Large Language Models (LLMs) have revolutionized AI, transforming how machines understand and generate human language. However, most LLMs still rely on traditional token-based pretraining, which has inherent limitations in complex reasoning tasks. Meta AI’s latest research paper, LLM Pretraining with Continuous Concepts, introduces CoCoMix (Continuous Concept Mixing), a novel framework designed to enhance LLM pretraining by integrating continuous concepts into the learning process.

Traditional LLM Pretraining
A key factor behind LLMs success is their massive training process, which includes a critical pretraining phase. During this phase, the model is trained on vast amounts of text with a simple yet effective objective: next-token prediction, where the model learns to predict the next word in a sequence.. For example, given an input like ‘write a bedtime _,’ the model learns to complete it with a reasonable word, such as ‘story’.
Introducing Continuous Concepts
While the traditional approach is effective for building strong language understanding and communication skills, it does come with limitations, particularly when tackling complex, long-horizon tasks. CoCoMix addresses these limitations by combining next-token prediction with continuous concepts.
Continuous concepts represent meaningful features within an abstract representation space, going beyond the constraints of discrete tokens. Their role is to supplement natural language tokens, with the goal to develop more advanced reasoning abilities and a deeper understanding of abstract ideas.
Let’s start with an overview of CoCoMix to get a high-level understanding of the approach, and afterwards we’ll dive into more details.
CoCoMix High-Level Overview
To illustrate CoCoMix’s approach, we first shortly describe standard LLM inference, and then explain how CoCoMix is different.
Standard LLM Inference
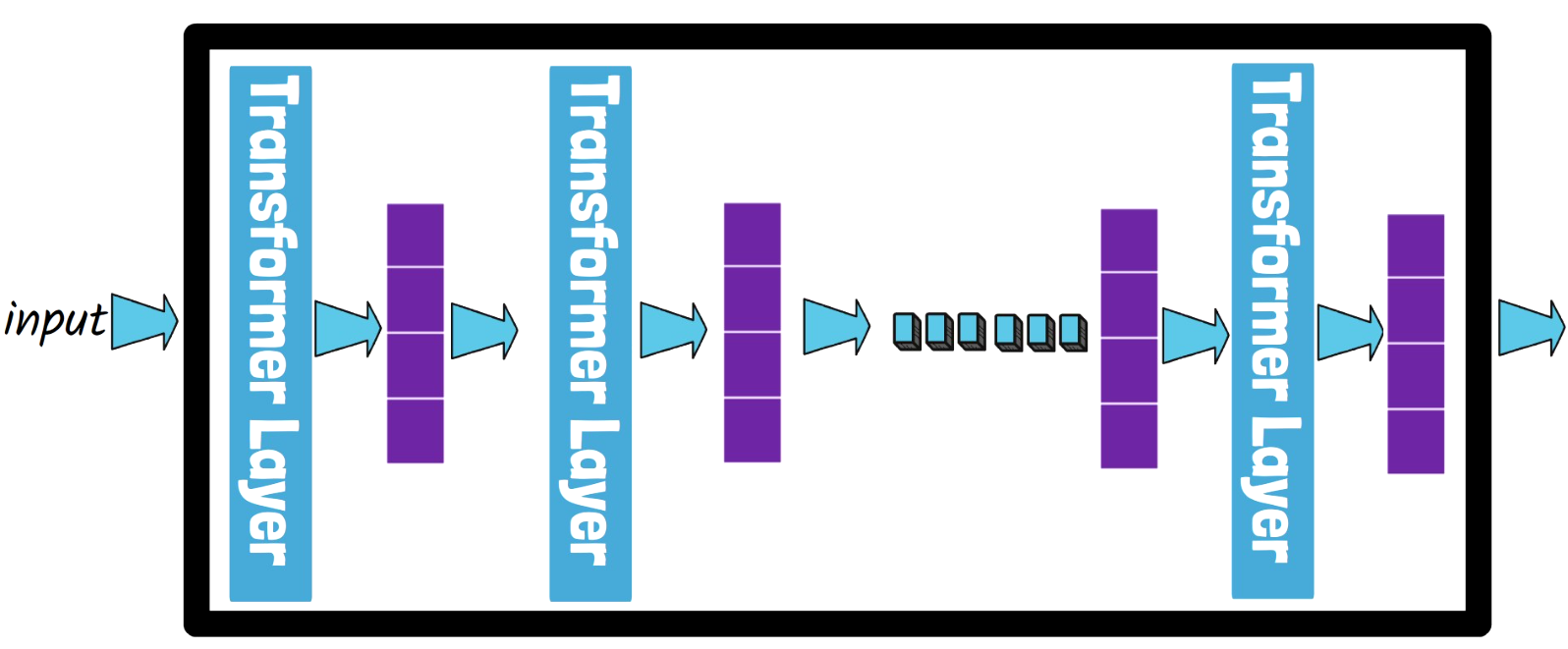
Given an input prompt (let’s assume it is already tokenized), a standard LLM, which is comprised of multiple Transformer layers, processes the prompt through all of the model layers, passing hidden states from layer to layer until finally the language prediction head predicts the next word token.
CoCoMix LLM Inference
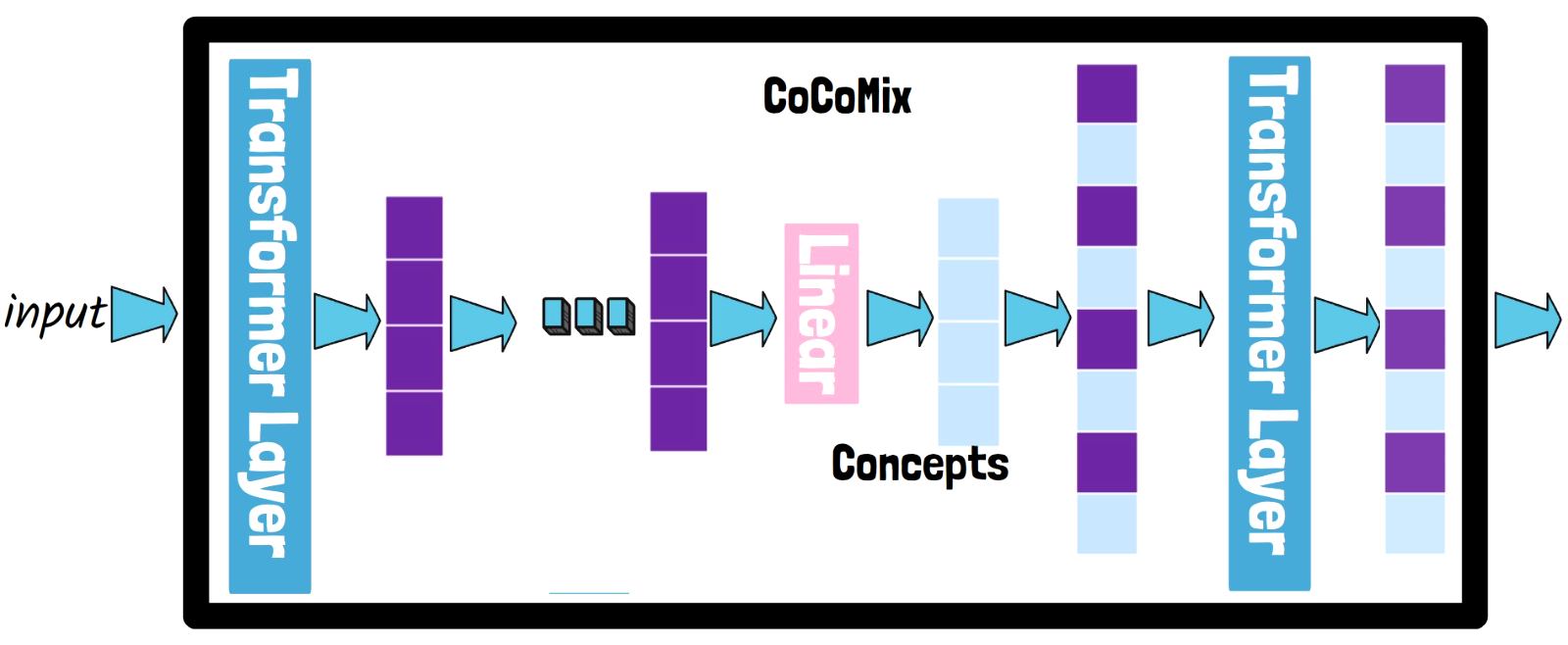
Comparing to a standard LLM, a model trained using CoCoMix adds an extra step. At one of the model layers, in a chosen depth, after obtaining the hidden states, the model uses an additional linear head to predict concepts. The predicted concepts are then mixed with the hidden states. These mixed representations are then passed to the following transformer layer, impacting all the remaining layers.
CoCoMix Training Process
Now that we have a high-level idea of where we want to get, let’s understand how the model is trained. How does the model learn to predict meaningful concepts and utilize them?
We use the following figure from the paper, which illustrates two phases.
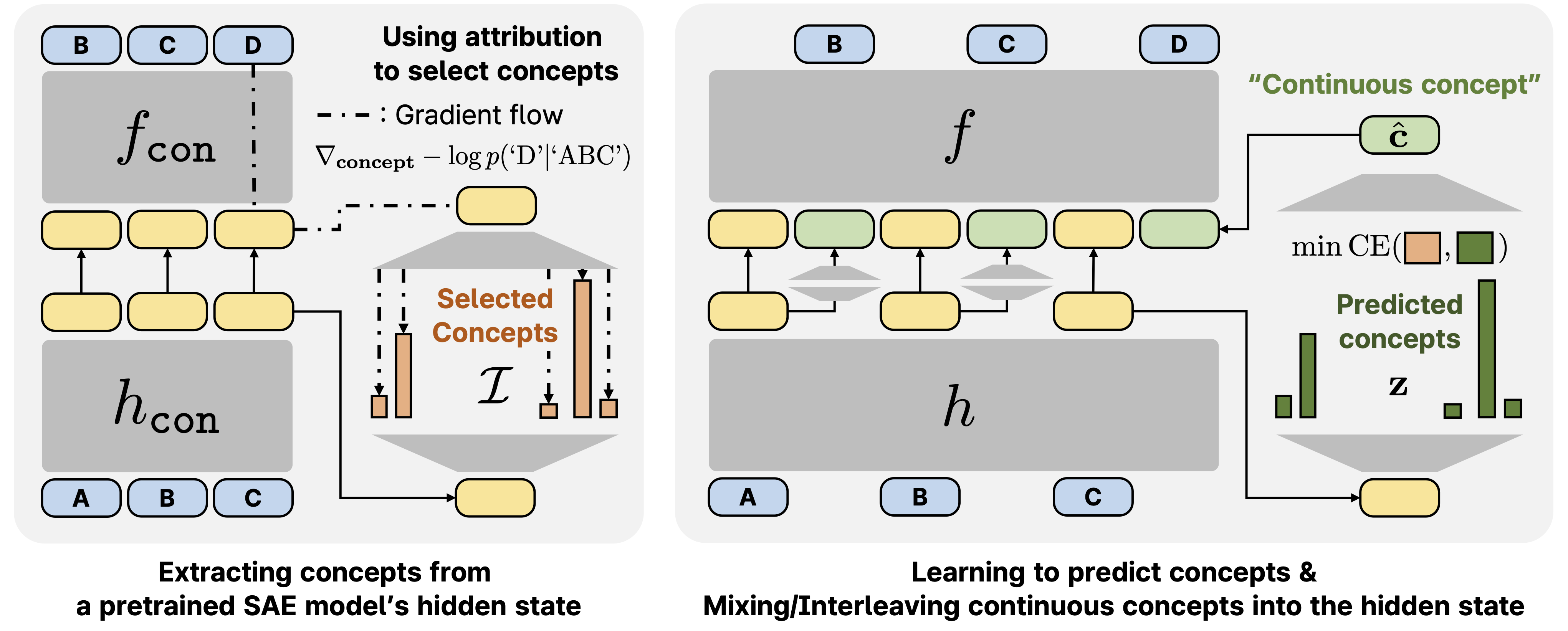
Phase 1 – Extracting Ground Truth Concepts
At the first phase (left side in the above figure), we extract ground truth concepts. These extracted concepts are used to teach the model how to predict concepts in the second phase.
Split a LLM Into Two Parts
At the bottom, we see an input sequence with three tokens, labeled A, B, C. This input sequence passes via a pretrained language model to generate the next token, D. The language model is conceptually split into two parts, h-concept and f-concept. You can think of this split as cutting the language model in the middle. The first part, h-concept, processes the input sequence and outputs hidden states, while f-concept continues the computation from those hidden states to generate the next token, D. The split is needed because the concepts are generated from the hidden state produced by the h-concept part of the model.
Semantic Representation Using a SAE
These concepts are supposed to encapsulate semantic information from those hidden states. To extract these semantic representations, a pretrained sparse autoencoder (SAE) is used. SAEs are built to extract meaningful features by encoding semantic representations from the input. They consist of two main components, an encoder and a decoder. The encoder encodes the semantic representation in the autoencoder’s latent space, and the decoder reconstructs the original input based on the encoded representation.
The sparse autoencoder must be trained to embed meaningful representations, and it should be trained using the same language model used for concepts extraction. In the paper, the researchers use GPT-2 as the pretrained language model, and a pretrained SAE that was trained using GPT-2.
The SAE used here is a TopK SAE. This means that only the top k activations in the encoder outputs are preserved, while the rest are zeroed out. In the paper, the encoder’s dimension is approximately 32,000, and K is 32, so only the top 32 activations are kept.
Selecting Meaningful Concepts
The extracted concepts represent the core features of the current input context. However, not all concepts are equally important for predicting the next token. Some may have little relevance, and we don’t want the model to learn to predict these less meaningful concepts.
To address this, CoCoMix uses an attribution score to select only the most meaningful concepts. The attribution score measures the influence of each concept on the output by multiplying the loss gradient with the input. Intuitively, it quantifies how much a change in the concepts affects the final prediction. Only the concepts with the highest attribution scores are kept and used as labels for training the model to predict concepts.
Now that we’ve established how concept labels are extracted, we’re ready to move on to the second phase, where the model is trained using these concept labels.
Phase 2 – Learn To Predict Concepts And Utilize Them
In this phase (right side in the figure), the model learns to predict concepts and use them for next-token prediction. As input, we have the same input sequence of tokens, A, B, C. Once again, the language model is split into two parts, h and f, but this time, it is not a pretrained language model but rather it is the language model that we want to train.
Concepts Prediction
The input sequence is first processed by h, which outputs hidden states. A new linear module then predicts the concepts from these hidden states. The predicted concepts are compared with the concept labels generated earlier by the SAE, and the model is trained to minimize the cross-entropy loss between the predicted concepts and the concept labels.
However, this is not the only training objective. The model also learns using the standard next-token prediction objective.
Next-token Prediction
Importantly, to predict the next token, the model now leverages the predicted concepts. Initially, the concepts are predicted in the concept latent space. To make them usable for the next-token prediction task, another linear module transforms these predicted concepts into what is referred to as the continuous concept. The continuous concept is then mixed with the sequence of hidden states and passes as input to f, the second part of the language model.
This process effectively doubles the size of the input sequence when transitioning from h to f, introducing some computational overhead. However, if the added concepts could significantly reduce the reasoning steps needed for the final model, it may not harm the model’s efficiency in practice.
Results
CoCoMix vs Next-token Prediction
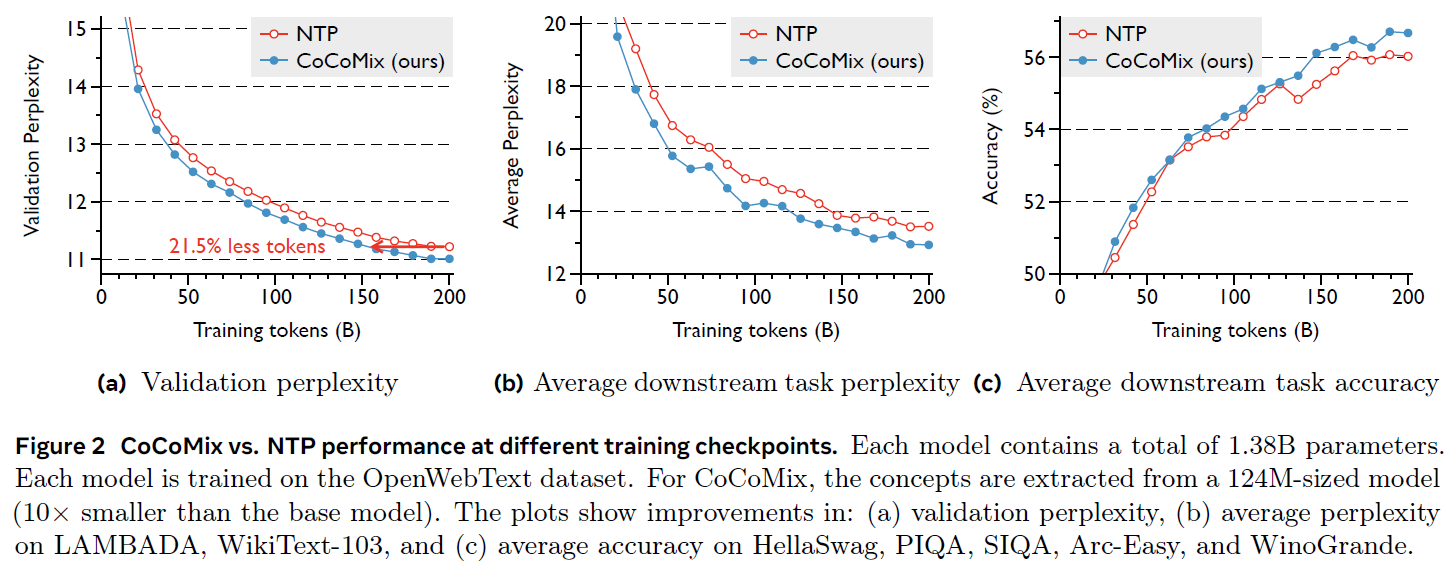
In the above figure, we see three charts that compare the performance of CoCoMix with a standard next-token prediction model. Both models have 1.38 billion parameters and were trained on 200 billion tokens.
The x-axis in all three charts represents the amount of training tokens. In the left and middle charts, the y-axis measures model perplexity, where lower values indicate better performance. CoCoMix results are shown in blue, and in both charts, it achieves lower perplexity than the baseline.
On the left chart, which measures perplexity on the validation dataset, CoCoMix reaches the same level of performance as the next-token prediction model while using 21.5% fewer training tokens. This demonstrates that CoCoMix is more efficient in utilizing training data.
The chart on the right shows the average accuracy, measured across multiple task benchmarks. Here, CoCoMix outperforms the standard next-token prediction model, achieving higher overall accuracy.
These results highlight the potential of CoCoMix to improve both the efficiency and effectiveness of LLM pretraining.
Interpretability and Steerability of CoCoMix

For interpretability, since the model is trained to predict concepts in its hidden state, we can analyze which concepts the model focuses on based on its concept predictions. Moreover, by amplifying the magnitude of a predicted concept, we can steer the output of the model to reflect that concept more clearly.
In the upper row of the above example, we see CoCoMix’s generations without steering any concept, alongside outputs where example concepts are amplified.
The researchers identified one particular concept that represents a site address. By amplifying the prediction of this concept, CoCoMix generates outputs that include a site address—something it did not produce without steering.
The bottom row shows the results of GPT-2, which was trained with the sparse autoencoder to amplify concepts in its representation space. Amplifying the same concept in both CoCoMix and GPT-2 triggers similar behavior. This alignment demonstrates that CoCoMix is consistent with the concepts learned by the sparse autoencoder.
Key Takeaways and Future Implications
- CoCoMix introduces continuous concepts into LLM pretraining, allowing models to capture higher-level reasoning and abstraction beyond token-based learning.
- It is more sample efficient , requiring fewer tokens to achieve similar or better performance.
- The model’s interpretability and steerability open intriguing possibilities for controllable text generation and enhanced explainability in AI.
References & Links
- Paper
- GitHub
- Join our newsletter to receive concise 1-minute read summaries for the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.
