from previous contexts is not as good as that of Transformers, especially if the context is large. Perhaps all Mamba needs is a little attention?
Introducing Hymba
Today, we’re diving into an intriguing research paper from NVIDIA titled “Hymba: A Hybrid-head Architecture for Small Language Models.” This paper introduces a hybrid approach that unites the strengths of both Transformers and SSMs, offering a balanced solution for high performance and efficiency. NVIDIA has also released a Hymba model that achieves state-of-the-art results for small language models, demonstrating the potential of this method.

Understanding the Hybrid-Head Module
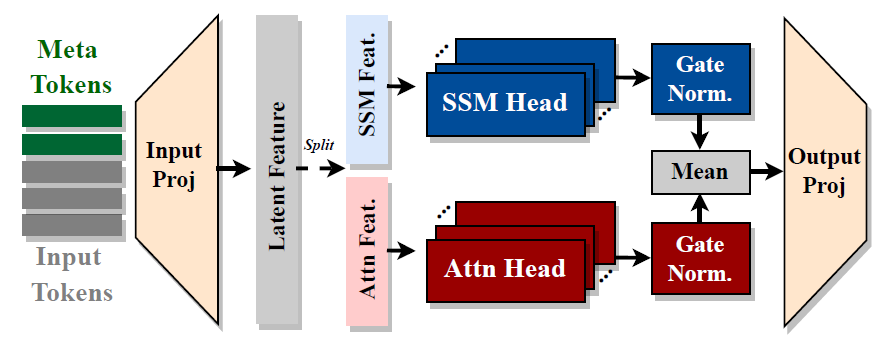
Let’s jump in to understand the hybrid-head module in Hymba, the building block of the model. We’ll use the above figure from the paper to guide us, starting with a high-level description and gradually adding more details.
On the left, we have the input tokens. Additionally, meta tokens are added at the beginning of the sequence. These are learnable tokens, and we’ll explain their role a bit later. A linear input projection layer prepares the input to be processed by the core of the module.
At the core, we have parallel attention heads and SSM heads. The output from the input projection layer is split, so each head gets the input it needs. For example, for the attention heads, we obtain the K, V, and Q matrices, calculated using dedicated weight matrices as part of the linear projection layer. Similarly, the state space model heads get the inputs they need.
Once the heads process the inputs, we combine their results. However, the researchers noticed that the magnitude of outputs from the state space model heads is consistently larger than those from the attention heads. To address this, outputs of both types of heads first pass through a normalization step before being averaged together. Finally, a linear output projection layer projects the output for the next component in the model.
Hymba Hybrid Approach Vs Previous Methods
It is worth mentioning that previous hybrid models combined attention heads with SSM heads sequentially, rather than in parallel. This may be less ideal when handling tasks that are not well suited for a specific head type. Inspired by multi-head attention in Transformers, where different heads learn to take different roles, Hymba is built with parallel heads. This allows each head to process the same piece of information in distinct ways, inheriting the strengths of both types of heads.
Hymba Human Brain Analogy
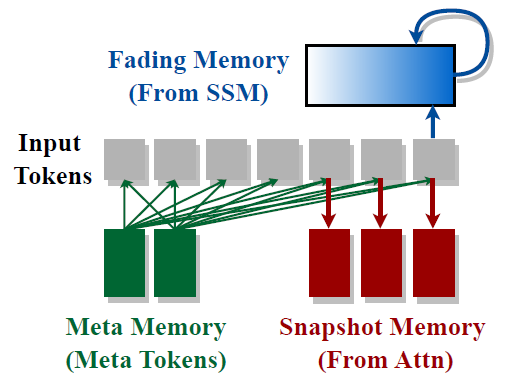
Let’s now take a moment to interpret the hybrid-head module using an analogy to the human brain.
In the human brain, different types of memory processes work together to store and recall information. Imagine that the attention heads in Hymba are like snapshot memories. These are the detailed recollections we have of specific moments or events, allowing us to remember precise details when needed. Attention heads in Hymba work similarly, providing high-resolution recall of specific information from the input sequence.
On the other hand, the state space model (SSM) heads in Hymba function more like fading memories. These are the types of memories that help us summarize the overall gist of past events without retaining all the details. SSM heads efficiently summarize the broader context, ensuring that the model can process long sequences without the computational burden of maintaining high-resolution details.
By combining these two types of memories within the same layer, Hymba’s hybrid-head module mirrors the way our brains balance detailed recall with efficient summarization. This design enables the model to handle various types of information flows and memory access patterns more effectively.
Meta tokens in Hymba play a role similar to metamemory in the human brain. Metamemory helps us recognize where to find needed information in our memories. Similarly, meta tokens guide the model to focus on relevant information. This also helps to mitigate attention drain, where certain tokens (often called “sink tokens”) receive disproportionately high attention weights.
Meta Tokens – A Deeper Look
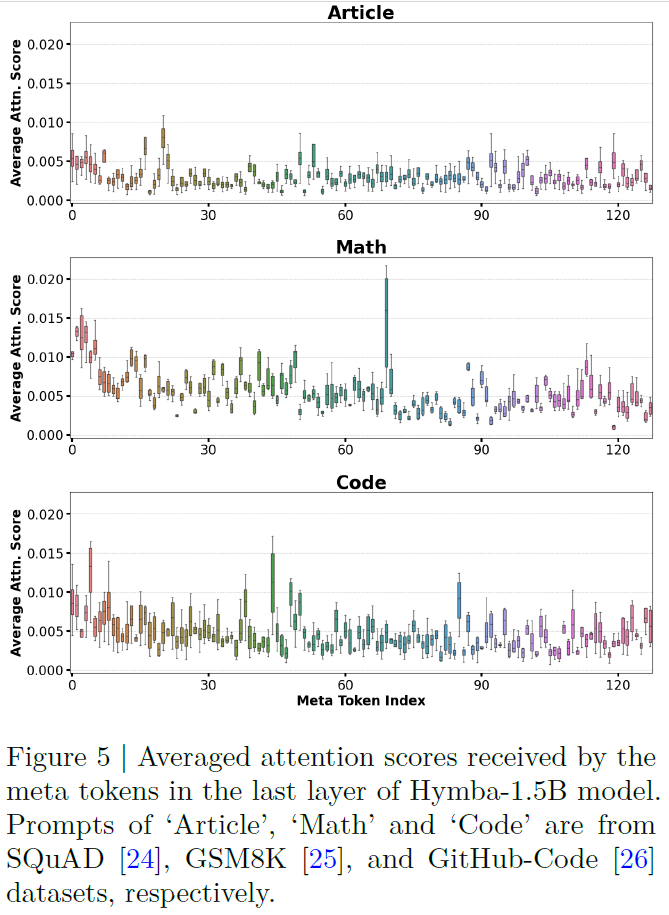
In the above figure from the paper, we see the average attention scores received in the last layer of the Hymba model, for three different task domains. Noticeably, different meta tokens are activated for the code domain compared to those of the math and article domains. It could be an interesting extension to try and use different meta tokens for different tasks. Practically, meta tokens play another role of helping to mitigate attention drain, where certain tokens (often called “sink tokens”) receive disproportionately high attention weights.
Hymba’s Overall Architecture
Now that we’ve covered the hybrid-head module, let’s take a step back and look at Hymba’s overall architecture.
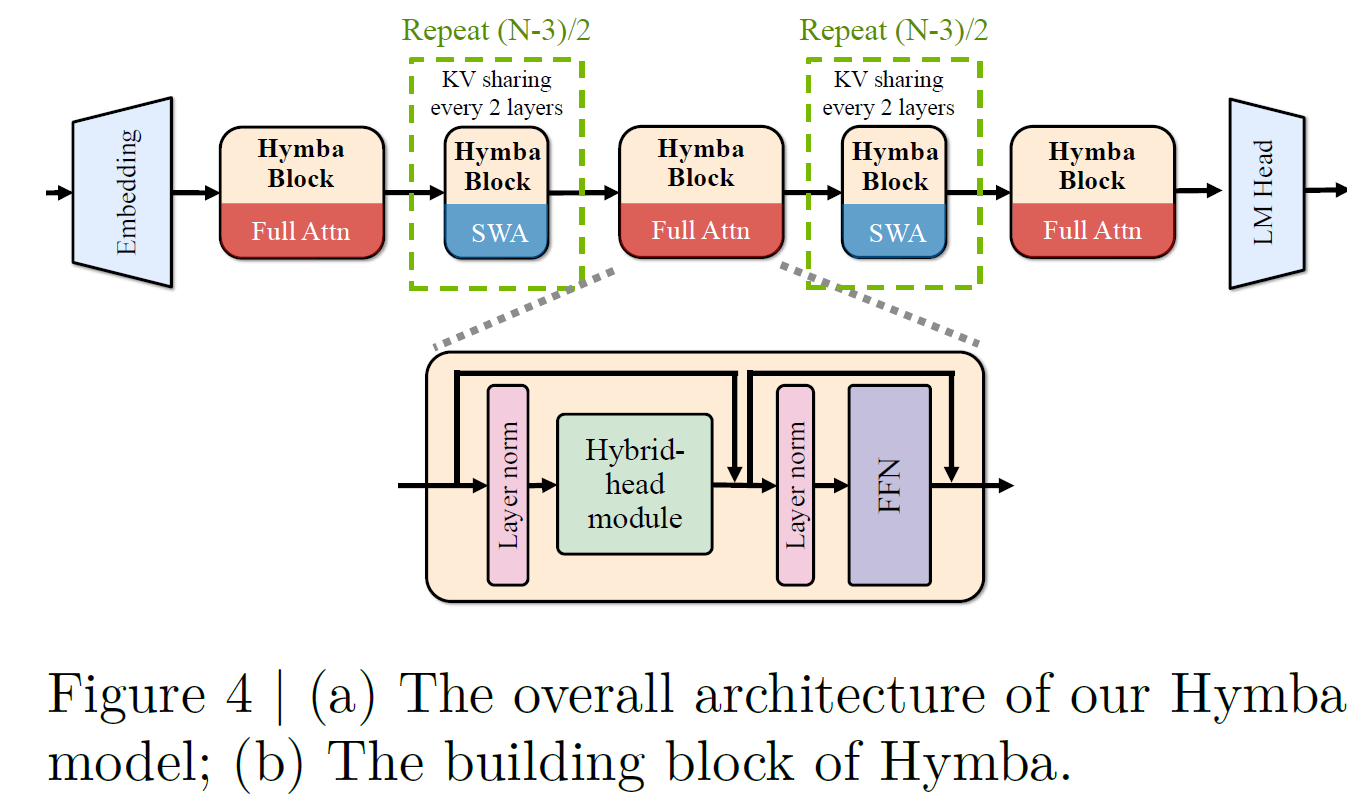
Hymba is built by stacking multiple Hymba blocks. Each block consists of a normalization layer, followed by the hybrid-head module, another normalization layer, and a feedforward network (FFN). Notably, only the first, middle, and last blocks utilize full attention, which uses all of the tokens. All other blocks utilize a technique called sliding window attention (SWA). This approach allows the model to focus on local context within a sliding window, significantly reducing the size of the key-value cache required for attention, while still gaining global attention thanks to the three full attention blocks.
Additionally, for the sliding window attention blocks, Hymba employs cross-layer key-value (KV) cache sharing between adjacent blocks. Instead of each block maintaining its own separate KV cache, adjacent blocks share their KV caches. This sharing strategy reduces redundancy and memory usage, resulting in a more efficient model. This follows recent research showing that KV caches in adjacent layers share a high similarity.
Benchmark Results
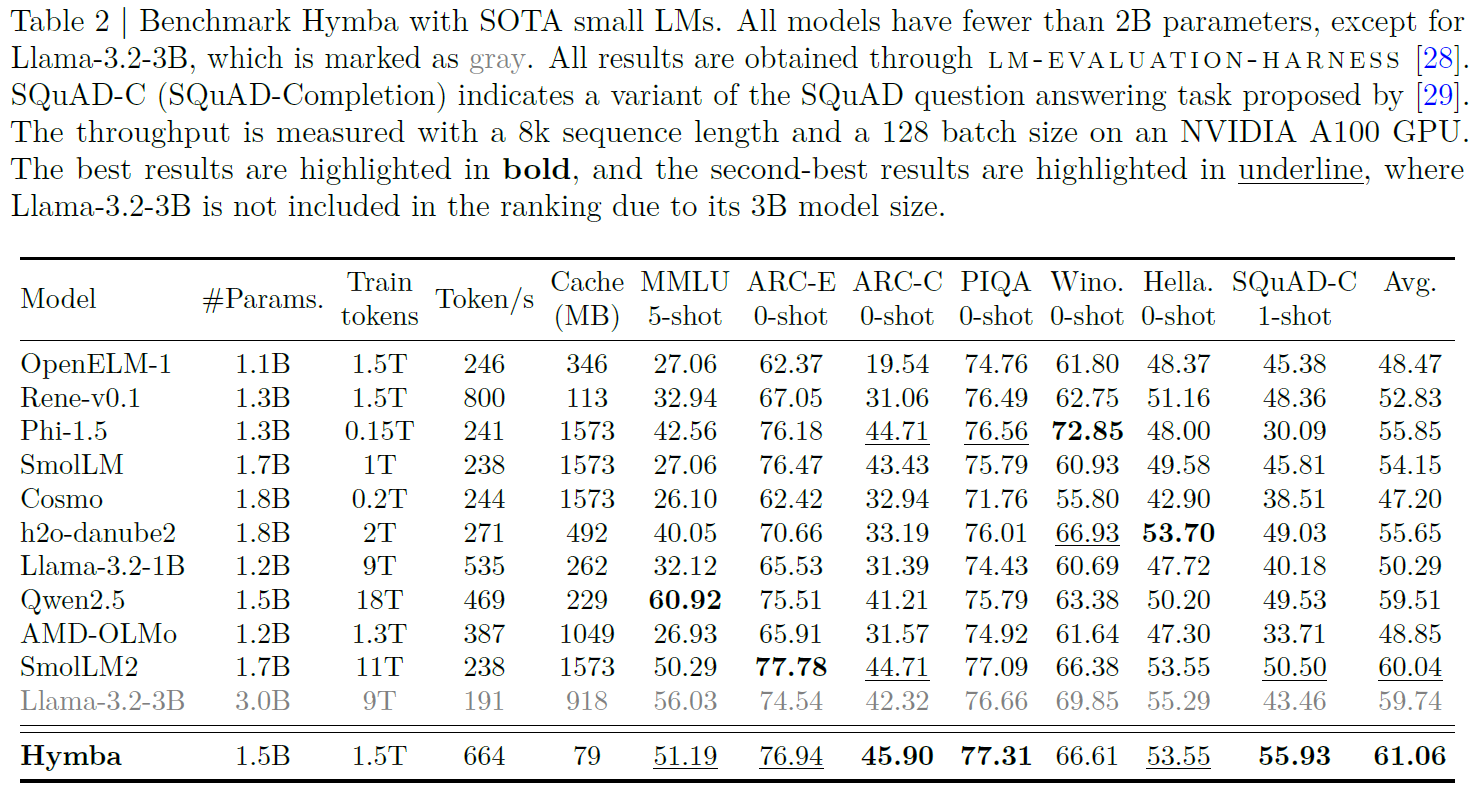
In the above table, we see a comparison of Hymba with state-of-the-art small language models. All models have less than 2 billion parameters except for Llama-3.2-3B, where the evaluated Hymba model has 1.5 billion parameters. In the right column, which shows the average performance, we see that Hymba outperforms all other models, which is extremely impressive. Furthermore, we also see that Hymba was trained on 1.5 trillion tokens, while the other top 3 models behind it were trained on 9 trillion tokens or more.
Ablation Studies: Evaluating Architectural Decisions
Before scaling Hymba to 1.5 billion parameters, the researchers conducted ablation studies with a 300 million parameters model to evaluate the importance of various architectural decisions. This is a great way to recap the ideas we’ve discussed in this post.
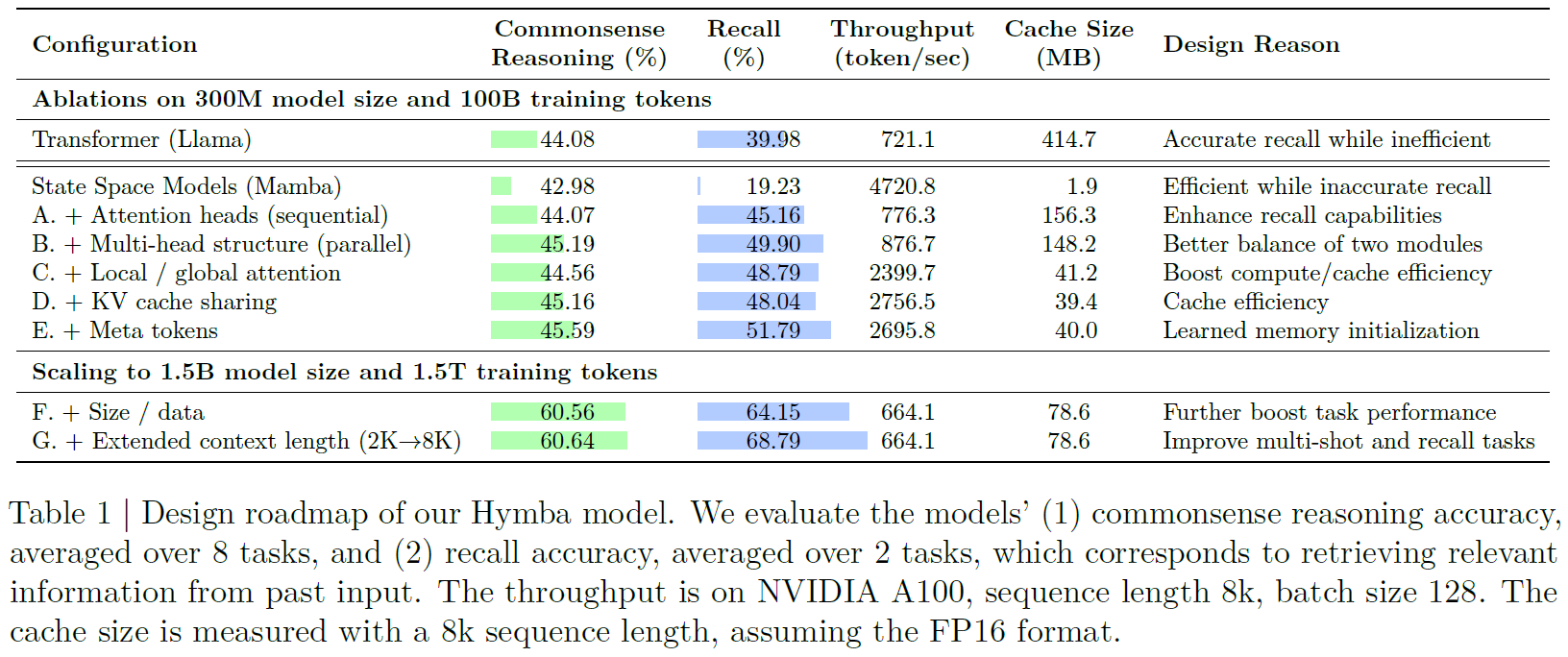
At the top two rows, we see results for Transformer and Mamba before applying Hymba’s innovations. The Transformer shows high recall compared to Mamba (40% versus 19%). However, Mamba is significantly more efficient, processing many more tokens per second and consuming almost no memory compared to the Transformer.
Next, at rows A and B we see the results for models with hybrid Mamba and attention heads. Row A represents sequential heads, and row B represents parallel heads, as done in Hymba. While the sequential heads already significantly improve the results and reach high recall, the parallel heads architecture achieves even better results.
In row C, we see the impact of using sliding window attention for all blocks except the first, middle, and last ones. This technique significantly boosts compute and cache efficiency, with only a slight performance hit. In row D, we see that the key-value cache sharing between adjacent layers further improves cache efficiency, as expected, without damaging performance. Lastly, adding the meta tokens nicely improves the results without a significant efficiency hit.
References & Links
- Paper page
- GitHub page
- Models
- Video
- Join our newsletter to receive concise 1 minute summaries of the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.