Introduction
Large language models (LLMs) have demonstrated incredible reasoning abilities, penetrating an increasing number of domains in our lives. These models achieve such capabilities by pretraining on vast amounts of human language. A common and powerful method to extract the most accurate responses from these models is called Chain-of-Thought (CoT), where we encourage the model to generate solutions step-by-step, providing reasoning for reaching the final answer. However, the reasoning of LLMs must be generated in words, which imposes a fundamental constraint on the model.
Neuroimaging studies have shown that the region of the human brain responsible for language comprehension and production remains largely inactive during reasoning tasks. This suggests that language is optimized for communication, not necessarily for complex problem-solving. If humans do not always translate thoughts to words as part of the reasoning process, why should AI?
In this post, we dive into an intriguing paper by Meta, titled: “Training Large Language Models to Reason in a Continuous Latent Space.” This paper aims to break free from the constraint of word-based reasoning by allowing LLMs to reason in a continuous latent space using a new method called COCONUT, short for Chain of Continuous Thought.

CoT vs Chain of Continuous Thought (Coconut)
Let’s jump in to describe how the Chain of Continuous Thought method works. We’ll use the following figure from the paper, which compares the Chain-of-Thought method with the Chain of Continuous Thought method. We’ll start wit ha short description of Chain-of-Thought and then describe the Coconut method.
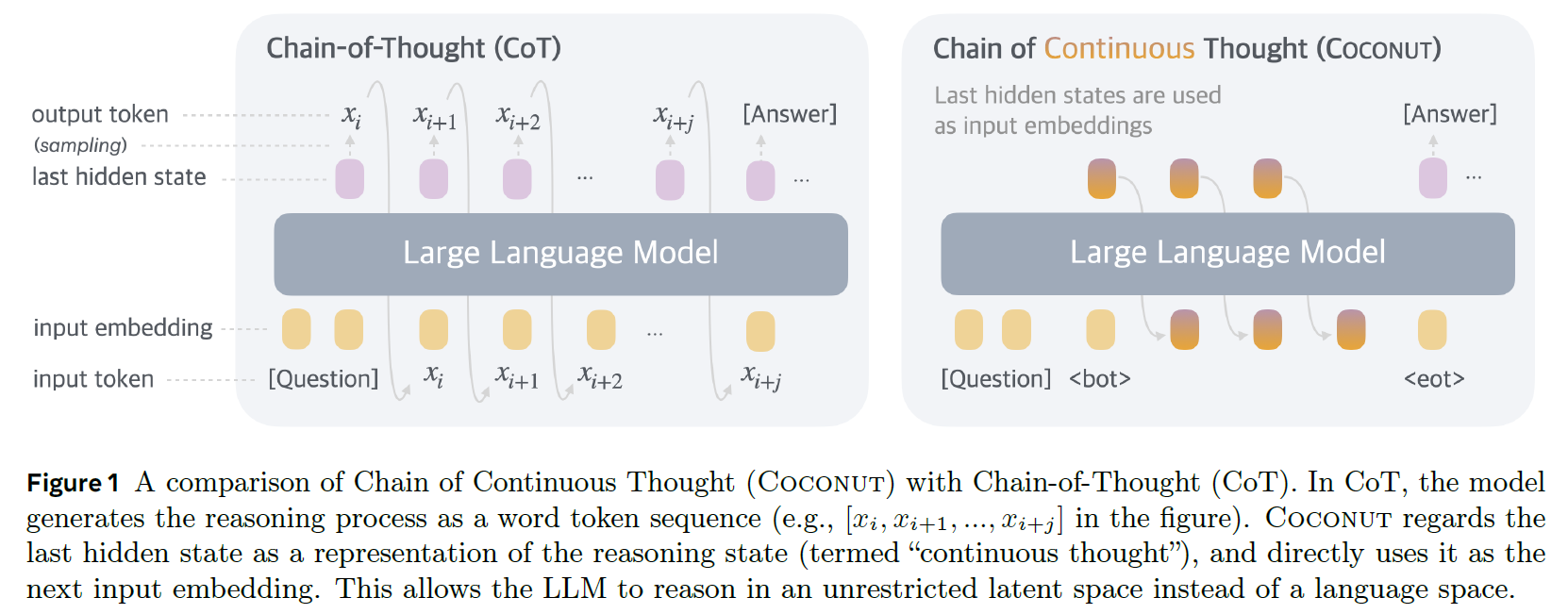
The Chain-of-Thought (CoT) Method
On the left of the figure above, we see an illustration of how the Chain of Thought method works. Initially, we start with a question, which is embedded into input tokens to be fed into the LLM. We then receive the first token in the response, which is the start of the reasoning trace of the model. The token is retrieved from the last hidden state of the model, which is the output of the final layer of the backbone Transformer. We then repetitively do more forward passes of the model, each time providing it with the question and the reasoning process tokens that we have until the current stage. Once the model has generated the entire reasoning trace, we continue to do forward passes to generate the final answer.
The Chain of Continuous Thought (Coconut) Method
We are now ready to understand the difference in the new Coconut method. With the Coconut method, the LLM alternates between language mode and latent thought mode. In language mode, the model operates as a standard language model, generating the next token. In latent mode, it uses the last hidden state as the input for the next step. This last hidden state represents the current reasoning state, termed as a “continuous thought”.
In the figure above, on the right, we see that we start with a question, along with a special <bot> token, which marks the beginning of the latent thought mode. The model processes the question and yields the last hidden state, which before, we translated to a language token, but now we don’t. Instead, we feed that hidden state back to the model as an input embedding, following the embeddings of the question and the special token. We proceed with this process iteratively, where in each phase, we have more thought tokens used in the input. Finally, we have another special <eot> token, which marks the end of the latent thought mode and the start of the language mode. From here, the model acts as a standard language model, generating the tokens of the final answer.
Training Procedure
Let’s now move on to describe the training procedure for the Chain of Continuous Thought method. This process is designed to teach the large language model how to reason in a continuous latent space. We’ll use the following figure from the paper, which shows the stages of the training procedure.

The researchers leverage existing language Chain-of-Thought data, where each sample consists of a question, reasoning steps, and the final answer. At stage 0, the model does not generate any thought tokens, and is just trained to yield the reasoning traces and correct answers for the Chain-of-Thought samples. In the subsequent stages, at each stage, we remove one reasoning step from the sample, and instead add thought tokens. In the illustration above, a single thought token is added in each stage, instead of a single reasoning step, but this is controlled by a hyperparameter ‘c’.
On each of these stages, the loss is only calculated on the remaining reasoning steps and the answer, not on the thought token. The proposed continuous thoughts are fully differentiable, allowing for back-propagation. Multiple forward passes are performed when multiple latent thoughts are scheduled in the current training stage, computing a new latent thought with each pass and finally obtaining a loss on the remaining text sequence.
An important note is that the loss objective does not encourage the continuous thought to compress the removed language thought, but rather to facilitate the prediction of future reasoning. Therefore, it’s possible for the model to learn more effective representations of reasoning steps compared to human language.
Switching From Thoughts Generation to Word Tokens Generation
How does the model determine when to switch from latent thought mode to language mode? The researchers explored two strategies. The first strategy involved letting the model decide using a binary classifier on the latent thoughts. The second strategy used a constant number of latent thoughts. Since both strategies provided comparable results, the researchers opted for using a constant number of thoughts for simplicity.
Experimental Results
Let’s now review some of the results presented in the paper using the following table, which shows a comparison of the Coconut method with a few baselines on three datasets: GSM8K for math, ProntoQA for logical reasoning, and ProsQA, a dataset constructed for this paper which requires stronger planning ability.
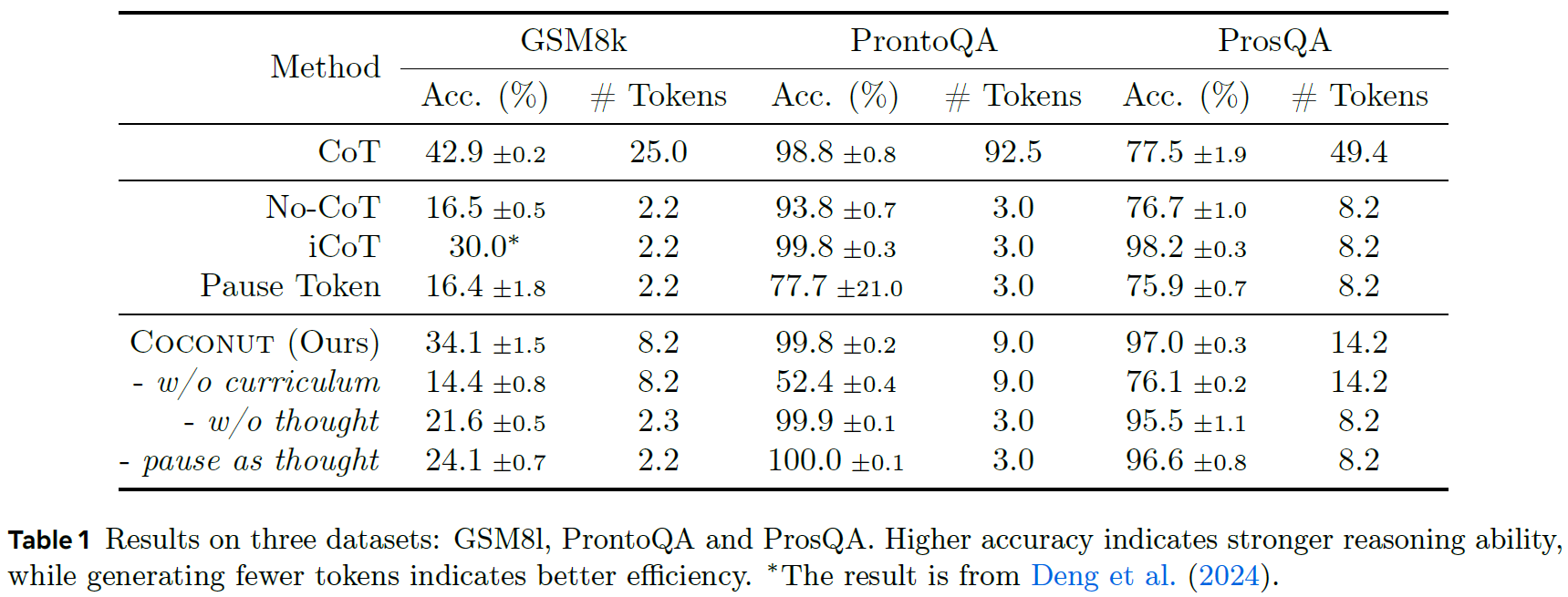
First, looking at Coconut results compared to No-CoT, which is a version of the LLM that tries to directly yield an answer without reasoning traces, we can see that continuous thoughts significantly enhance reasoning capabilities, since Coconut performs significantly better on all three datasets.
Comparing to CoT, we see that CoT is better on math, but Coconut is significantly better on ProsQA which requires strong planning. We’ll dive deeper into this in a moment. It is also worth mentioning that CoT requires generating many more tokens compared to Coconut which makes Coconut more efficient.
Another recent baseline which also tries to internalize the reasoning process in a different manner is i-CoT. We can see that Coconut achieves better accuracy on math while being comparable for the other two datasets. However, i-CoT requires generating fewer tokens.
One especially interesting result from the ablation studies is the first one, which is labeled as “w/o curriculum”. It shows the importance of the multi-stage training. The model in this version is trained only with samples from the last stage of the training, that include just the question and the answer, where the model needs to solve the whole problem using continuous thoughts. The results for this version are significantly lower.
BFS-like Reasoning
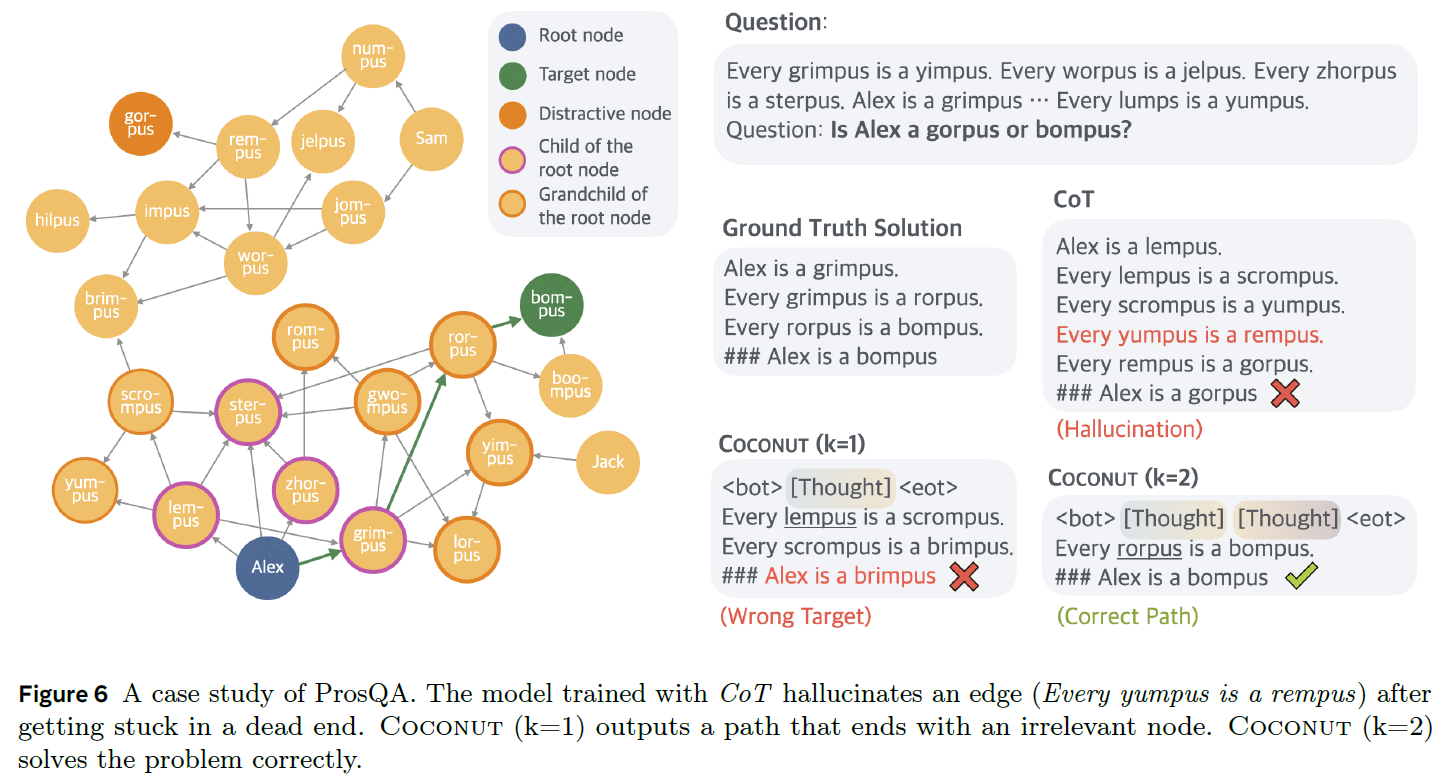
An interesting observation in the results is the benefit of latent reasoning for planning-intensive tasks. All versions that use some form of latent reasoning perform better than CoT on the ProsQA dataset, which requires more complex planning compared to the other two datasets.
The above figure from the paper shows a case study from the ProsQA dataset. At the top right, we see the question, which establishes various relationships and asks about a connection that can be deduced from these relationships. On the left, we see a graph built from the relationships defined in the question, where there is an edge for every ‘is-a’ relationship.
The specific question is whether Alex is a gorpus or a bompus. The ground truth requires two steps of reasoning to provide the final answer, which is bompus. This can be deduced by performing a graph search from the Alex node, reaching the target node, bompus, in two steps.
With chain-of-thought reasoning, the model hallucinated an edge that does not exist, leading to the wrong answer. We can also see that using the Coconut method with one thought token yielded an incorrect result, but when using two thought tokens, the model got it right. A possible explanation for this is that the thought tokens allow the model to explore multiple possible branches before committing to a specific path, whereas chain-of-thought reasoning chooses a direction from the start. This ability is somewhat similar to Breadth-First Search (BFS).
Conclusion and Future Directions
Let’s now wrap it up with a conclusion and a few possible future directions. First, the Coconut method significantly enhances LLMs reasoning. We saw this when comparing the results to the No-CoT version. Second, latent space reasoning allowed the model to develop an interesting BFS-like reasoning pattern, which helped it perform better on planning-intensive tasks.
Looking forward, there are various interesting directions for future research. One possible direction is pretraining large language models with continuous thoughts, rather than starting with a standard pretrained model. Another direction is optimizing the efficiency of Coconut to better handle the sequential nature of multiple forward passes. Lastly, combining latent thoughts with the standard chain-of-thought, rather than replacing it, might allow gaining the benefits of both approaches. Though this would require more inference steps.
Reference & Links
- Paper page
- Video
- Join our newsletter to receive concise 1 minute summaries of the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.
