
Motivation
In recent years we witness remarkable advancements in AI and specifically in natural language understanding, which are driven by large language models. Today, there are various different LLMs out there such as GPT-4, Llama 3, Qwen, Mixtral and many more. In this post we review a recent paper, titled: “Mixture-of-Agents Enhances Large Language Model Capabilities”, which presents a new method, called Mixture-of-Agents, where LLMs can collaborate together as a team, and harness the collective expertise of different LLMs. So, instead of using a single LLM to get a response, we can get a response that is powered by multiple LLMs. Using this method the researchers were able to achieve state-of-the-art performance on AlpacaEval 2.0 and surpass GPT-4o by a significant margin.
Before diving in, if you prefer a video format then check out the following video:
The Mixture-of-Agents Method
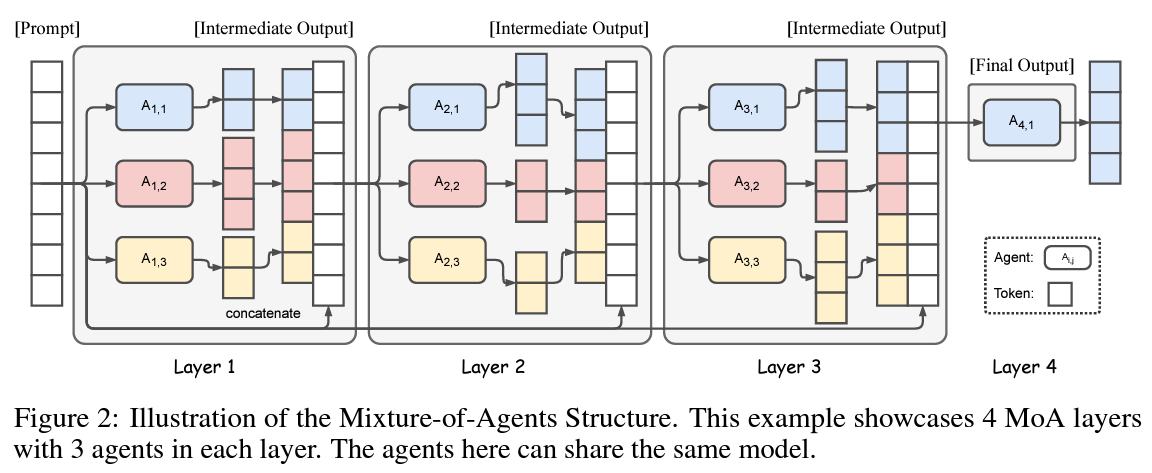
To understand how the Mixture-of-Agents method work we use the above figure from the paper. Mixture-of-Agents is combined from multiple layers. On the left we have an input prompt, which is first being fed into the first MoA layer. Each layer has multiple LLMs. In this example we have 3 LLMs, each marked with capital letter A. A1,1 for the first LLM in the first layer, A1,2 for the second LLM in the first layer and so it goes. Each LLM gets the input prompt and yields a response. The responses from the LLMs in the first layer, together with the input prompt are passed to the second layer. The second layer also has 3 LLMs, which can either be the same LLMs from layer 1, or other LLMs. The second layer then operates in a similar manner to the first and pass results to the third layer, which in this example also has 3 LLMs. Then the results reach the final layer and we can see that there is only one LLM in this case. This LLM then gets the input prompt and additional responses gathered along the way from previous layers, and determines the final output. This method is inspired by the Mixture-of-Experts method, but here the experts being used are not parts of the same model but rather are full-fledged LLMs.
Generating The Final Response

The way that the last LLM determines on the final output is using a special prompt which the researchers call Aggregate-and-Synthesize prompt, which introduce intermediate responses already provided by LLMs, and asks the model to evaluate them and come up with a final response.
Results
Let’s now move on to see some of the results presented in the paper.
Previous Responses Help To Improve Performance
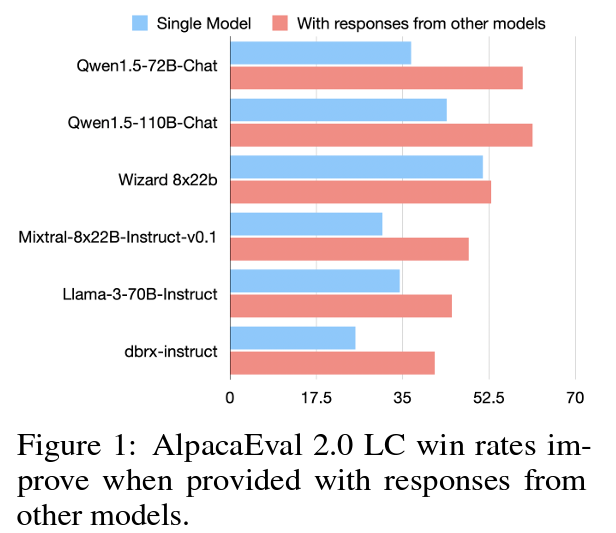
We see above the win rate on AlpacEval 2.0 for few models without using responses from other models in blue, and with responses from other models in red. The chart clearly shows that the models achieve higher win rate when considering responses from other models, while for some of them the gap is more significant than others. For example, we can see a large improvement for Qwen, but barely see a difference for Wizard.
Comparing Mixture-of-Agents to top models
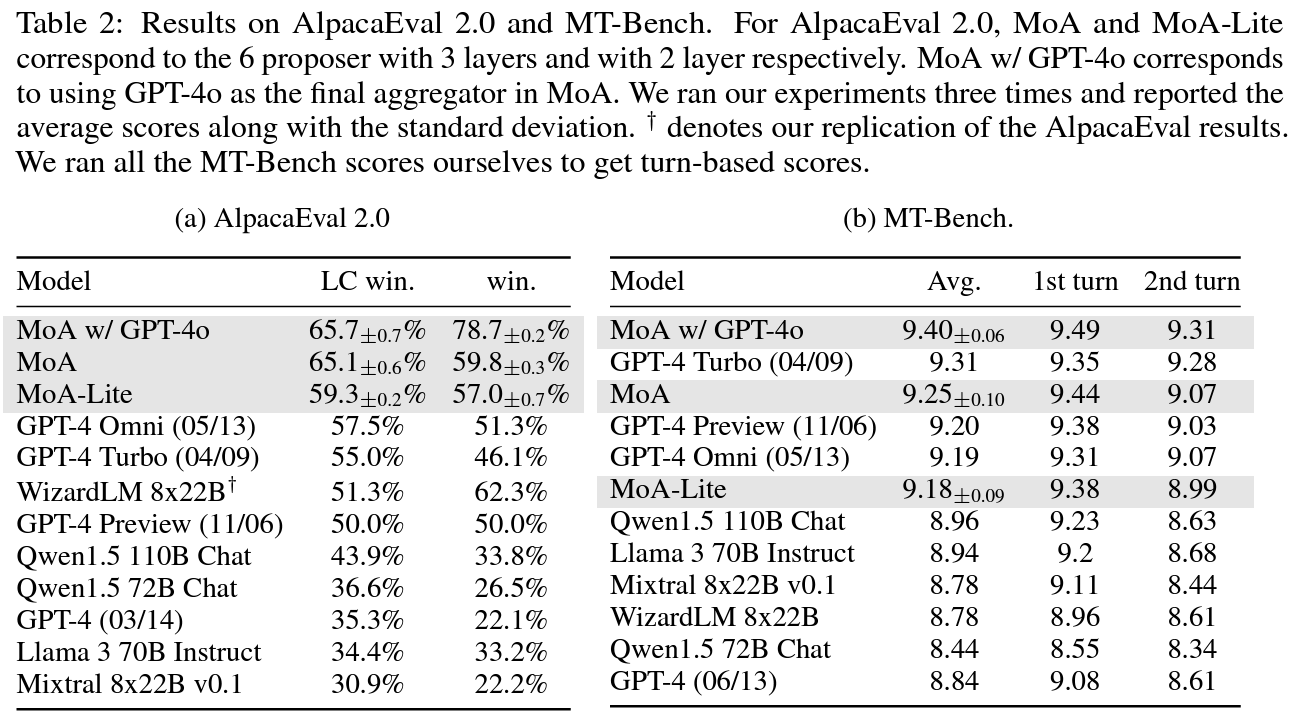
The above table from the paper shows comparison between top models to few MoA versions on AlpacaEval 2.0 and MT-Bench. We see on the left that on AlpacaEval 2.0, the MoA version that does not include GPT-4o surpass it by 8 points. This version is using Qwen1.5-110B-Chat as the final model. On the right for MT-Bench we can see that MoA does not win GPT-4 but is able to improve it, with a MoA version that includes GPT-4o as the final model in the MoA pipeline.
References & Links
- Paper page – https://arxiv.org/abs/2406.04692
- Video – https://youtu.be/Cf0Jidg-pDc
- Code – https://github.com/togethercomputer/moa
- Join our newsletter to receive concise 1 minute read summaries of the papers we review – https://aipapersacademy.com/newsletter/
All credit for the research goes to the researchers who wrote the paper we covered in this post.