Introduction
The industry is still getting used to the recently released DeepSeek-R1, which shocked the AI community. But, shortly after, DeepSeek has released another magnificent open-source model called Janus Pro. This time, it’s a multimodal AI model that rivals other top multimodal models.
In this post, we will explain the research paper behind DeepSeek Janus Pro, titled “Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling.” To understand this paper, we also need to explain the preceding paper by DeepSeek, which introduced an earlier Janus model version, titled: “JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation.” No prior knowledge is needed about the original Janus paper. The new paper builds on the previous one, and we’ll explain both in this post.


Unified Multimodal Understanding And Generation
Both models discuss unified multimodal understanding and generation, so let’s start with understanding what it means before we dive into the Janus model’s method details.
Image Understanding Tasks
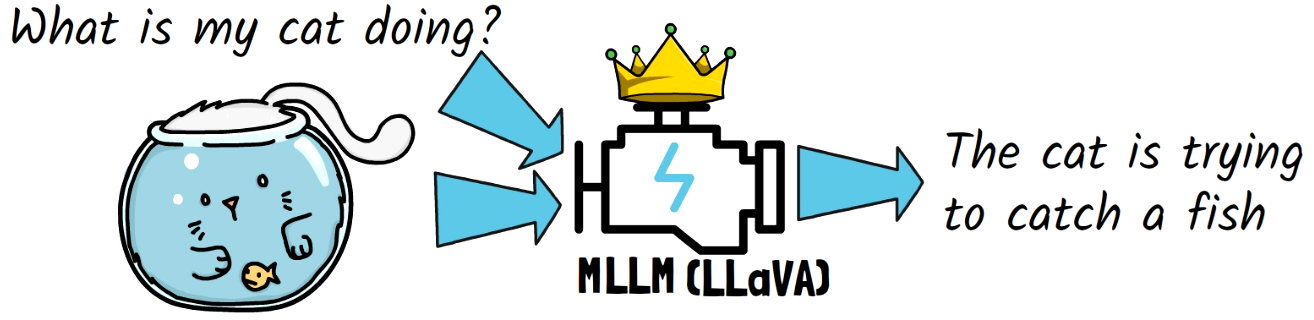
Large Language Models (LLMs) have demonstrated remarkable capabilities in many tasks. Building on that, Multimodal Large language Models (MLLMs), such as LLaVA, have been created. With MLLMs, we can feed the models both a text prompt and an image. In the above example, we ask the model “what is my cat doing?” and add an image of a cat. The model can then understand both the text prompt and the image, and tell us that the cat is trying to catch a fish.
This approach has proven quite effective for image understanding tasks, where the model can assist with answering various types of questions about an input image. Below, we can see an example from the Janus Pro paper for an image understanding task. Janus is asked about the background story of a cake that is provided as an image. Janus accurately detects that the cake theme is Tom and Jerry and provides its background story. Not only does the model understand the image, but it also leverages its backbone large language model to provide information beyond the image’s scope, using the general-purpose knowledge embedded in the LLM.
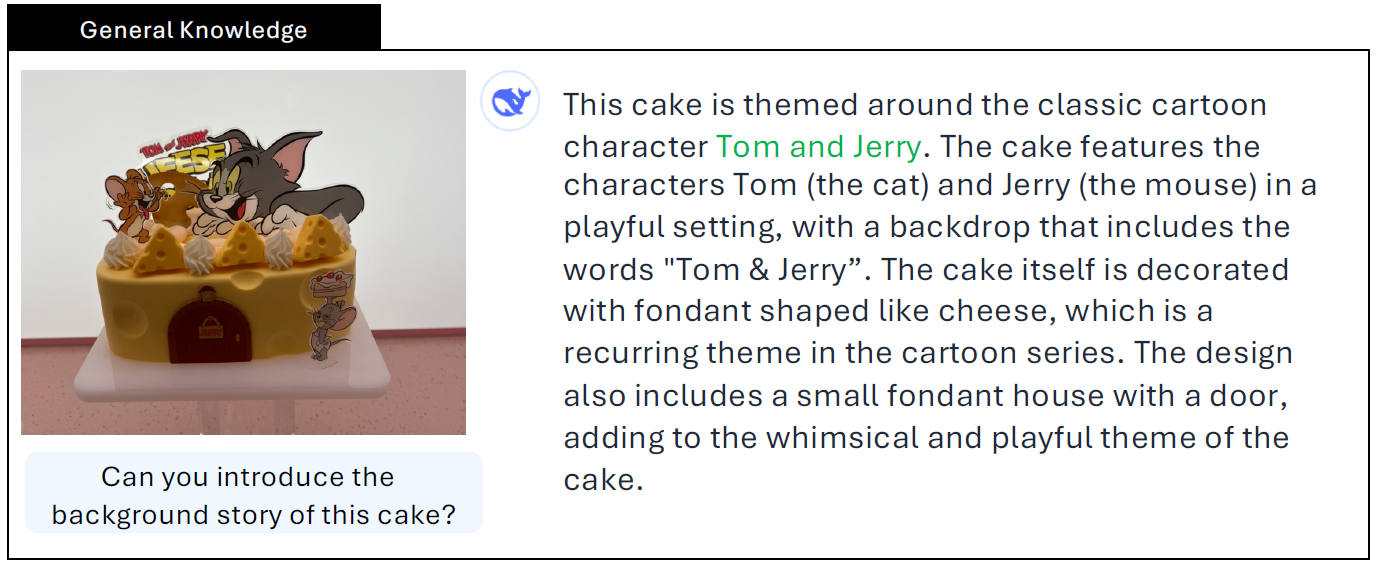
Image Generation Tasks
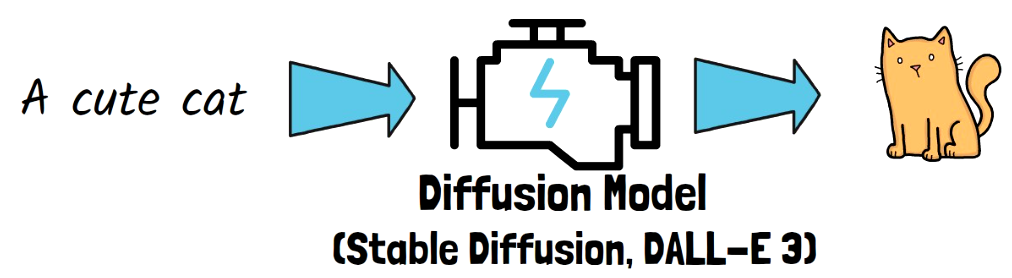
Image generation models are typically based on the diffusion models architecture, or its descendants. Known models include Stable Diffusion, DALL-E 3 and others, which have already shown remarkable capabilities in this domain. These models can take a text prompt, such as “a cute cat,” and generate a high-quality image.
Benefits of a Unified Model
We already have capable models for both image understanding and image generation. However, there are significant benefits to unifying these tasks into a single model. For instance, using one unified model saves the need to load different models’ weights when our application requires both types of tasks.
The Janus model we review today unifies the handling of both tasks within a single architecture. While Janus is not the first attempt to achieve this unification, we’ll explore what method makes Janus more successful when we review its architecture.
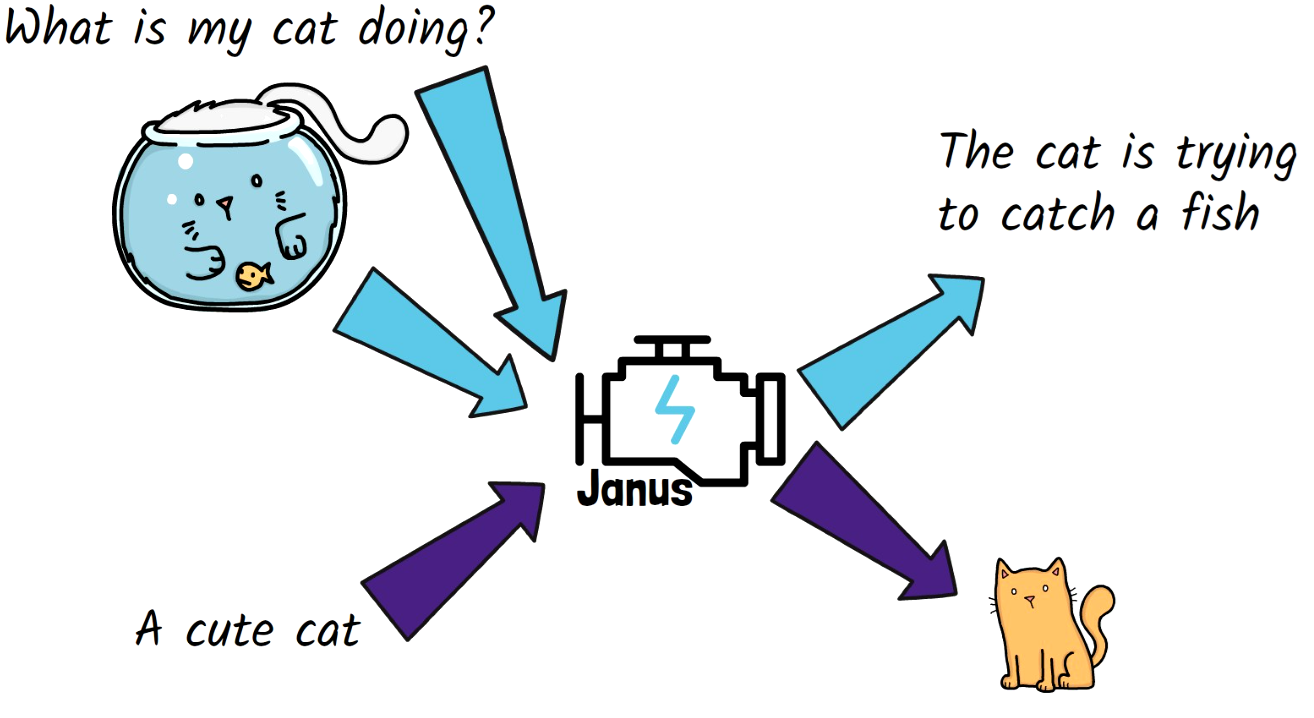
Janus and Janus Pro Architecture
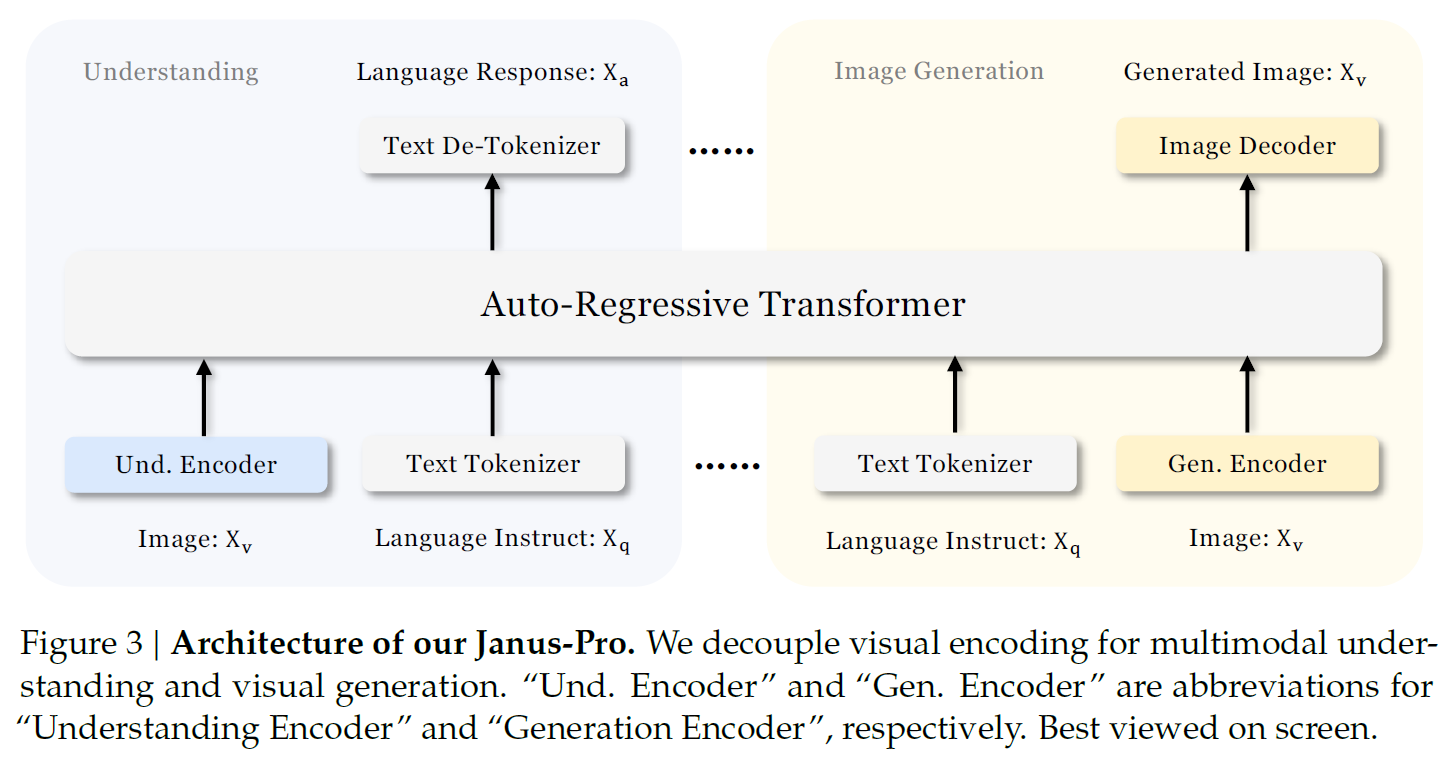
The architecture behind the original Janus model and JanusPro is similar, and we can learn about it using the above figure from the paper. At the core of the model, we have an Auto-Regressive Transformer, which is a LLM.
Janus Pro Main Design Principle
Other models that unify handling of multimodal understanding and generation typically use a single image encoder. However, DeepSeek researchers discover that the encodings needed for each type of task are different. As a result, this approach often suffers from task interference. Therefore, the main design principle in the Janus architecture is to decouple visual encoding for multimodal understanding and generation. This is achieved by utilizing different encoders for each type of task.
Janus Pro Image Encoders
For image understanding tasks, Janus uses SigLIP to encode images. SigLIP is an improved version of OpenAI’s CLIP model, which extracts semantic representations from images, making it suitable for understanding tasks. These representations are linearly mapped to the input space of the LLM.
For image generation, Janus uses an existing encoder from LlamaGen, an autoregressive image generation model. This is a vector quantization (VQ) tokenizer that converts an image to a list of IDs, each associated with a predefined vector. These vectors are mapped to the input space of the LLM using a trained module.
LLM Processing & Outputs
Text and image embeddings are concatenated to form the input sequence to the LLM. Text output for image understanding tasks is generated using the LLM’s built-in prediction head. For image generation, another head is added to the LLM to consume its last hidden state.
Rectified Flow

The image generation is performed using a rectified flow method. We don’t dive into rectified flow in this post, but to provide an intuition, think about how diffusion models work, starting from a noise image and gradually removing noise from the image until we get a clear cat image. Rectified flow tries to find shortcuts and reduce noise in a way that significantly reduces the number of steps needed to reach a clear image.
Janus Pro Training Process
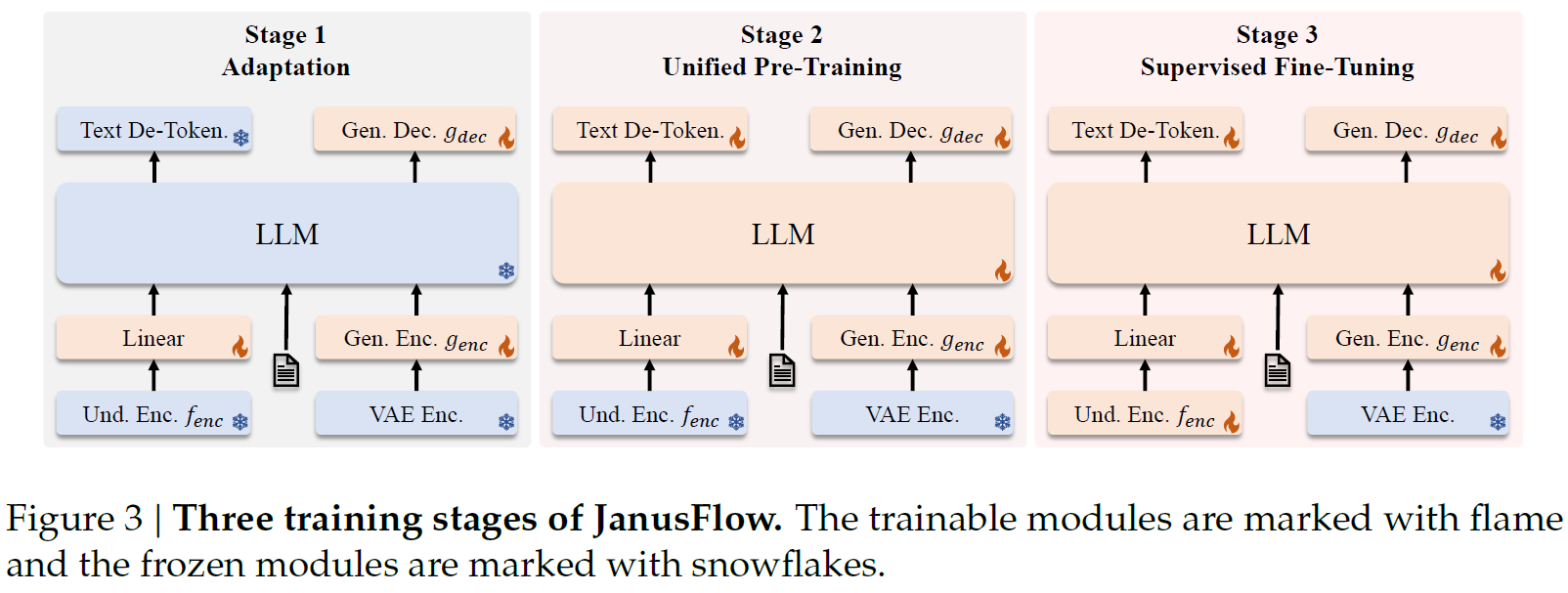
The above figure described the training process. It is taken from the original Janus paper and we’ll explain what is different for Janus Pro. Both Janus and Janus Pro are trained in three stages.
Stage 1 – Adaptation
The purpose of the first stage is to adapt the new modules to work properly with the pre-trained components. To do that, the weights of the LLM and the image encoders are frozen. Only the newly introduced components are trained. These components are the ones that map the encoded images to the LLM input space, and the image generation head. This stage trains the model on ImageNet, to generate images based on the image category. The training steps on ImageNet are increased for Janus Pro in this stage.
Stage 2 – Unified Pre-Training
In this stage, we continue to train the new modules, but now we also train the LLM and its built-in text prediction head, so it can better handle multimodal embedding sequences. The sample types included in this stage are multimodal understanding, image generation, and text-only data. The difference in Janus Pro compared to Janus is the removal of ImageNet from this stage. In Janus Pro training, text-to-image data is directly utilized, while in the original Janus model, this stage starts with ImageNet data and gradually increased the ratio of text-to-image data.
It is worth mentioning that the image encoder representations are aligned in training with the image generation latent output, to strengthen the semantic coherence in the generation process.
Stage 3 – Supervised Fine-Tuning
The third stage is supervised fine-tuning on instruction tuning data, which comprises dialogues and high-quality text-to-image samples. In this stage, the image understanding encoder is also trained, and there is no change in the process between Janus and Janus Pro.
Additional main changes in Janus Pro comparing to Janus are scaling up of the data size utilized in training, and the model size. For model size, the LLM was scaled up from 1.5 billion parameters to 7 billion.
Janus Pro Results
Understanding & Generation Comparison
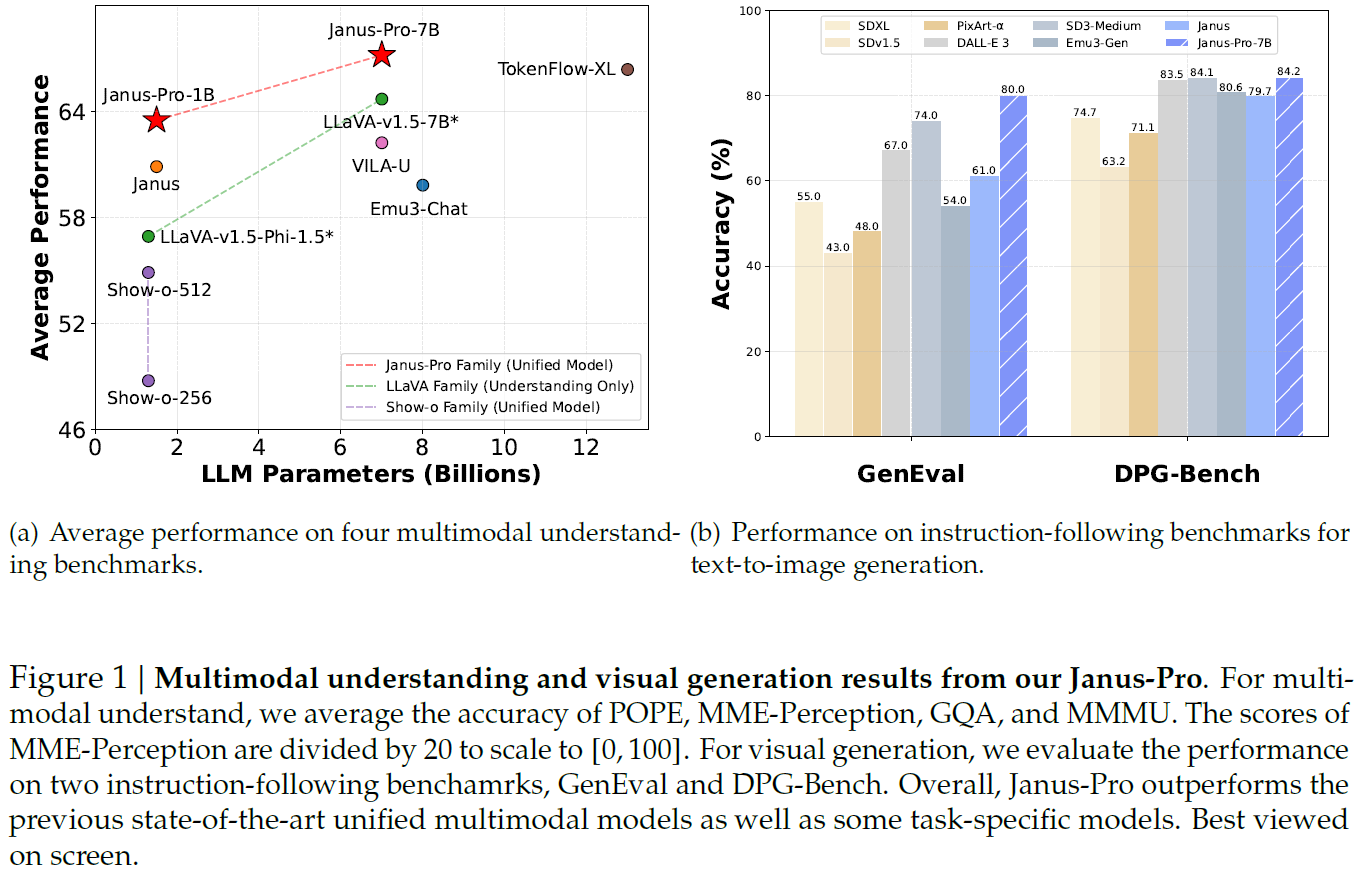
In the above figure, we can see performance comparisons of Janus Pro with other strong models. The left chart shows multimodal understanding results, where the x-axis represents the model’s size, and the y-axis represents the average accuracy across multiple benchmarks. Impressively, Janus-Pro-7B outperforms other top models, such as LLaVA. What makes it even more impressive is the fact that this is achieved using a unified model, while LLaVA models are not unified. JanusPro also significantly outperforms previous unified models and slightly outperforms the unified model TokenFlow-XL while being almost half its size.
The chart on the right shows text-to-image generation results on two benchmarks. Janus Pro outperforms top image generation-only models such as DALL-E 3 and SD3-Medium. It also outperforms the previous state-of-the-art results for image generation of unified models, which is not shown in this chart.
Janus vs Janus Pro Image Generation Quality

References & Links
- Janus Pro Paper
- Janus Paper
- Join our newsletter to receive concise 1-minute read summaries for the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.
