Introduction
In recent years, we’ve witnessed tremendous progress in AI, primarily due to the rise of large language models (LLMs) such as LLaMA-3.1. To further enhance LLM capabilities, extensive research focuses on improving their training processes. In this post, we review a recent research paper by Stanford University and SynthLabs that suggests a potential improvement, which may significantly advance AI. The paper is titled “Generative Reward Models”, authored by some of the same individuals behind the widely-used DPO method.

LLM Training Process
Before diving to Generative Reward Models (GenRMs), let’s do a quick recap for how large language models are trained.
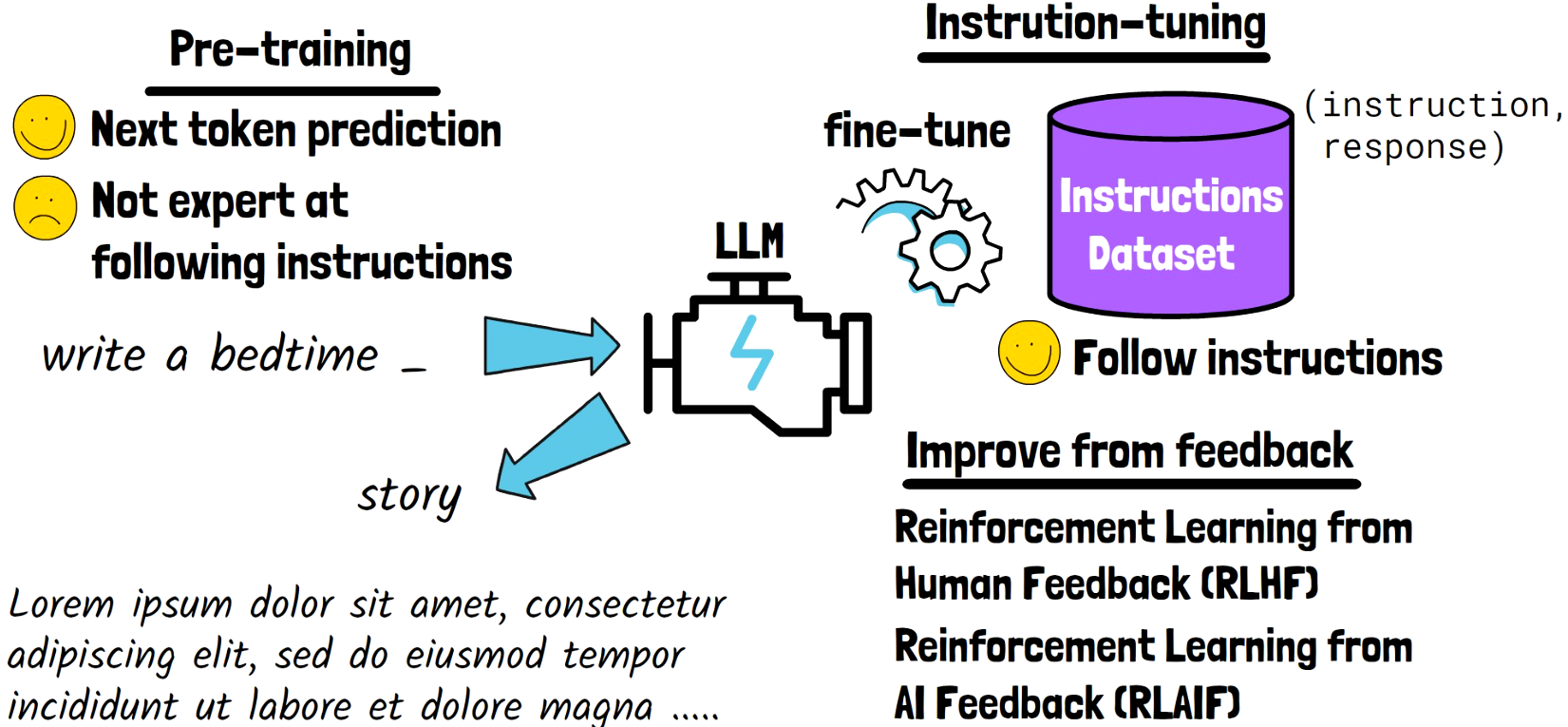
Pre-training Stage
LLMs are first pre-trained on huge amount of text, to learn general purpose knowledge. This step helps the LLM to be good at predicting the next token in a sequence, so for example given an input such as “write a bedtime _”, the LLM would be able to complete it with a reasonable word, such as “story”. However, after the pre-training stage the model is still not good at following human instructions. For this reason, we have the instruction-tuning stage.
Instruction-tuning Stage
In this stage, we fine-tune the model on an instructions-dataset, where each sample from that dataset is a tuple of an instruction and a response, which we use as the label. After this step, the model is good at following instructions.
Improving From Feedback
In practice, LLMs continue being improved after the instruction-tuning stage, using feedback. A strong method of doing that is Reinforcement Learning from Human Feedback (RLHF), where the model is trained on human feedback. Due to the challenge of gathering such feedback, we also have Reinforcement Learning from AI Feedback (RLAIF).
RLHF & RLAIF
The paper we review today, is related to this final stage in the LLM training process of improving the model using feedback, so let’s expand our background a bit deeper about this phase.
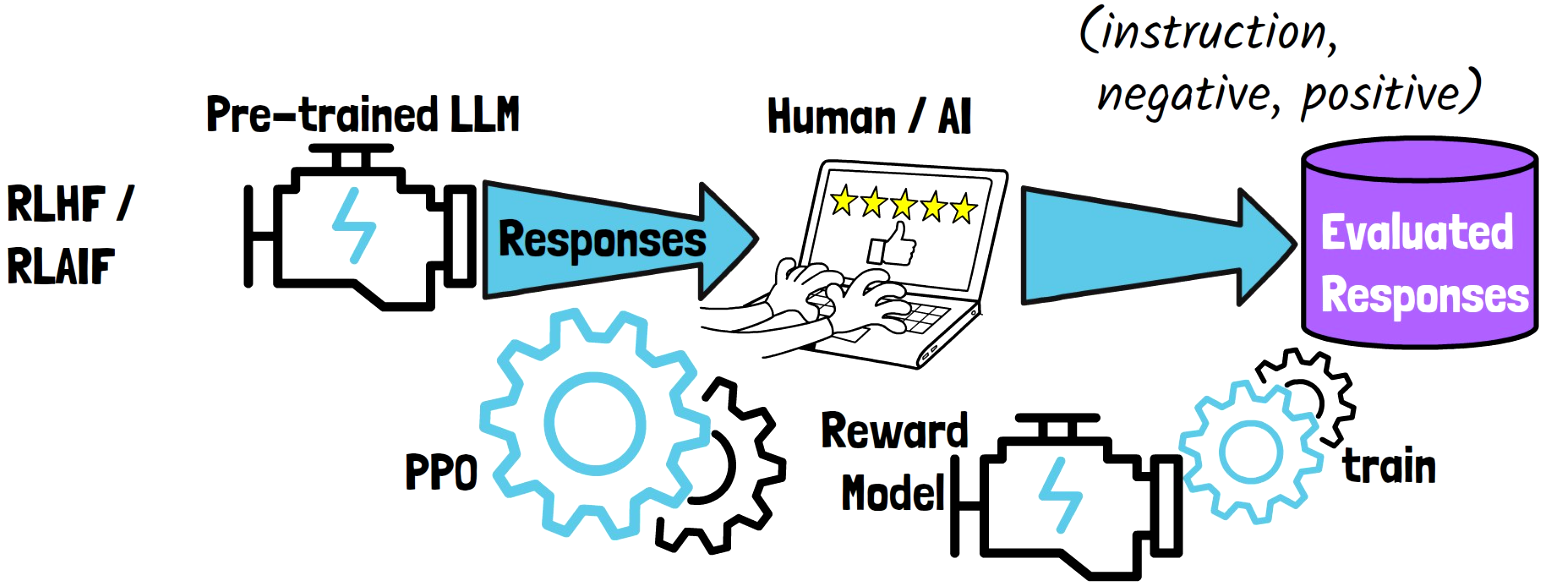
Creating a Feedback Dataset
With reinforcement learning from either human feedback or AI feedback, we have a pre-trained large language model, which we use to generate responses. The responses are then evaluated by human or by a different model, in order to produce a dataset of evaluated responses, where each sample has an instruction, a negative response, and a positive response.
Reinforcement Learning
Using the feedback dataset, we train a reward model, that learns to rank the LLM responses. Then, the LLM is trained using the reward model, mostly via PPO, in order to yield outputs with high ranking.
Is a Reward Model Always Needed?
More recently, Direct Preference Optimization (DPO), was introduced, with shared authors with the paper we review here. With DPO, the need for the reward model is removed, meaning we train the LLM using the feedback data directly, without creating a reward model. However, based on recent research, solely relying on methods such as DPO, without a reward model, may not yield the best performance. So, for example LLaMA-3 is using a hybrid approach of both DPO and reward-model-based learning.
Generative Reward Model Goals – Goals
Generative reward models paper suggests a unified framework for RLHF and RLAIF, to tackle two main limitations:
- Reward models struggle with out-of-distribution data. Meaning that they do not generalize well when encountered with input types that were not part of their training feedback data.
- AI feedback may not always align well with human feedback.
Generative Reward Models Training – Phase 1
In the first phase, we begin with a LLM, that we want to act as a reward model, and we train it on a dataset of human feedback. However, it is different than previous reward models since the reward model that we train is generative, unlike previous reward models. We expand on this difference in the following section.

What are Generative Reward Models?
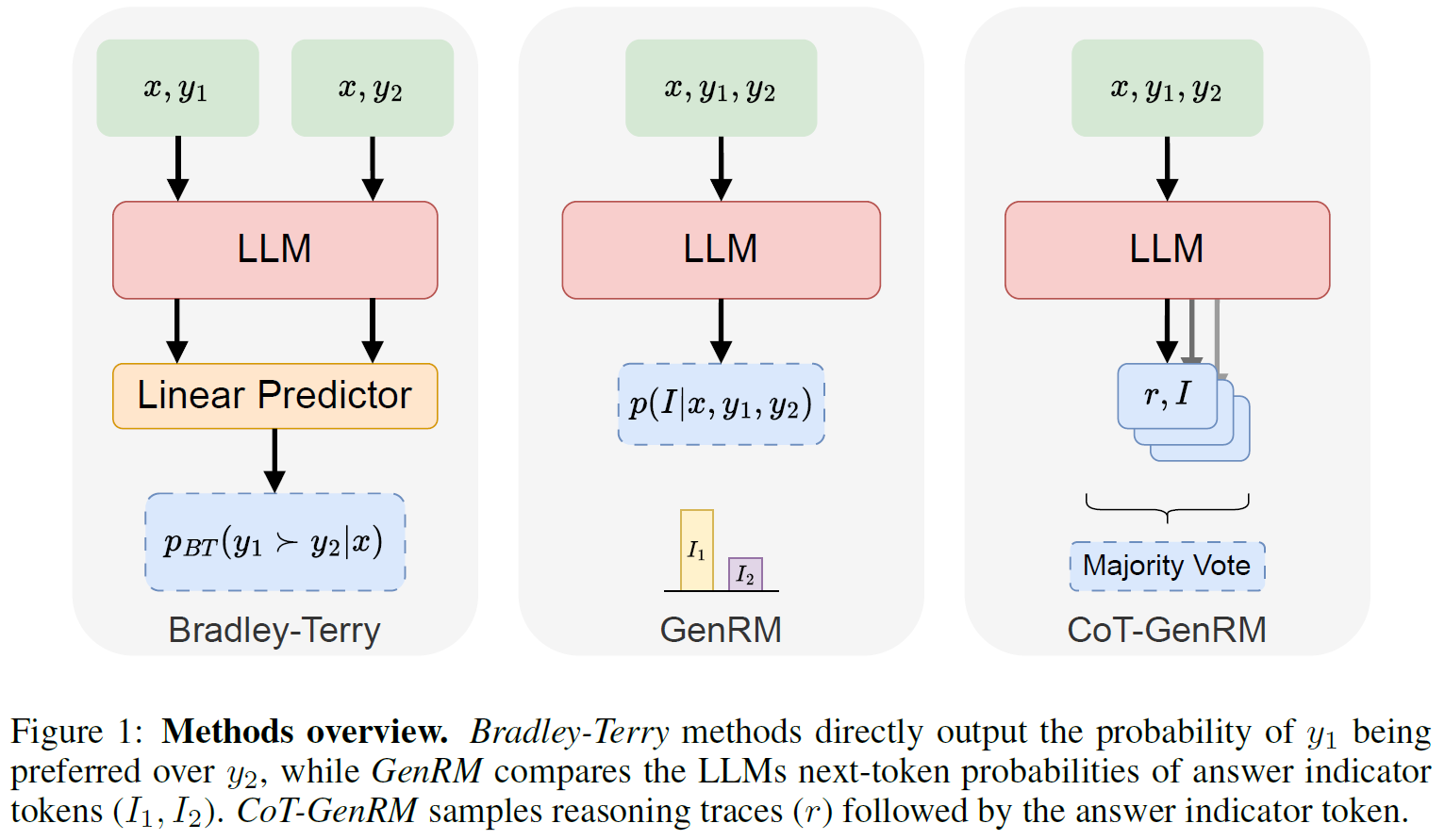
In the above figure from the paper, we can see how generative reward models work, comparing to Bradley-Terry reward models which represent the standard reward models prior to this paper.
- Bradley-Terry – The input is an instruction, and two possible responses as input. In addition to the LLM, it has an additional linear predictor head to directly return the probability that one response is better than the other.
- GenRM – The input also includes an instruction and two possible responses, but here we do not have an additional head. Instead, the model should generate an answer indicator token that represents the preferred response. So, we have the probability to generate an indicator token for each of the responses, and we prefer the one with the higher probability.
- CoT-GenRM – A Chain-of-Thought version of GenRM. As the name implies, in this case, rather than generating only an indicator token for the preferred response, the LLM is instructed to provide reasoning for the decision, in addition to the indicator token. To choose the final preferred response, we may sample few reasoning traces and answers and decide using a majority vote.
Generative Reward Models Training – Phase 2 (STaR)
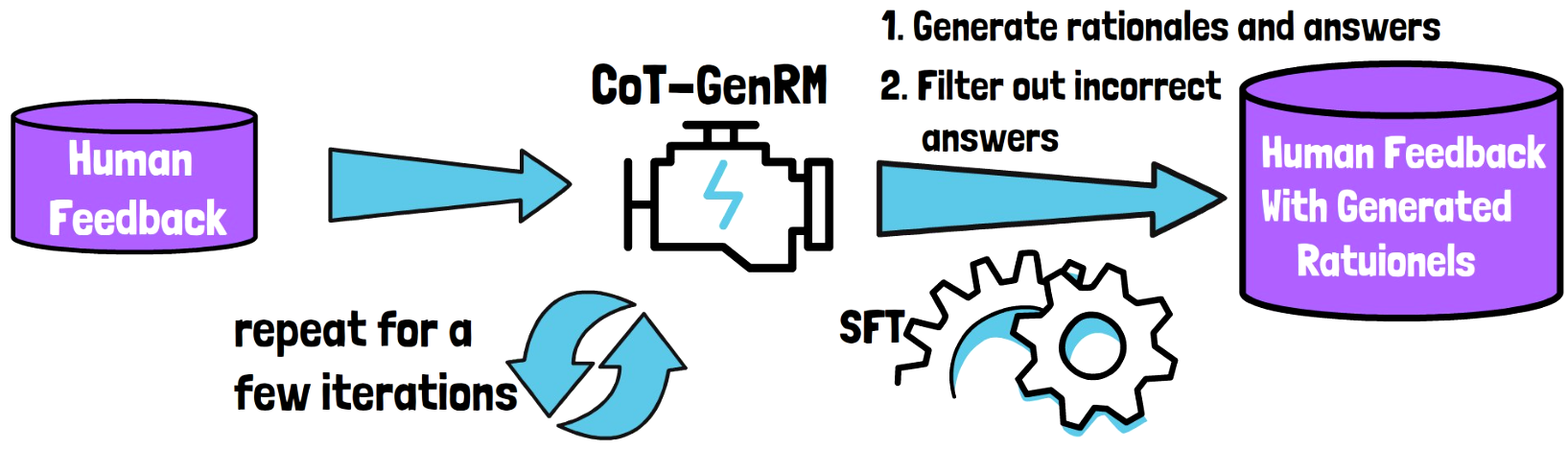
We now have a generative reward model which was trained on a human feedback dataset, and we continue to improve the model in iterations using a method called Self-Taught Reasoner (STaR). The way it works is the following:
- Generate Rationales – We prompt the model with inputs from the human feedback dataset, to determine the correct responses and also to generate rationales for the decisions.
- Rationales Filtering – Then, we filter out reasoning traces that did not lead to a correct responses, according to the labels from the human feedback dataset. This process provides us with a new dataset with reasoning trace.
- Supervised Fine-tuning – The model is then trained on the new dataset via a supervised fine-tuning process.
- Repeat – We then repeat the process for a few iterations. We refer to the trained model as CoT-GenRM-STaR.
What About Samples That Were Filtered Out?
There are samples from the human feedback dataset which we did not use in the process above, in case the model was not able to determine the correct answer. In order to use these samples as well there are two suggested methods:
- Post-Rationalization – Here we generate reasoning traces for these samples as well, but provide the model with the correct result as a hint, just asking it to create the reasoning for a known result. Then, we can enrich the dataset we use in each iteration. We refer to the trained model using this approach as CoT-GenRM-STaR-Rationalizer.
- Mistakes Dataset – Here we use the rationales that lead to wrong judgments as another dataset, with the wrong judgments, and use a DPO-like loss to punish the model for such samples. We refer to the trained model using this approach as CoT-GenRM-STaR-DPO.
Results
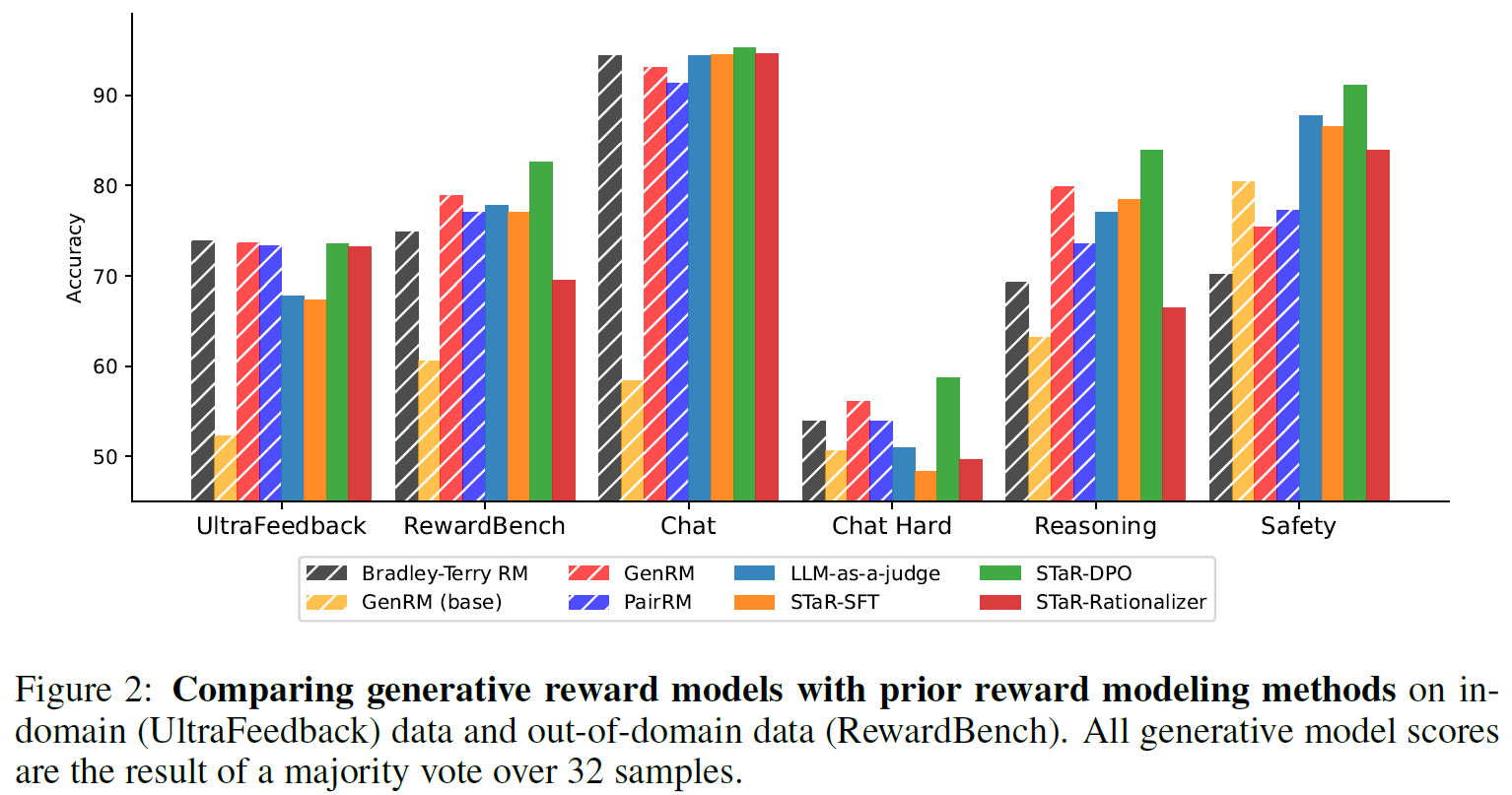
In the above figure, we can see a comparison between different version of generative reward models, and prior reward modeling methods on the UltraFeedback dataset and RewardBench, where the rest of the results to the right of RewardBench are subsets of the RewardBench data grouped by categories.
- In-distribution Data – The results on the UltraFeedback dataset represent in-distribution data. We see that few generative reward model versions are competitive with the Bradley-Terry reward model.
- Out-of-distribution Data – The results on RewardBench represents out-of-distribution data. We can see the STaR-DPO (which is the CoT-GenRM-STaR-DPO mentioned earlier) is significantly better than Bradley-Terry, so the generative reward model was able to generalize better for out-of-distribution data.
References & Links
- Paper page
- Video
- Join our newsletter to receive concise 1 minute summaries of the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.